智能数据洞察(私有化)
智能数据洞察(私有化)






- 文档首页
 智能数据洞察(私有化)用户指南数据准备可视化建模常用模版-案例介绍商业银行客户流失预测
智能数据洞察(私有化)用户指南数据准备可视化建模常用模版-案例介绍商业银行客户流失预测

在商业社会中 5% 的客户留存率增长意味着公司利润 30% 的增长,而把产品卖给老客户的概率是卖给新客户的 3 倍。所以在客户生命周期管理的分析框架下,用户离网阶段,采用营销手段赢回高价值用户,往往也是反映企业及产品核心竞争力的关键。
在银行及金融场景中,银行产品多样化,客户可以选择的途径更多,所以用户流失一直以来是金融行业重点关注的话题之一。银行坚持以客户为中心,关注营销和转化,提升客户服务体验,进一步提高客户与银行的粘度,加强对客户的运营和营销管理,减少不必要的客户流失,及时发现存在流失风险的客户,并采取措施挽留客户,延长客户生命周期。
本案例结合银行客户流失数据预测案例,重点介绍了决策树在实际案例中的应用。本案例通过客户的交易信息数据挖掘出对流失影响的信息,从而加强对客户的运营和营销,减少不必要的客户流失。
关于如何进行建模解决客户流失问题,业界已经有不少成熟的方法,当前业界主要的两大方法论分别是 SEMMA 方法论 和 CRISP-DM 方法论 :
