智能数据洞察(私有化)
智能数据洞察(私有化)






- 文档首页
 智能数据洞察(私有化)用户指南数据准备可视化建模任务创建离线任务创建
智能数据洞察(私有化)用户指南数据准备可视化建模任务创建离线任务创建

任务创建,是指可视化建模任务的创建环节,通常包含新建任务、数据连接等步骤。本文将结合产品实操界面介绍 离线任务的创建步骤。
可视化建模任务支持抽取数据源中的数据,通过拖拽形式添加数据处理节点,将处理完成的数据输出到目标源中。
- 任务类型:离线任务
- 已支持的离线任务的输入数据源:Hive, MySQL, ClickHouse, Kafka, HttpAPI, 飞书, CSV/Excel, Oracle, Impala, PostgreSQL, Hbase, SQLServer, MaxCompute, ADB, MongoDB, Hana, Teradata, Db2, Vertica, GreenPlum等20几种主流的数据源
- 已支持数据清洗节点:字段设置、筛选行、添加计算列、聚合、连接、合并、行列转置等
- 已支持的AI建模能力:特色专区算子、特征工程、机器学习、自然语言处理等多种算子
- 已支持输出内置数据源:以 Hive、ClickHouse、ByteHouse 存储的数据集
保存任务-运行类型-运行频率中的交易日历及多次同步功能目前仅支持私有化部署V2.83.0及以上版本产品使用,如您需要使用该功能,请联系火山引擎产团队为您开通。
在您点击进入「可视化建模」后,点击「任务列表」—「新建」—「新建离线任务」,即可跳转到任务创建页面。
在新建任务页面,点击左上方的加号,添加数据连接;可以选择添加多种类型的数据连接,平台支持对大部分离线存储做自定义SQL。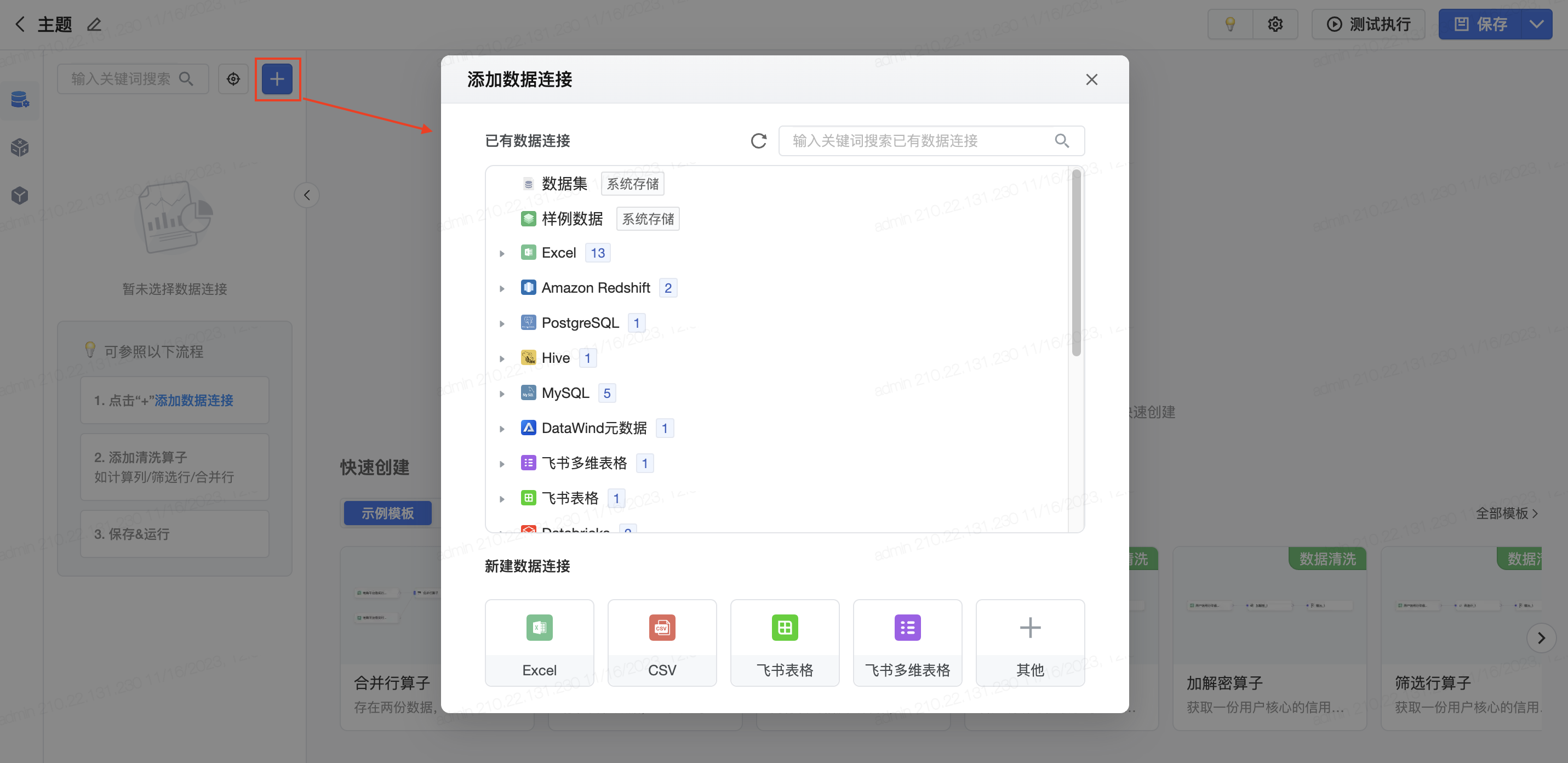
