智能数据洞察(私有化)
智能数据洞察(私有化)






- 文档首页
 智能数据洞察(私有化)用户指南数据准备数据集数据集创建同步设置运行参数
智能数据洞察(私有化)用户指南数据准备数据集数据集创建同步设置运行参数

用户可通过设置运行参数,优化同步配置,保障同步任务成功率,提升任务性能。
2.1 常用使用场景
专业数据生产者,在创建数据集时,为同步任务设置合适的运行参数(资源相关)
普通用户在数据集同步任务失败时,通过查看诊断提示,设置合适的运行参数后重跑任务
2.2 使用入口
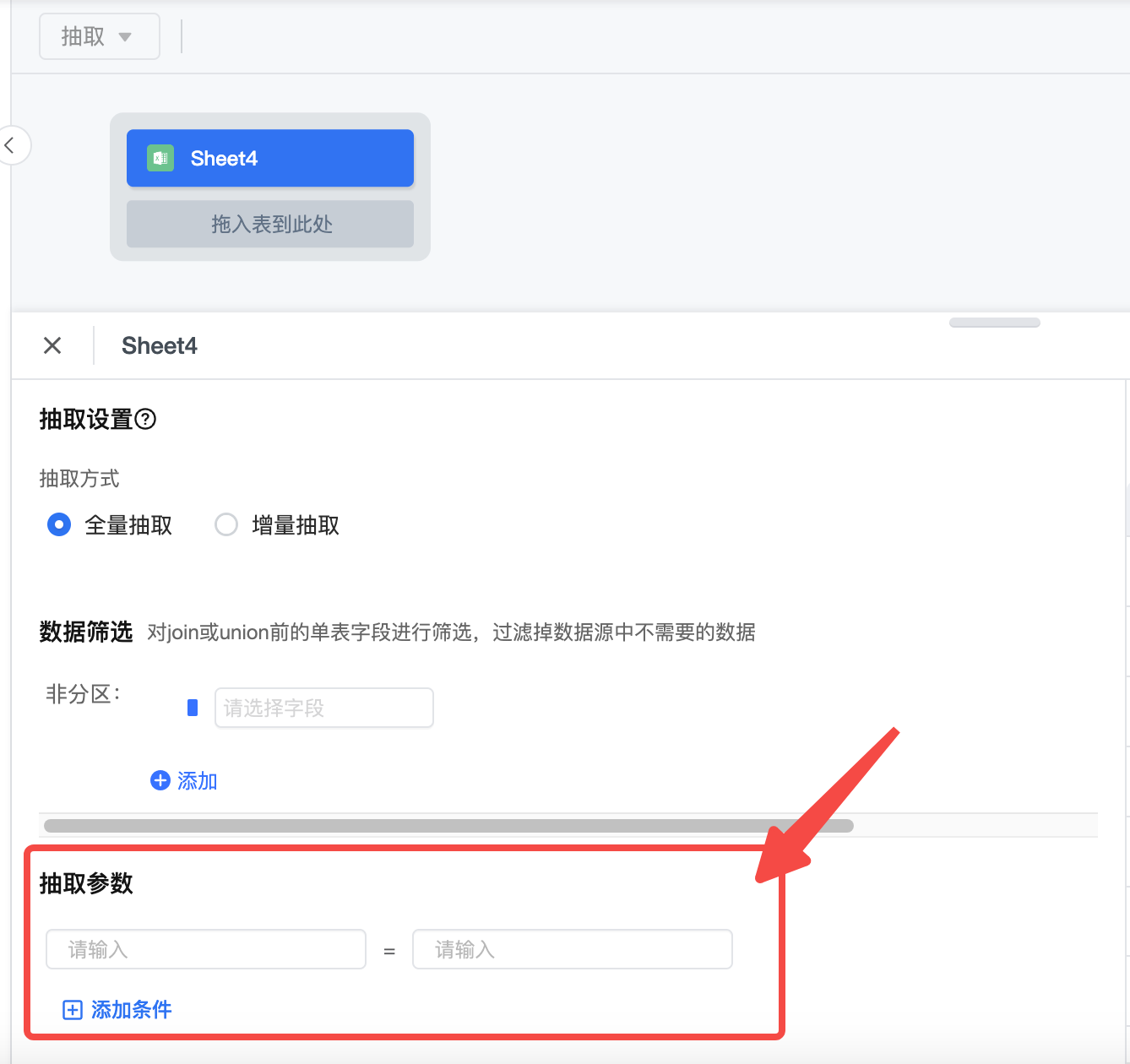
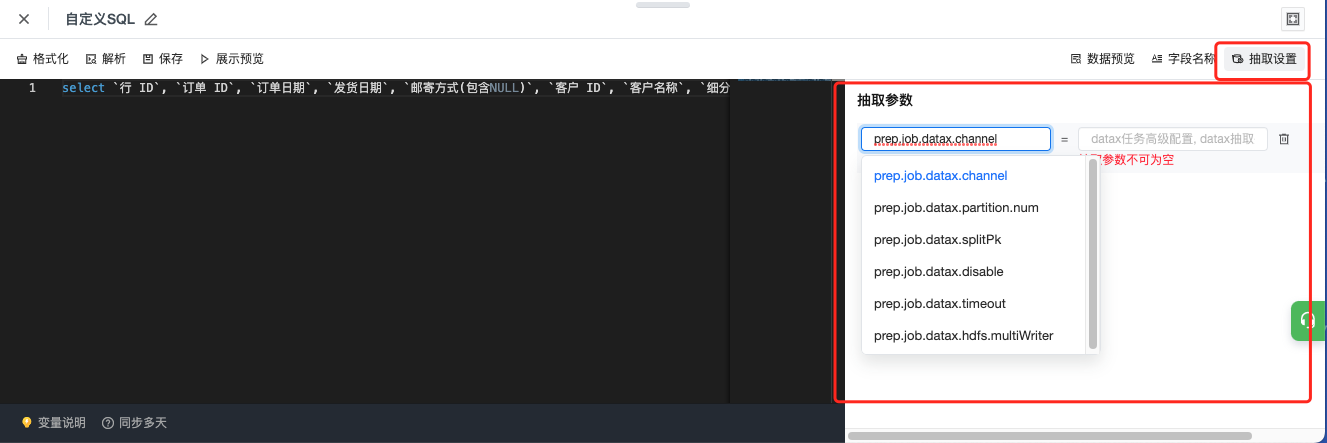
- 自定义 SQL 和表抽取设置可以配置抽取参数
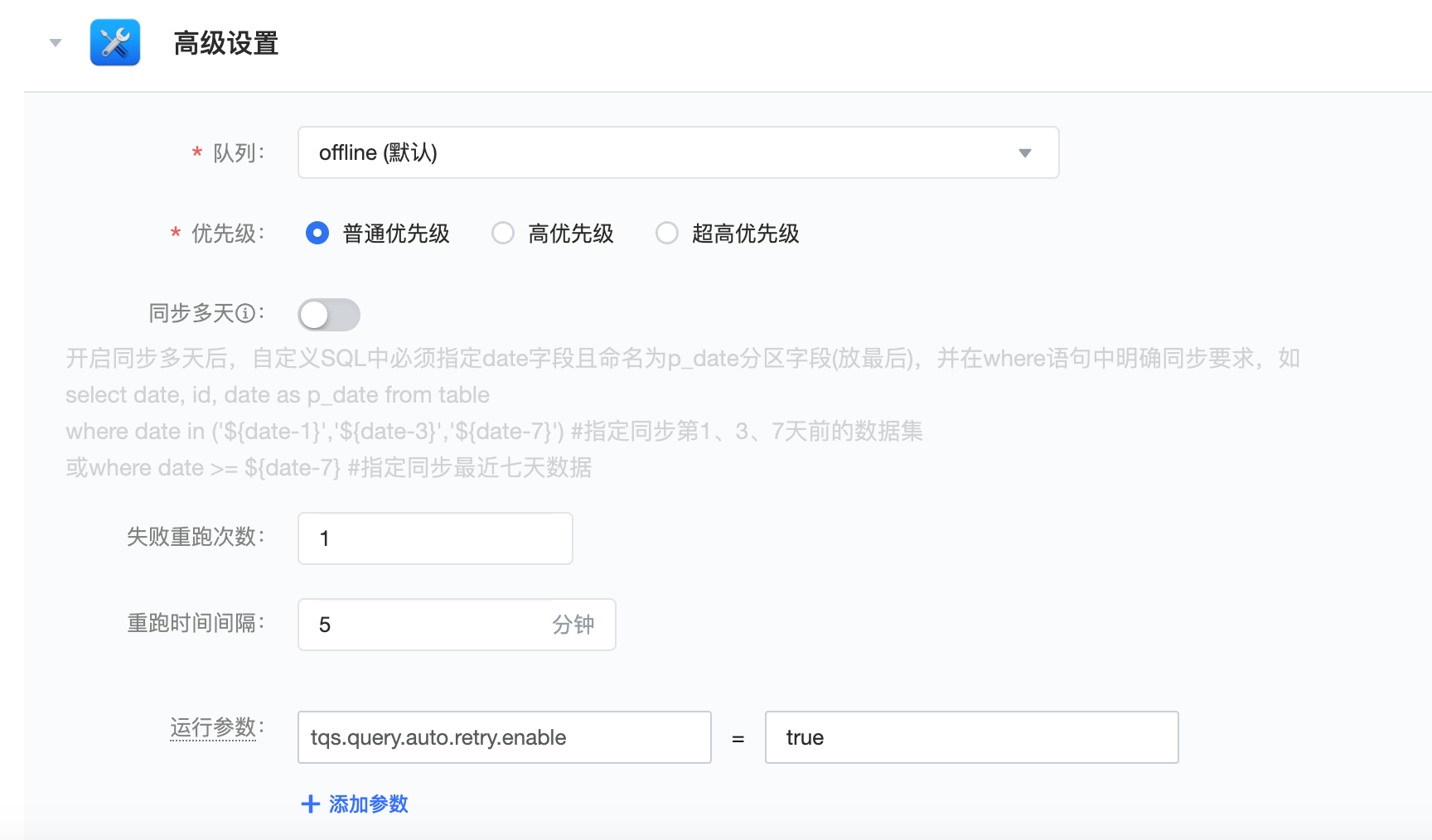
- 同步配置的高级设置中可以设置运行参数
3.1 抽取参数
抽取参数目前支持的数据源类型限制:Mysql、Clickhouse、Oracle、SQL Server、Maxcompute、Impala、Hive_jdbc、Redshift、LAS、Presto、Databricks
支持参数信息:
| 参数 | 说明 | 默认值 | 是否必填 | 建议值 |
|---|---|---|---|---|
prep.job.datax.channel | 读取并发数,需要和spiltPk协同使用 | 不开启(1) | 否 |