SEMMA 方法论: 即抽样(Sample)、探索(Explore)、修改(Modify)、建模(Model)、评估(Assess),强调的是这5个核心环节的有机循环。
CRISP-DM 方法论: 全称为跨行业数据挖掘标准流程(Cross-Industry Standard Process for Data Mining),突出业务理解、数据理解、数据准备、建模、评价和发布这几个环节,强调将数据挖掘目标和商务目标进行充分结合。
在具体实践中,CRISP-DM 强调上层的商务目标的实现,SEMMA 则更侧重在具体数据挖掘技术的实现上。只有将两种方法紧密联系在一起,才能达到更好地达成数据分析挖掘的效果。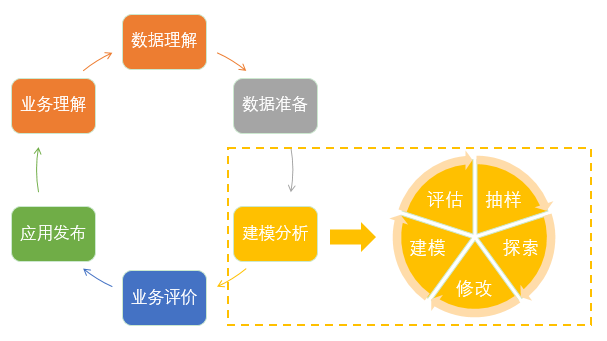
3.1 数据描述
结合数据准备的多元数据接入的能力,银行客户的数据可以便捷地接入系统中,一般的客户流失数据中包含了客户的个人信息,账户信息,存款信息,消费信息,基金/理财信息,数据的维度包含:
银行自有字段: 账户类信息、个人类信息、存款类信息、消费、交易类信息、理财、基金类信息、柜台服务、网银类信息
外部三方数据: 外呼客服数据、资产类数据、其他消费类数据
本案例采用经典信用卡用户流失的例子,数据字段说明如下:
| 字段名称 | 字段类型 | 字段意义 | 字段说明 |
|---|---|---|---|
| CLIENTNUM | long | 用户id | 用户id,unique值 |
| Attrition_Flag | string | 是否流失 | Existing Customer(留存用户) Attrited Customer(流失用户) |
| Customer_Age | int | 用户年龄 | 数字年龄,一般年龄也会影响流失的重要因素 |
| Gender | string | 性别 | M(男性)F(女性) |
| Dependent_count | int | 家庭人员统计 | 受抚养人的数量 |
| Education_Level | string | 教育情况 | 账户持有人的教育资格(例如:高中、大学毕业生等) |
| Marital_Status | string | 婚姻状态 | 已婚、单身、离婚、未知 |
| Income_Category | string | 收入区间 | 帐户持有人的年收入类别(< $$$$40K、$$$$40K - 60K、$$$$60K - $$$$80K、$$$$80K-$$$$120K,>$120K) |
| Card_Category | string | 信用卡的分类 | 卡类型(蓝、银、金、白金) |
| Months_on_book | int | 持有时间 | 与银行的关系期 |
| Total_Relationship_Count | int | 用户开通的产品数 | 客户持有的产品数量 |
| Months_Inactive_12_mon | int | 最近12个月不活跃月数 | 最近12个月不活跃月数 |
| Contacts_Count_12_mon | int | 最近12个月沟通月数 | 最近12个月沟通月数 |
| Credit_Limit | int | 信用卡额度 | 信用卡额度 |
| Total_Revolving_Bal | int | 信用卡总额度 | 信用卡上的总循环余额 |
| Avg_Open_To_Buy | long | 开放信用额度 | 过去12个月开放信用额度 |
| Total_Amt_Chng_Q4_Q1 | float | 交易金额变化 | 交易金额变化(第 4 季度比第 1 季度),比例 |
| Total_Trans_Amt | long | 交易总额 | 总交易金额(过去 12 个月) |