如果选择了数据集,在左侧画布中会加载:自定义SQL(离线任务可显示)、可视化建模数据集、智能数据洞察数据集、客户数据平台数据集(如同时购买并部署该产品)。
- Hive/ClickHouse自定义SQL:
- Hive:可视化建模输出并且数据存储为Hive类型数据集,可以写SQL,满足Hive语法即可
- ClickHouse:可视化建模输出并且数据存储为Clickhouse数据集,可以写SQL,满足ClickHouse语法即可
- 可视化建模数据集:可视化建模输出的数据集,不区分输出存储类型是Hive/ClickHouse
- 智能数据洞察数据集:通过“数据集”模块构建输出的数据集;
- 客户数据平台数据集:如同时购买并部署客户数据平台,则可以在此处使用该类数据集。
可视化建模任务创建页面的数据连接列表中,点击具体某个数据连接右侧的删除按钮,即可移除数据连接。
通过点击节点右侧加号添加并配置处理节点,拖拽上一节点右侧加号和下一节点左侧原点连线,配置节点流转关系。点击“应用”后可展开处理后的数据结果预览。
如下图所示,点击输入数据算子块的输出+号,展开六类操作节点:输出、数据清洗、特色专区算子、AI-特征工程、AI-机器学习、AI-自然语言,点击其中一类,则可看到可以使用的算子。
算子,即数据处理的节点。
常用算子说明
- 输出:表示画布流程执行完数据输出到指定位置并配置任务执行逻辑
- 数据清洗:主要负责模型搭建(如多表连接、多表合并)、字段格式转换(如字段设置、行转列、列转行)、数据计算(如计算字段、聚合、前K值Top值)、数据过滤(如去重、采样)等
- 特色专区算子:包含火山方舟大模型等大模型算子