|
prep.job.datax.partition.num | datax数据抽取之后后续etl处理在spark引擎侧计算的partion数目; | 不开启(1) | 否 |
|
prep.job.datax.splitPk | 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,Datax因此会启动并发任务进行数据同步,这样可以大大提高数据同步的效能。 | 不开启 | 否 |
|
prep.job.datax.timeout | datax任务高级配置, MaxCompute数据源分区检测的等待超时时间, 单位分钟. 未配置的情况下, 查询的表分区为空时任务直接失败 | 不开启 | 否 | 不建议开启 |
| prep.job.datax.disable | 任务禁用dataX | false | 否 | false |
3.2 运行参数
| 参数名 | 功能说明 | 参数默认值 | 参数值类型 |
|---|---|---|---|
| spark.driver.cores | driver的CPU数量 | 2 | int |
| spark.driver.memory | driver的内存大小 | 4g | string |
spark.driver.maxResultSize | 拉取到Driver的数据上限,一般不需要调整。 | 2g (默认取spark.driver.memory的一半) | string |
| spark.executor.cores | 每个executor的CPU数。Spark task的最大并发为spark.executor.cores * executor个数 | 2 | int |
| spark.executor.memory | executor的内存大小 | 4g | string |
spark.dynamicAllocation.maxExecutors | 单个Spark任务的executor的最大个数 | 100 | int |
| spark.sql.autoBroadcastJoinThreshold | 数据源侧的broadcast阈值,设为-1可以禁用。 PS: 禁用后不影响Spark AQE本身的broadcast | - | int |
| spark.sql.broadcastTimeout | broadcast超时时间。设为-1可以关闭超时限制 | - | int |
| spark.sql.files.maxPartitionBytes | 每个分区(Spark Partition)最大的文件大小,针对于大文件切分 | 268435456 | int |
| spark.sql.files.openCostInBytes | 小于该值的文件将会被合并,针对于小文件合并 | 8388608 | int |