| Total_Trans_Ct | int | 总交易数 | 总交易数(过去 12 个月) |
| Total_Ct_Chng_Q4_Q1 | float | 交易数量的变化 | 交易数量的变化(Q4 比 Q1),比例 |
| Avg_Utilization_Ratio | float | 平均卡使用率 | 平均卡使用率 |
3.2 数据准备
本案例的数据采用 hive 的方式接入,由于其大数据量优秀的处理能力,能够支持用户流失每日的埋点数据统计,数据结果如下,结合数据准备的探查,进一步了解数据分布的情况。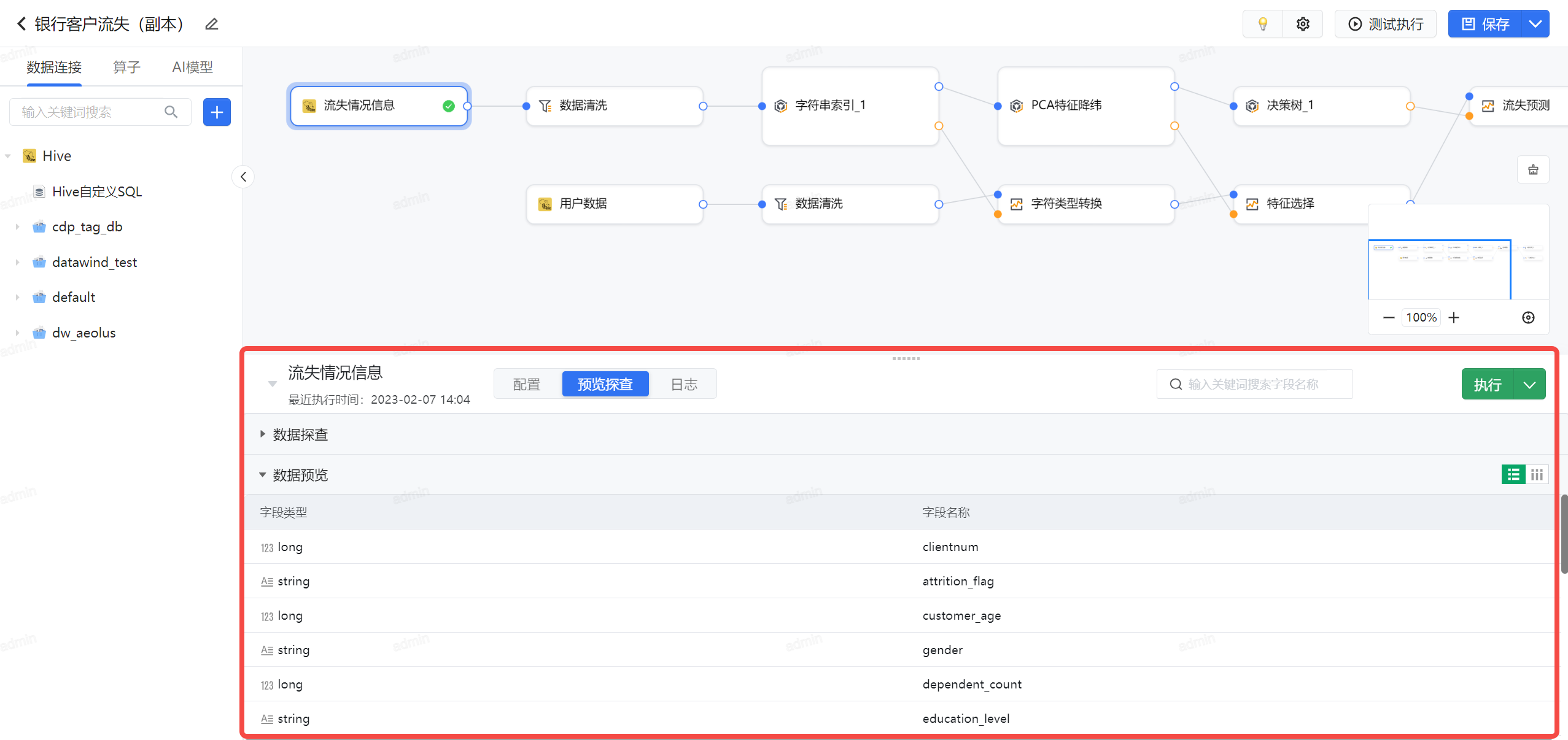
3.3 数据预处理
3.3.1 数据探查
对数据源进行探查,发现 education_level 占有 15% 的未知分类,marital_status 未知占7.4%,income_category 占 10.98%,在实际处理中,这类数据并不能帮助判断实际的流失,所以在探查中需要第一步先对数据的分布/脏数据的存在先做处理。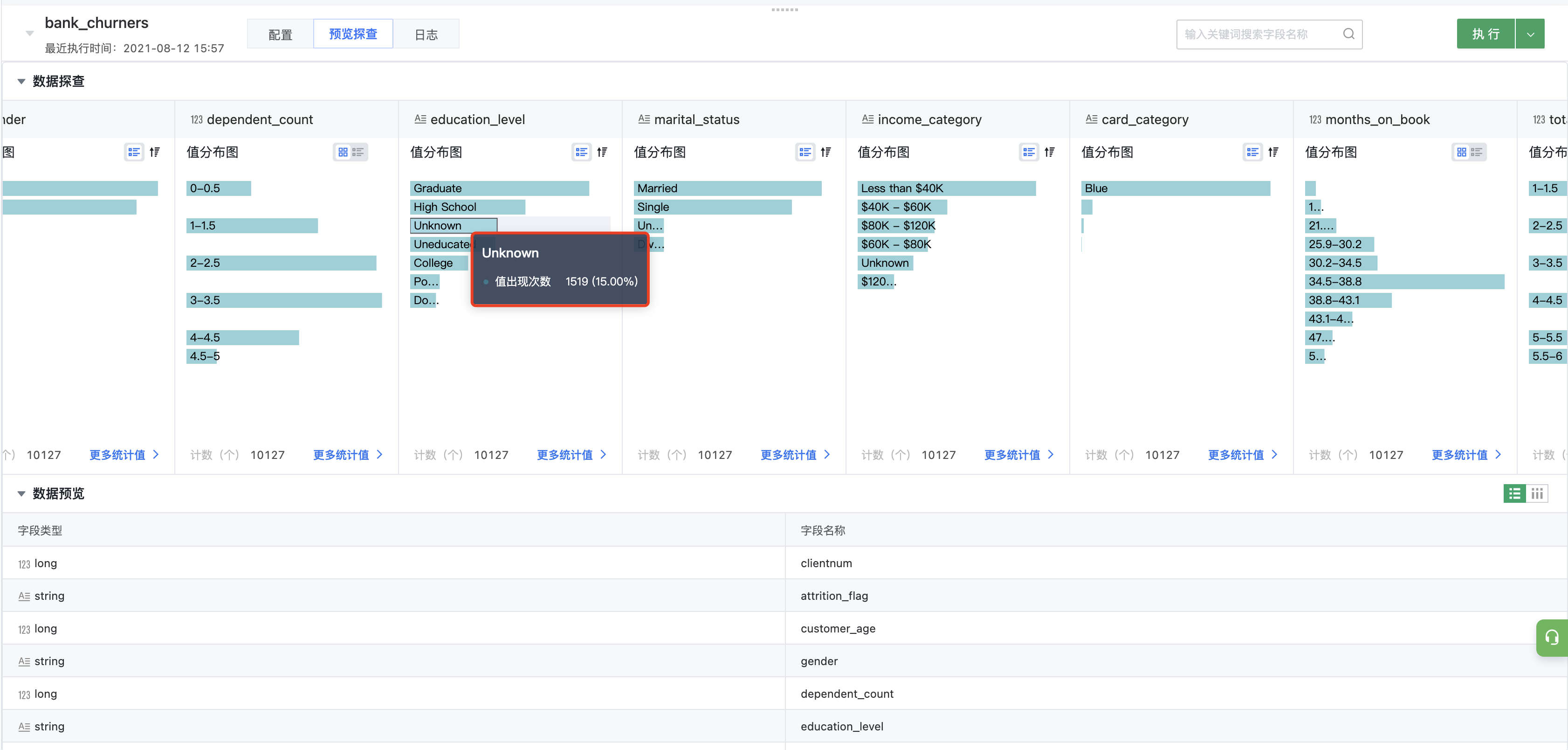
3.3.2 脏数据过滤