- 特征工程/机器学习:表示如主成分分析、特征重要度、聚类、分类、回归等AI算法能力
- 自然语言处理:表示NLP自然语言处理能力,其中分词、移除停用词采用词包为开源词包
- 特征工程/机器学习/自然语言处理 算子后只可以搭配 「预测」算子进行使用
不仅在画布中可见算子,也支持在左侧tab栏中点击“算子”,选择可用的算子。具体每一个算子与模型的应用方式不同,在对应算子文档中将为您展开具体介绍,本文仅就任务创建的主要流程为您介绍。
在实际使用中,可视化建模算子支持增加文字描述,帮助用户更清晰地了解当前算子的备注信息。
可视化建模任务创建页面,支持自由布局与网格布局切换,灵活调整任务各节点的布局。
可视化建模新建任务页面,支持统一展示任务异常节点,辅助排查任务问题。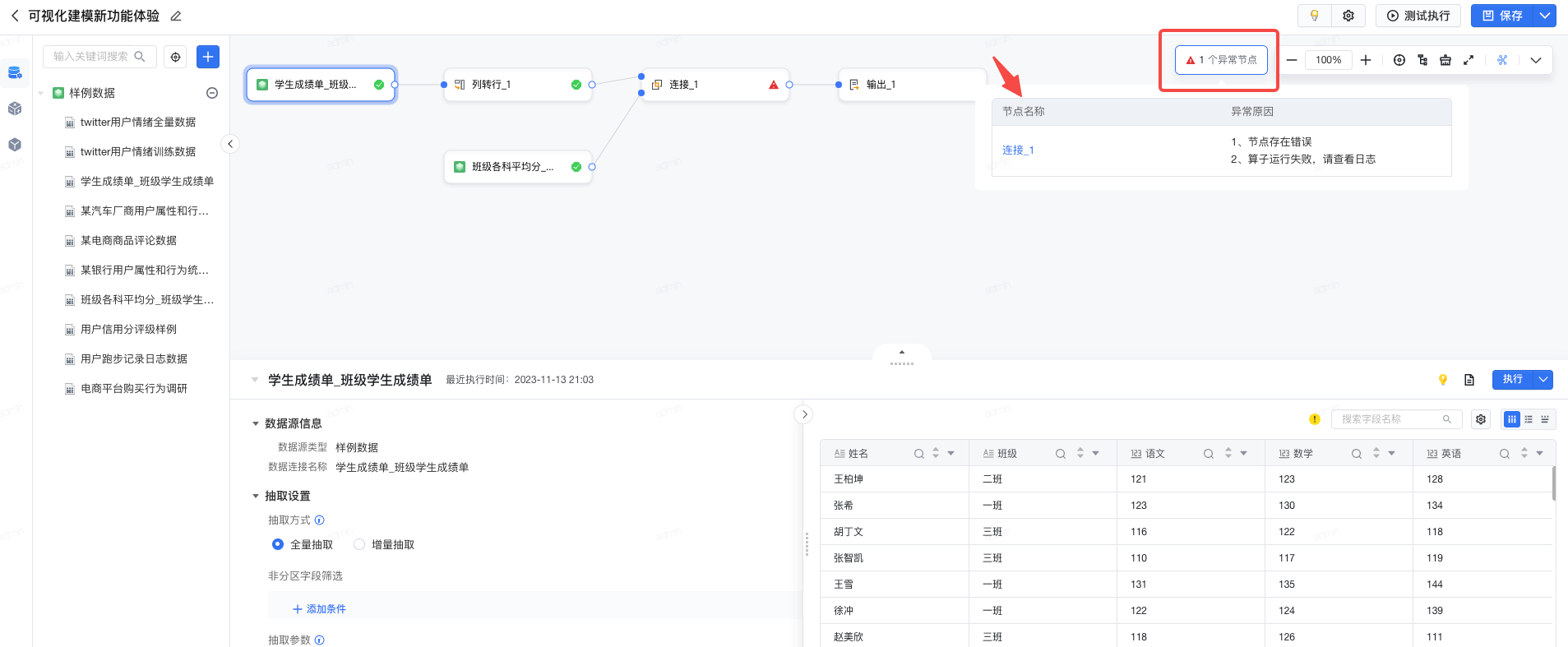