从数据探查的结果和对业务数据的理解,字段中包含了大量的 Unknown 的脏数据,以及白金信用卡是专人专项跟踪的,不需要进行流失判断,所以我们可以采用过滤算子,将 education_level, income_category, marital_status 为 Unkown,card_category为 Platinum 的数据过滤。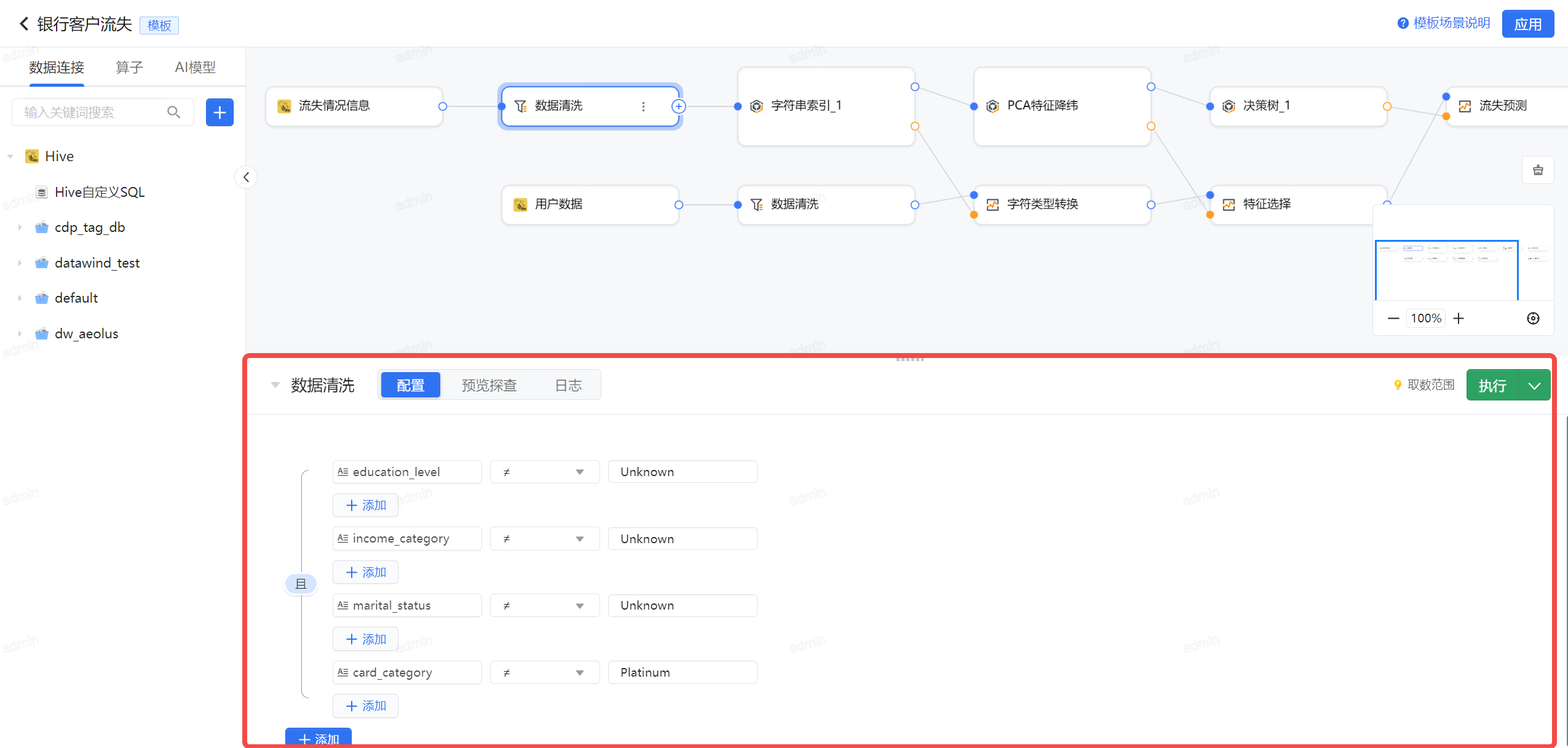
3.3.3 字符串索引
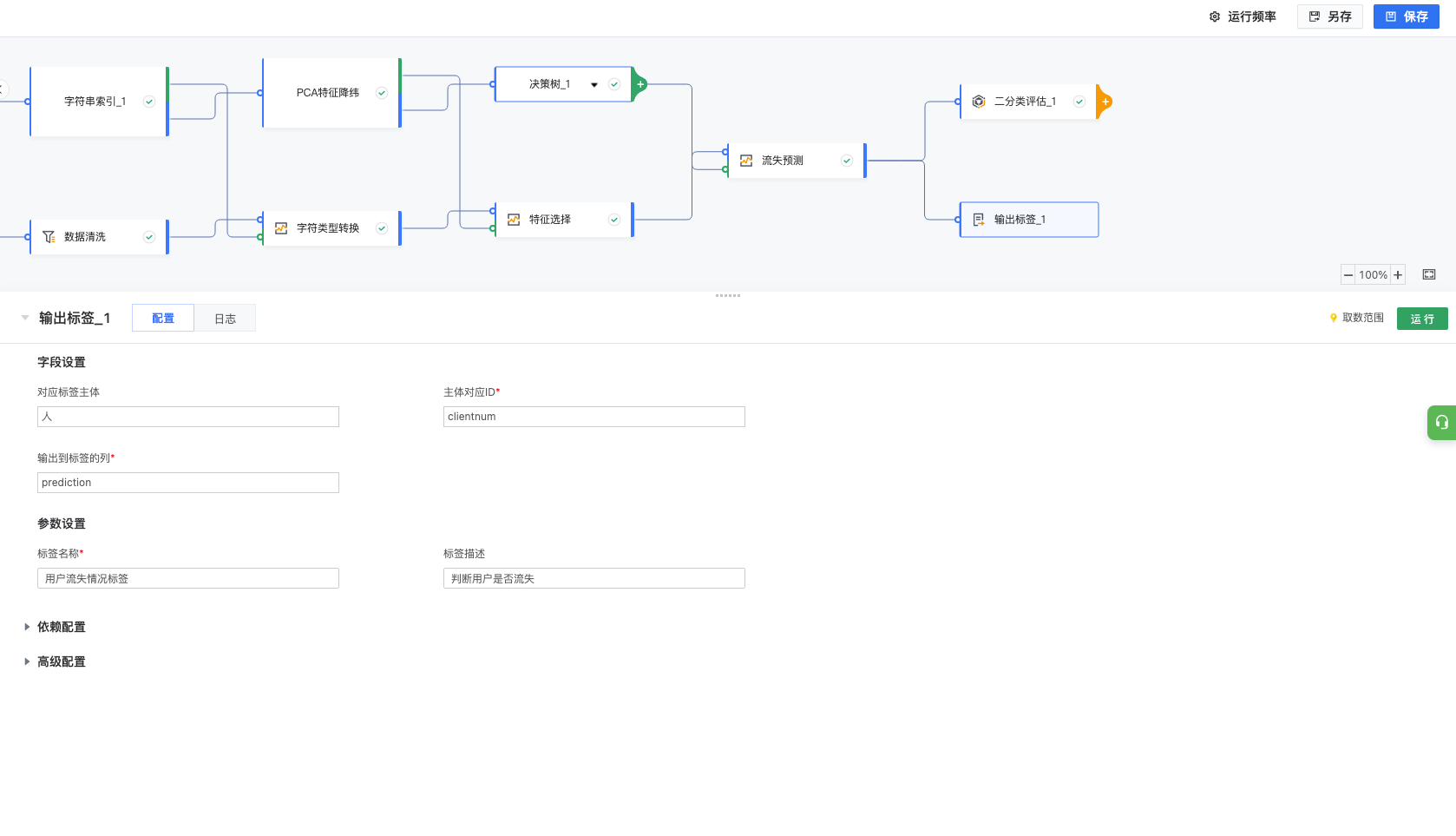
数据准备建模过程,需要将字符类型进行索引处理,传统做法可以采用计算列的方式,比如主动将 Existing Customer 主动替换成 0,将 Attrited Customer 替换成 0,数据准备提供了字符串索引的算子,一步将所有字符列转换成索引。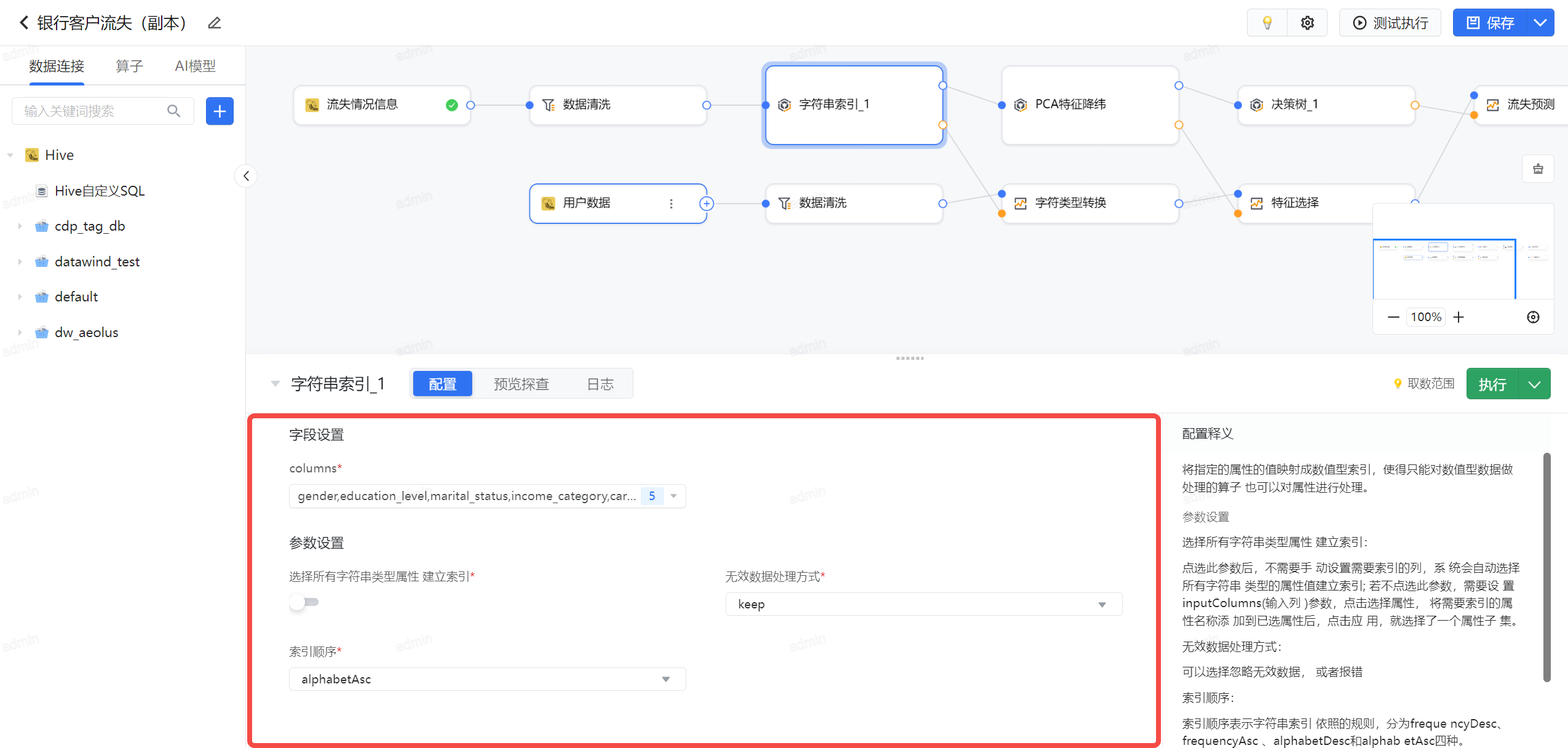
结果如下: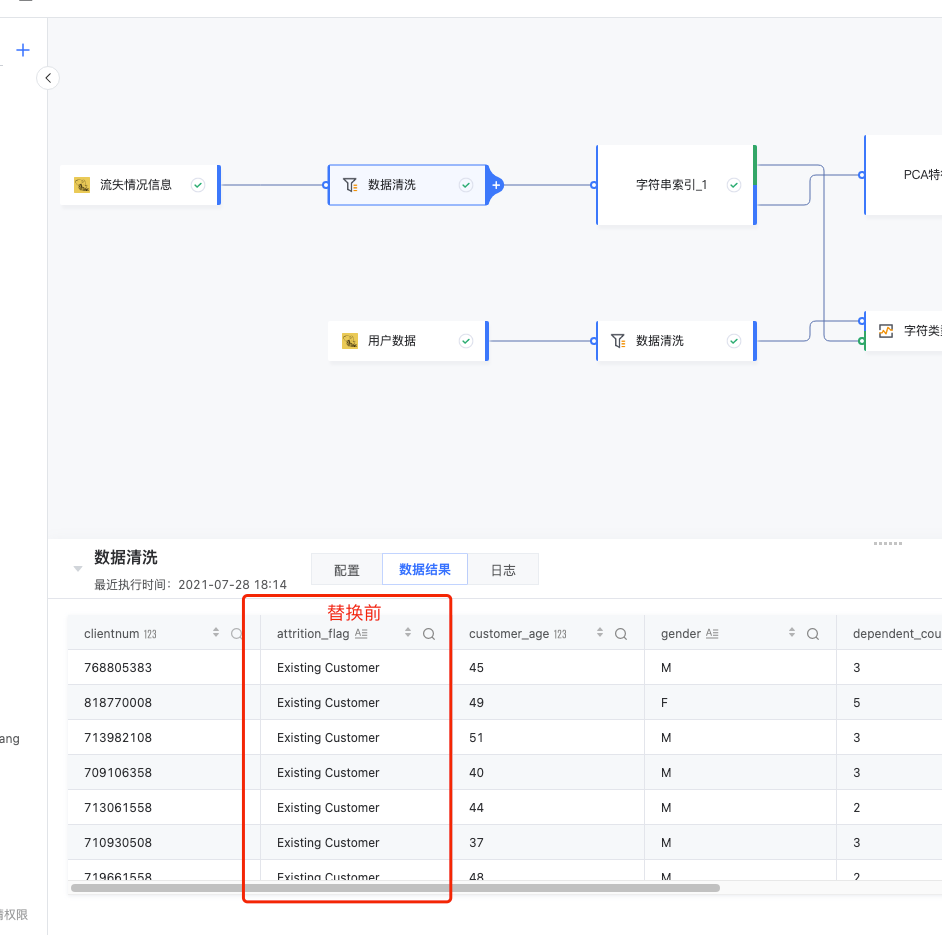
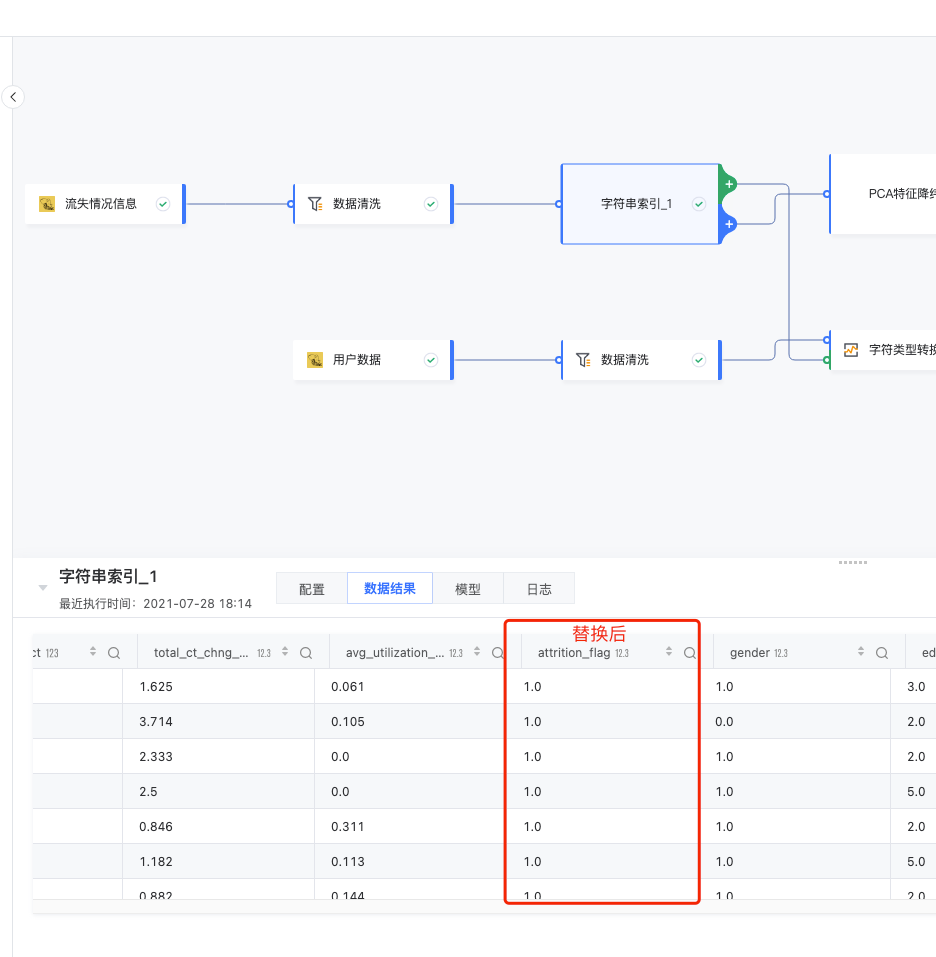
3.4 特征处理
特征处理这里采用PCA降维,主要因为涉及高维特征向量的问题往往容易陷入维度灾难。随着数据集维度的增加,算法学习需要的样本数量呈指数级增加,所以采用PCA可以把可能具有相关性的高维变量合成线性无关的低维变量,称为主成分,低维数据集会尽可能的保留原始数据的变量,同时也能加速模型的收敛。
3.5 问题建模
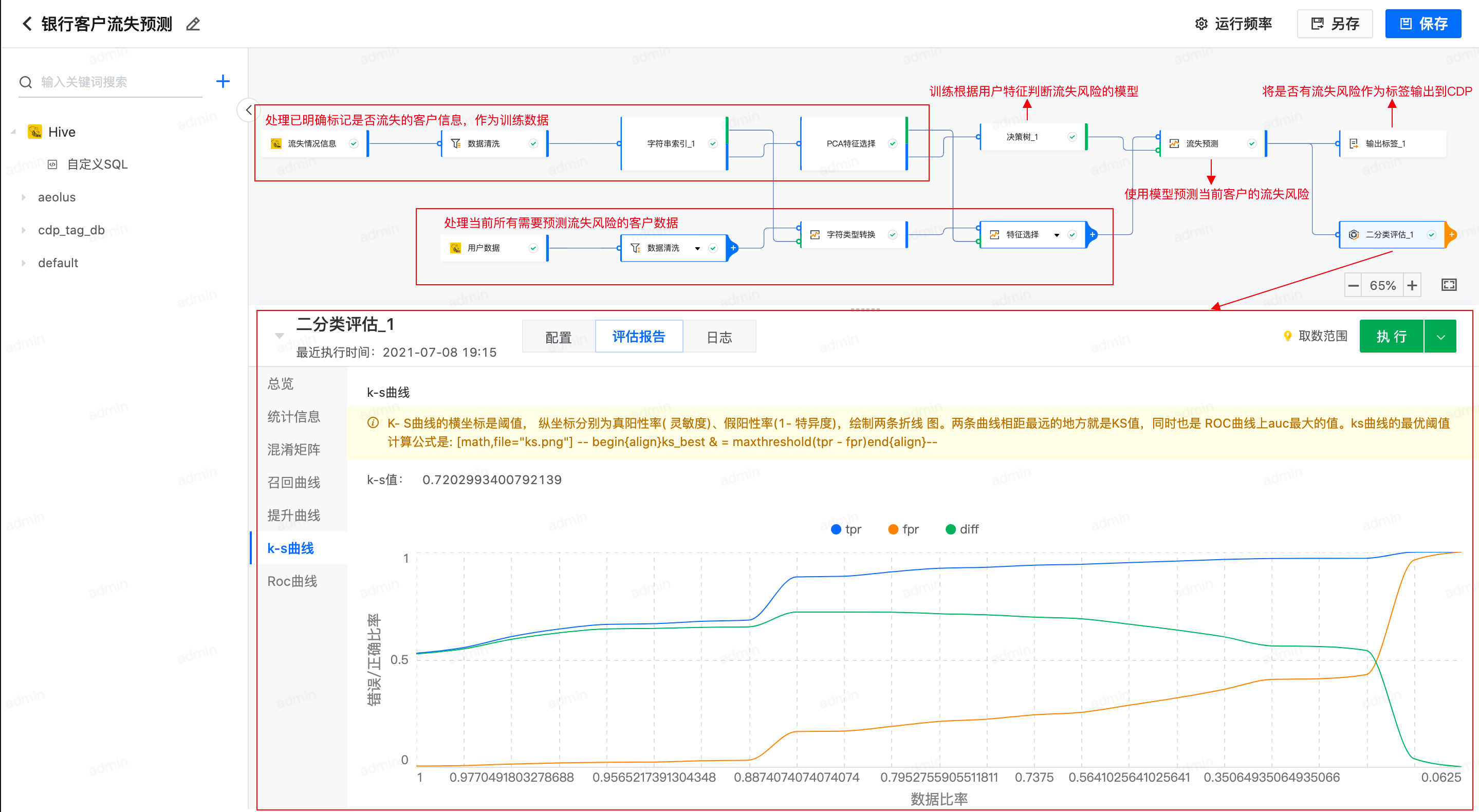
构建上面的训练/预测任务,对历史数据采用决策树进行二分类训练,决策树因为模型具有可读性,分类速度快的优点,可以方便对机器学习的理解,最终模型会构建成一个树状的结构,每个叶子结点根据if-then的逻辑,经过层层判断,最终到唯一确定分类的例子,如下图所示,最快经过一层判断,就能确定能否贷款。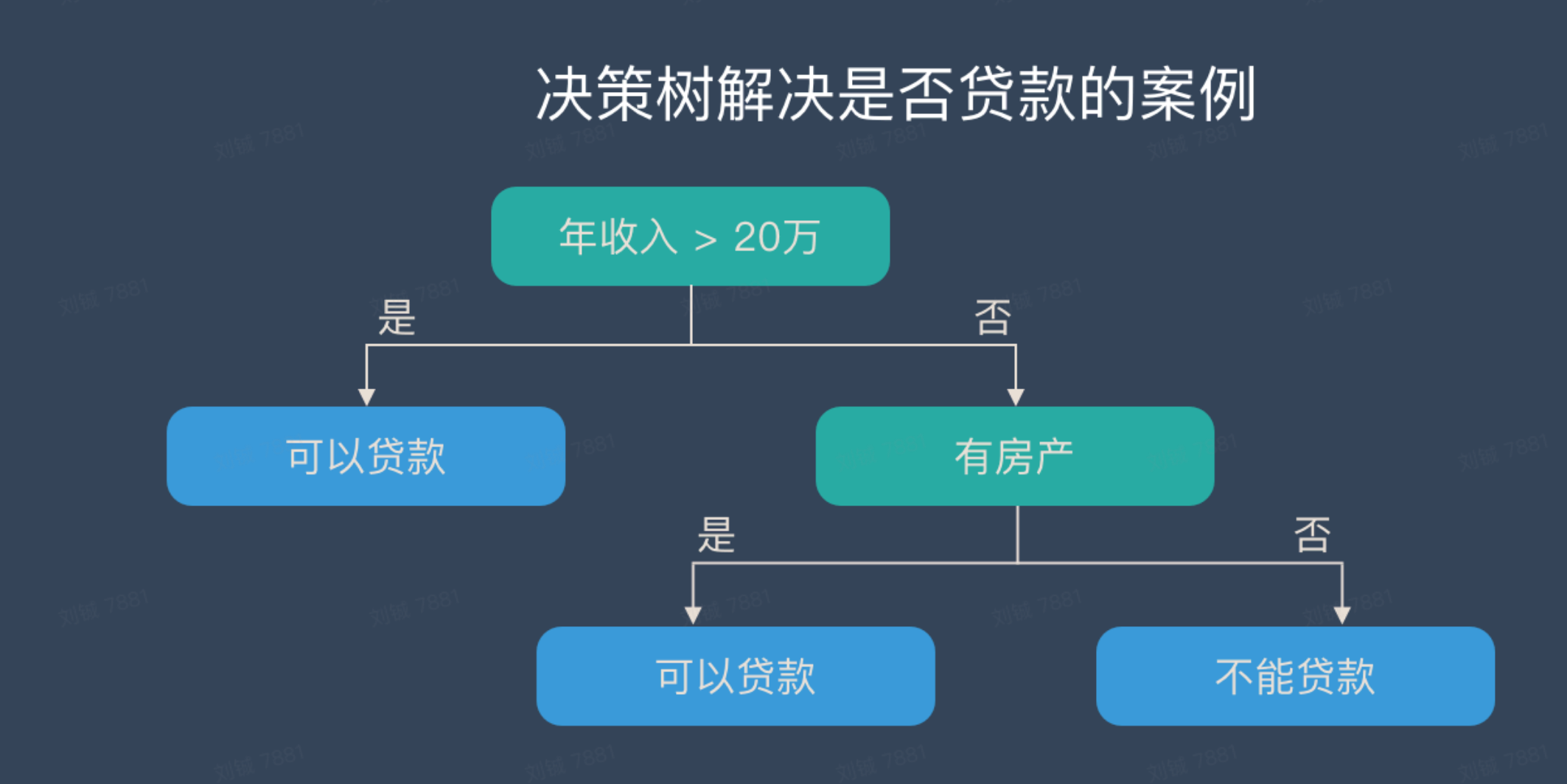
3.6 模型评估
数据准备集成多种评估指标来辅助AI算法的调参数,如下的二分类评估报告
3.6.1 混淆矩阵
计算召回率/正确率,表示精度常见的指标: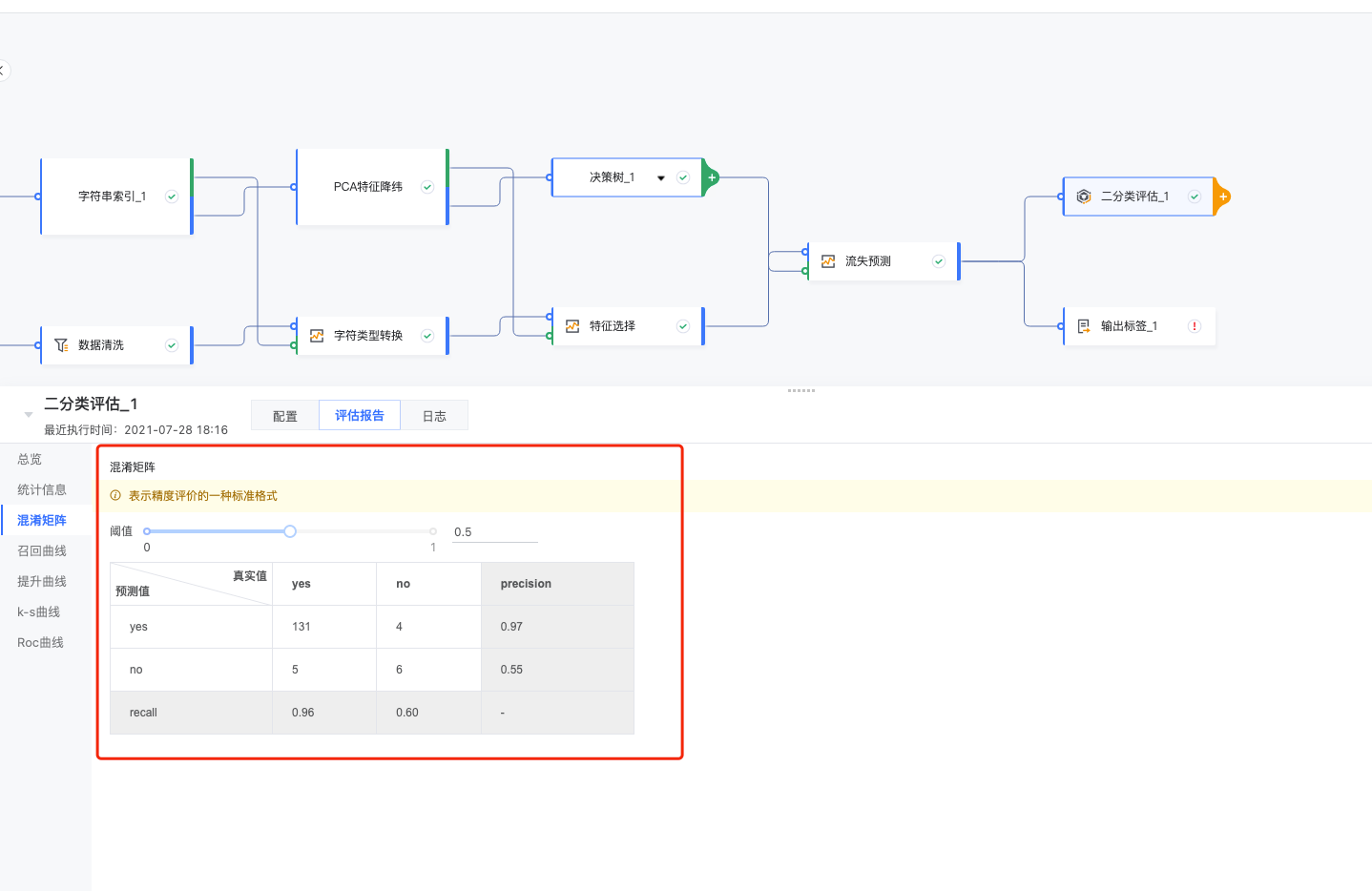
3.6.2 召回曲线
P-R图直观地显示出学习器 在样本总体上的查全率和 查准率。 在进行比较时, 若一个学习器的P-R曲线完全被另一个学习器的曲线完全“包住”, 则我们就可以断言后者的性能优于前者。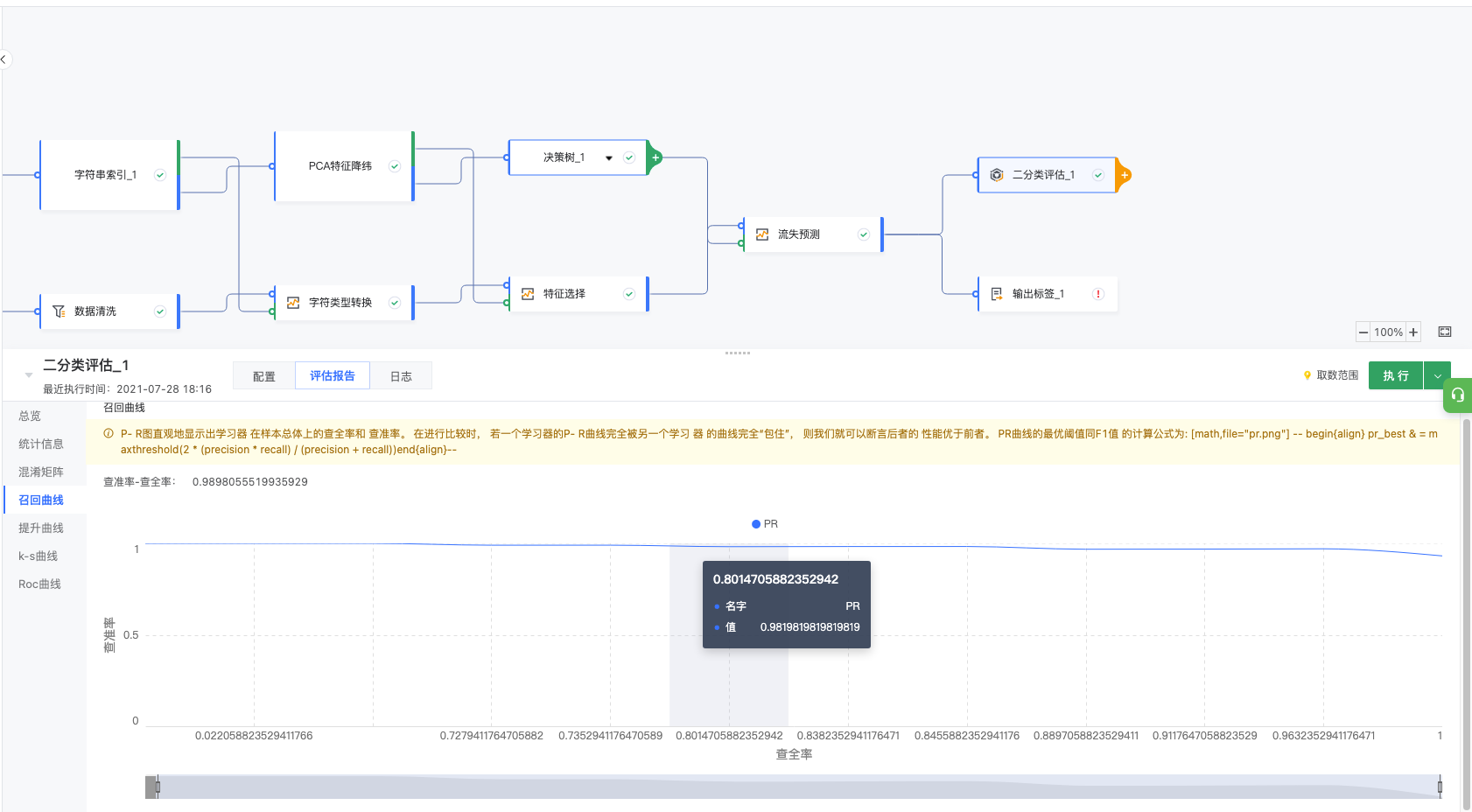
3.6.3 提升曲线
Lift指标衡量的是与不利用模型相比,模型的预测能力提升了多少。Lift=P V/k,其中 PV 为正例的命中率,即预测为正例的样本中真实正例的比例;k 是在不使用模型的情况下 ,用先验概率估计正例的比例。Lift越大则表明模型的效果越好。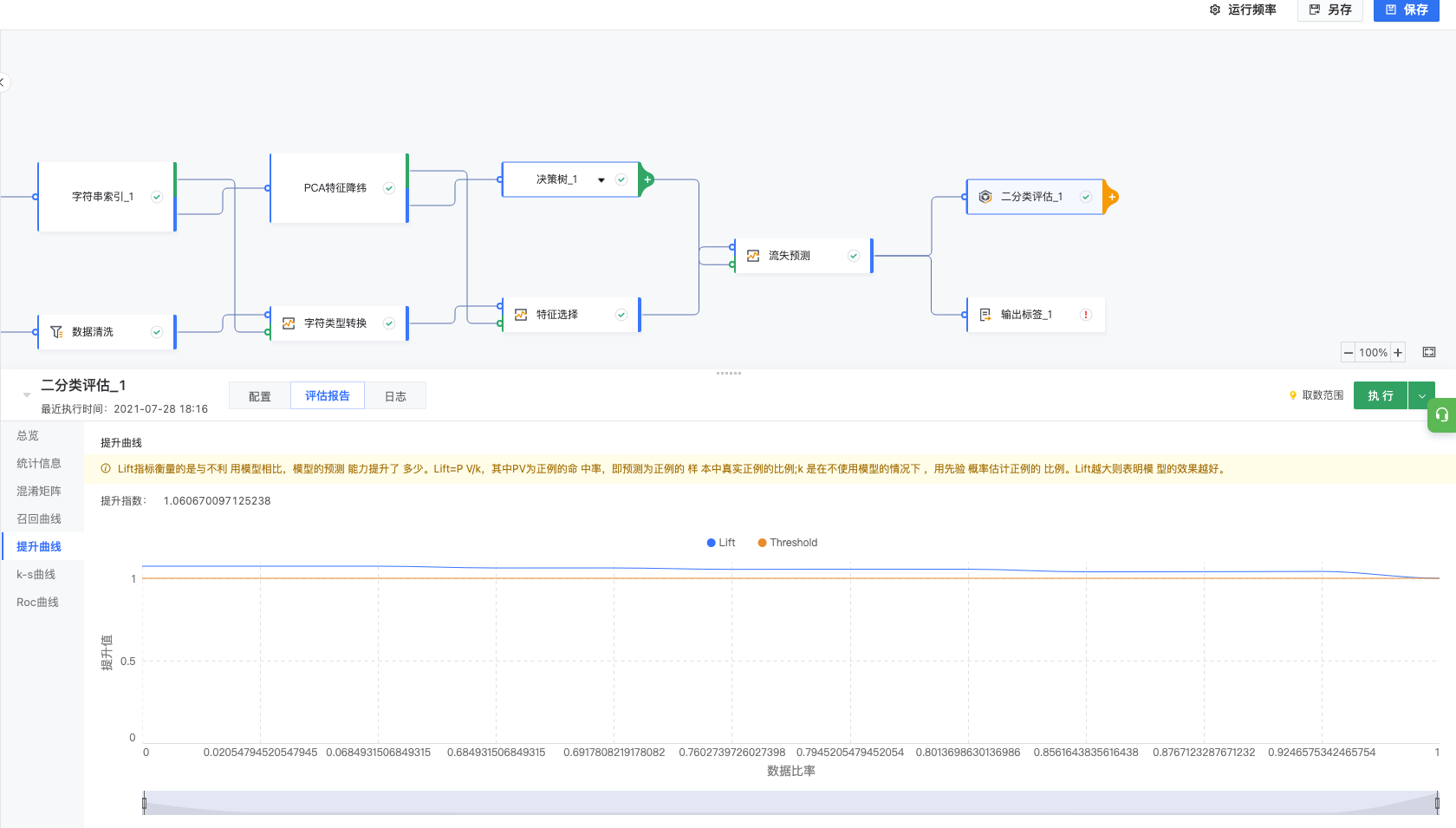
3.6.4 K-S 曲线
K-S 曲线的横坐标是阈值, 纵坐标分别为真阳性率( 灵敏度)、假阳性率(1- 特异度),绘制两条折线 图。两条曲线相距最远的地方就是KS值,同时也是 ROC曲线上auc最大的值。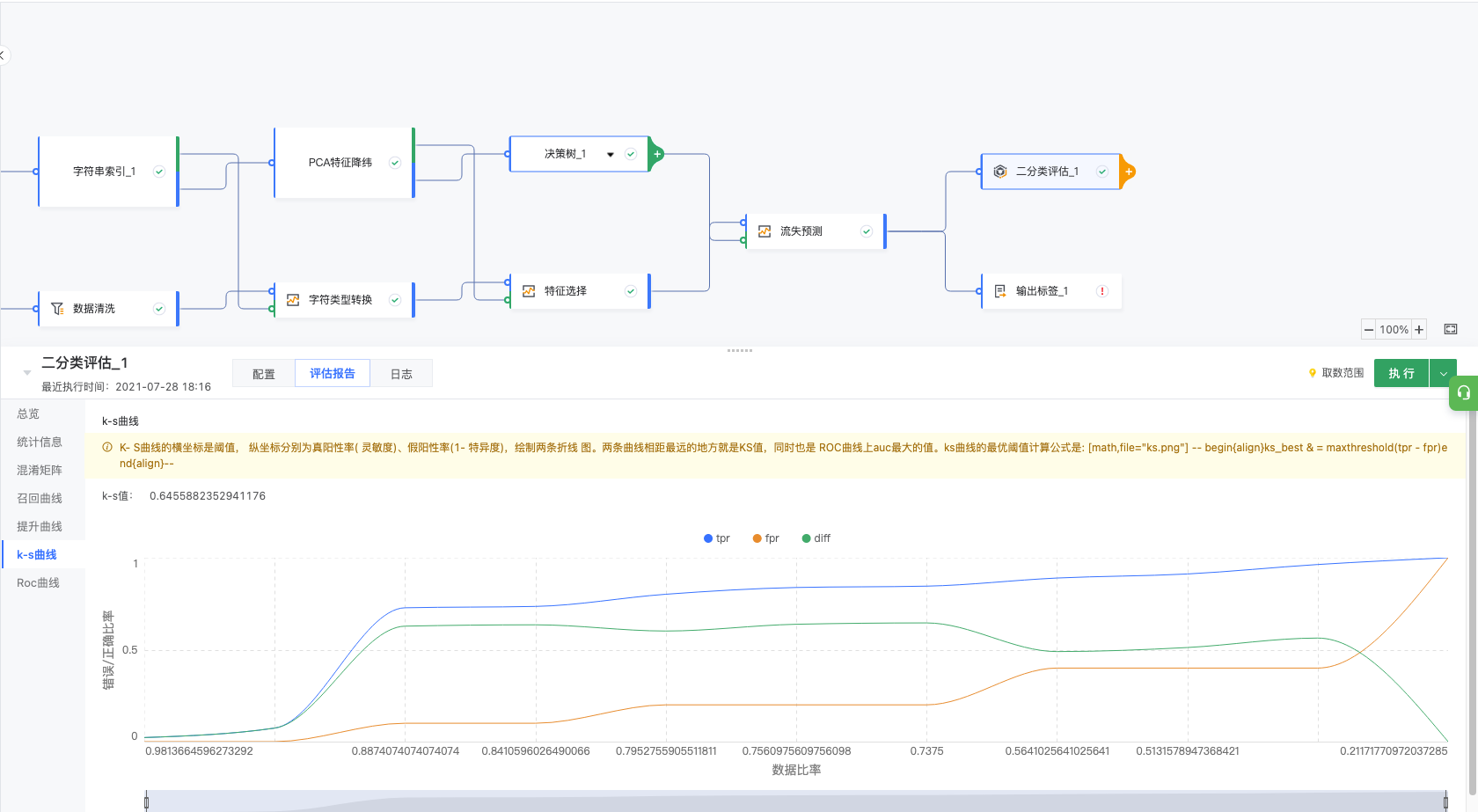
3.6.5 ROC 曲线
ROC曲线是根据一系列不 同的二分类方式(分界值 或决定阈), 以真阳性率 (灵敏度)为纵坐标,假 阳性率(1- 特异度) 为横坐标绘制的曲线。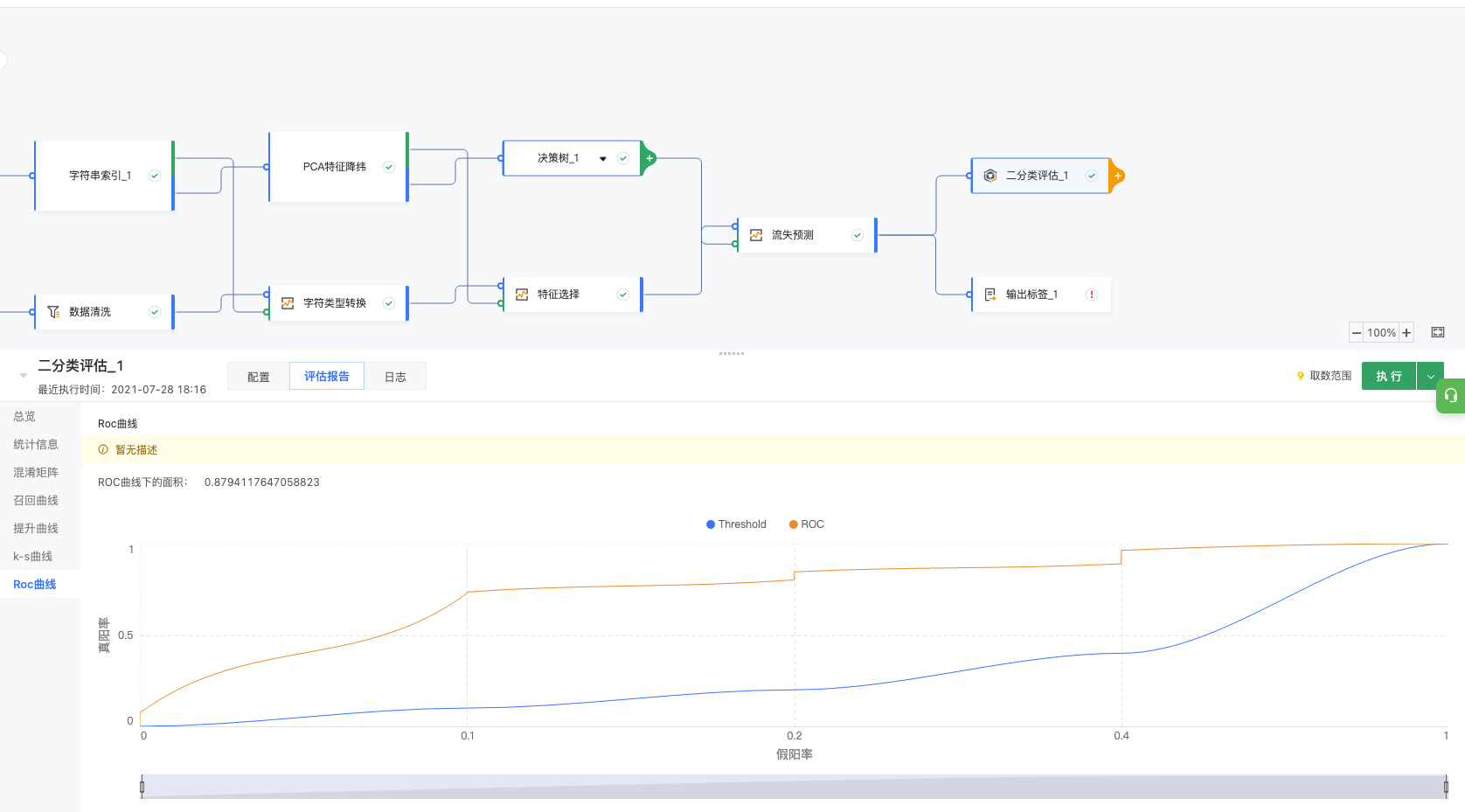
3.7 数据生产应用
在得到有效的模型之后,可以将最终的结果输出到数据集(hive/clickhouse),后续可以在 DataWind 平台中进行可视化查询/创建仪表盘大屏。也可以结合 CDP 产品,进行标签洞察/营销应用/用户分群等。