可视化建模任务创建页面,也支持通过点击删除键执行算子删除操作,提高数据清洗效率。
查看预览
- 在可视化建模任务的编辑页面,选择数据连接后,支持便捷的预览能力。您可预览明细数据、表结构、数据探查。
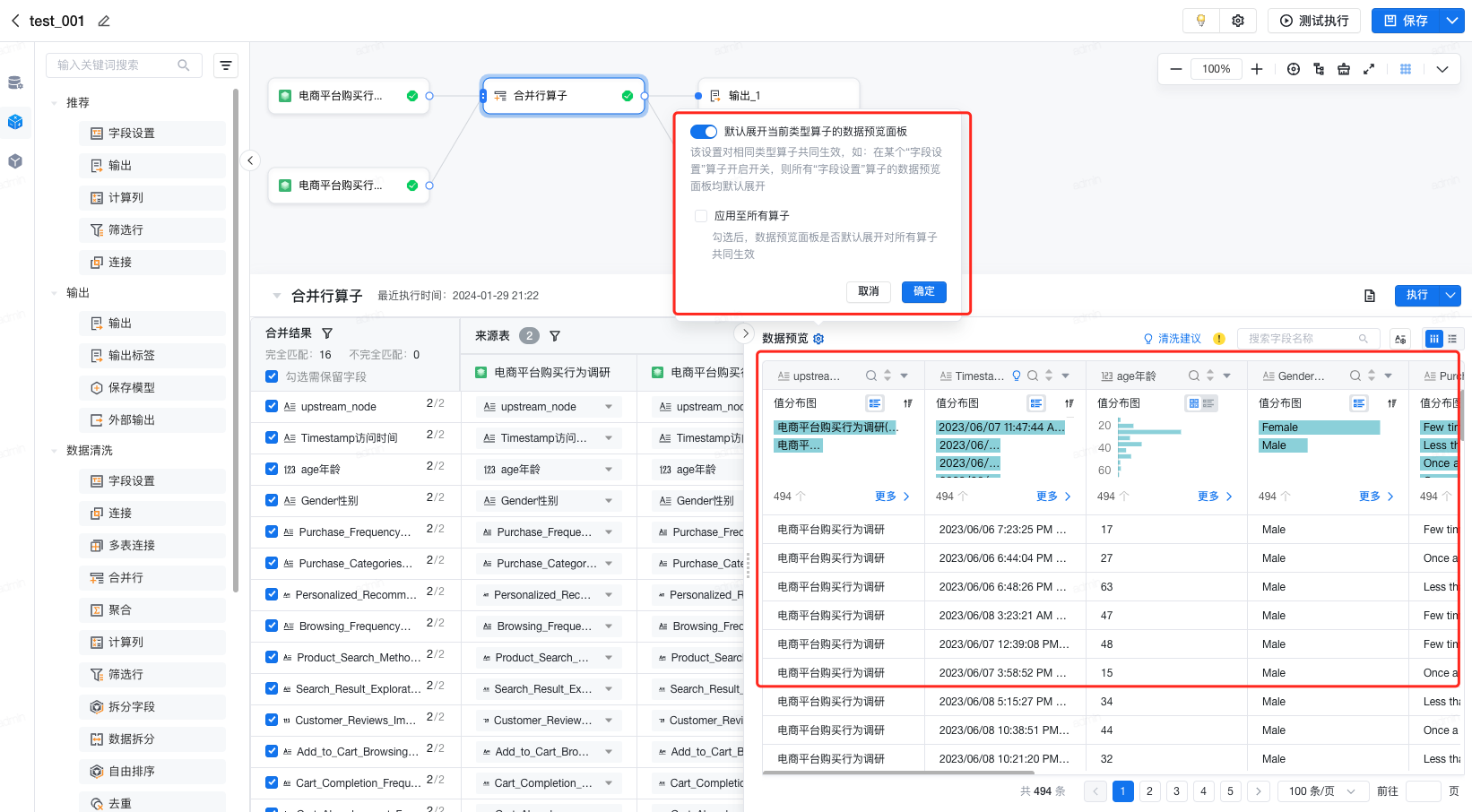
- 支持设置“是否默认展开当前类型算子的数据预览面板”以及“应用至所有算子”,满足不同用户的使用习惯。
- 合并“数据探查”和“明细数据”的预览面板,实现信息集中展示,简化操作,增强功能使用率。
- 点击每列数据的 “▼”按钮 ,支持快速选择算子,进行数据处理。如下图所示:
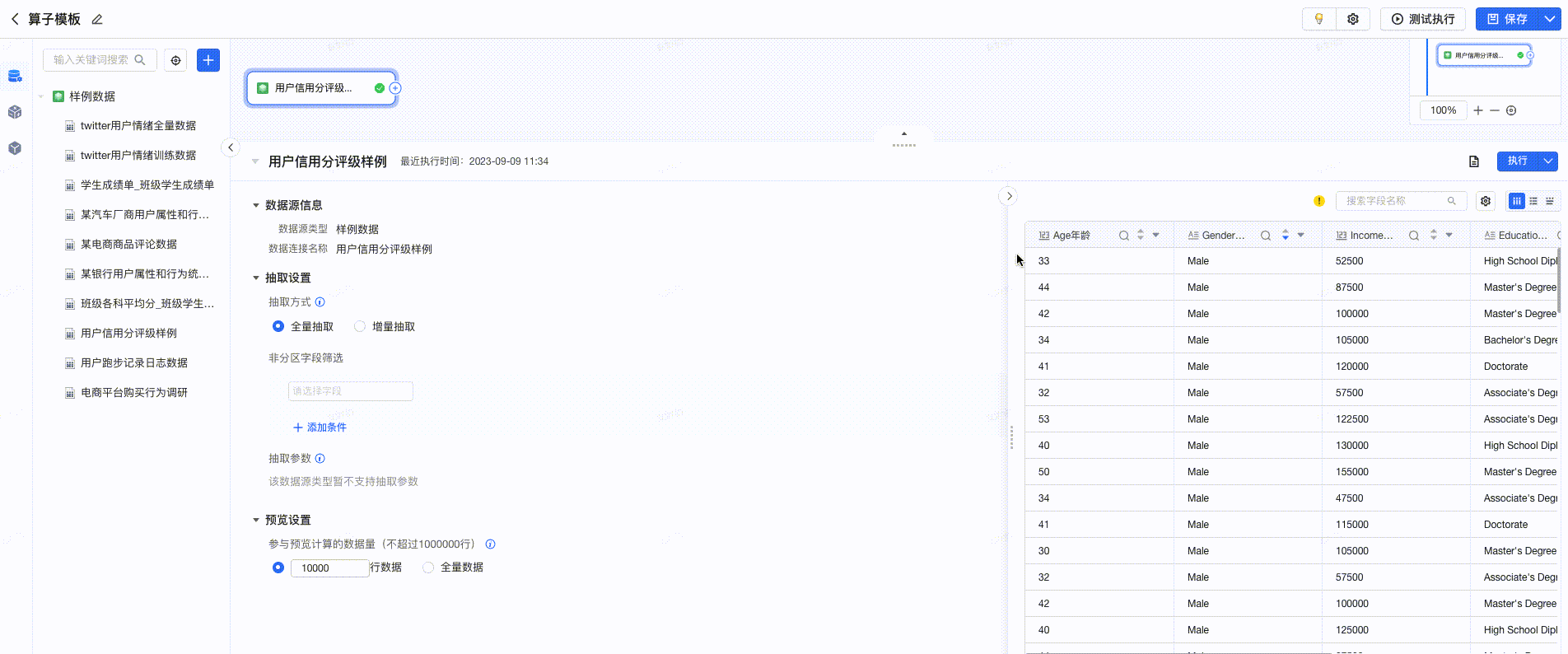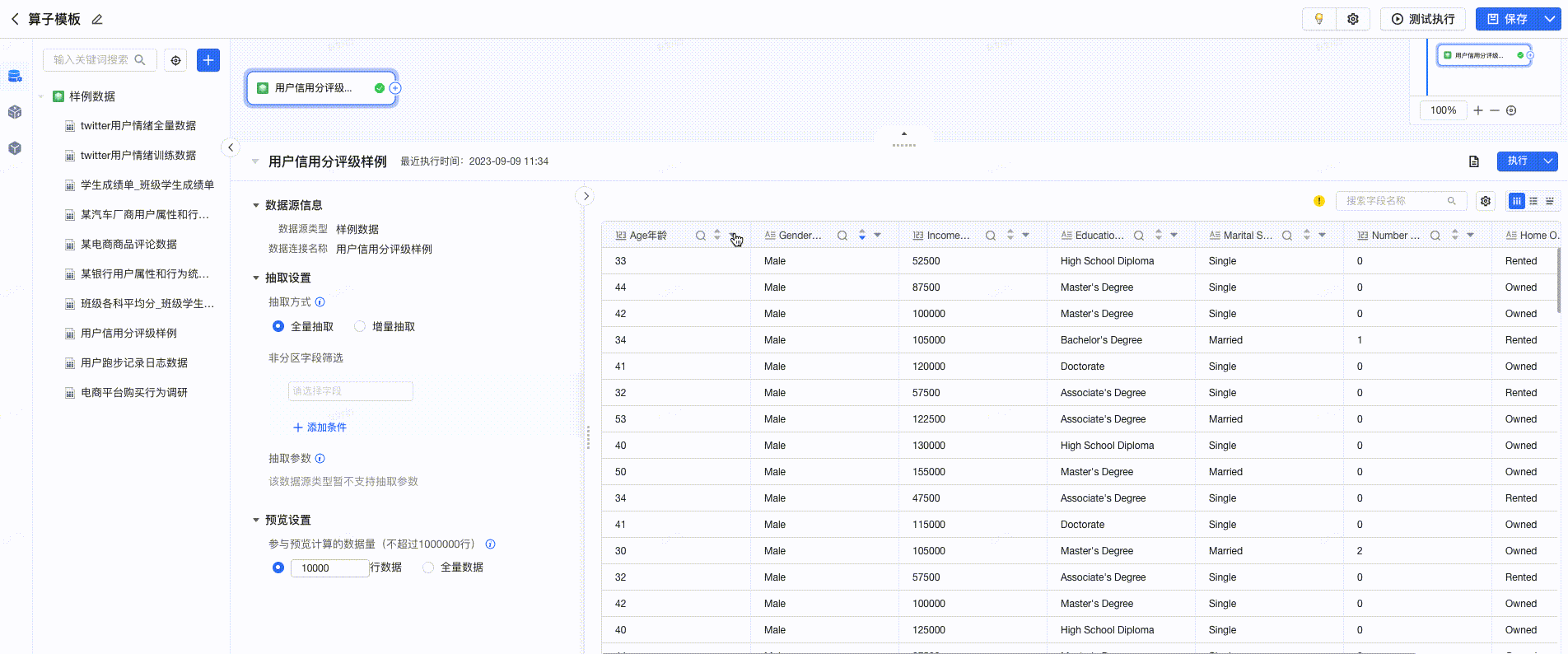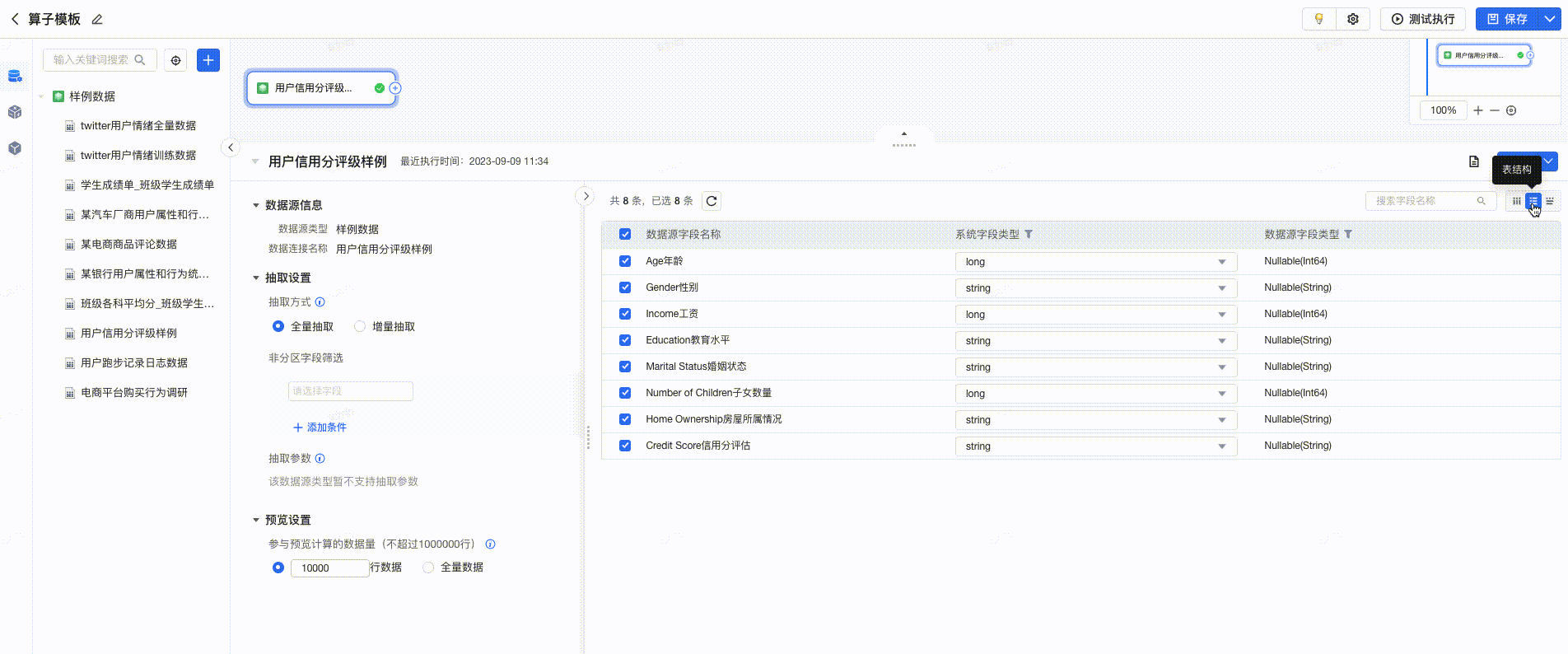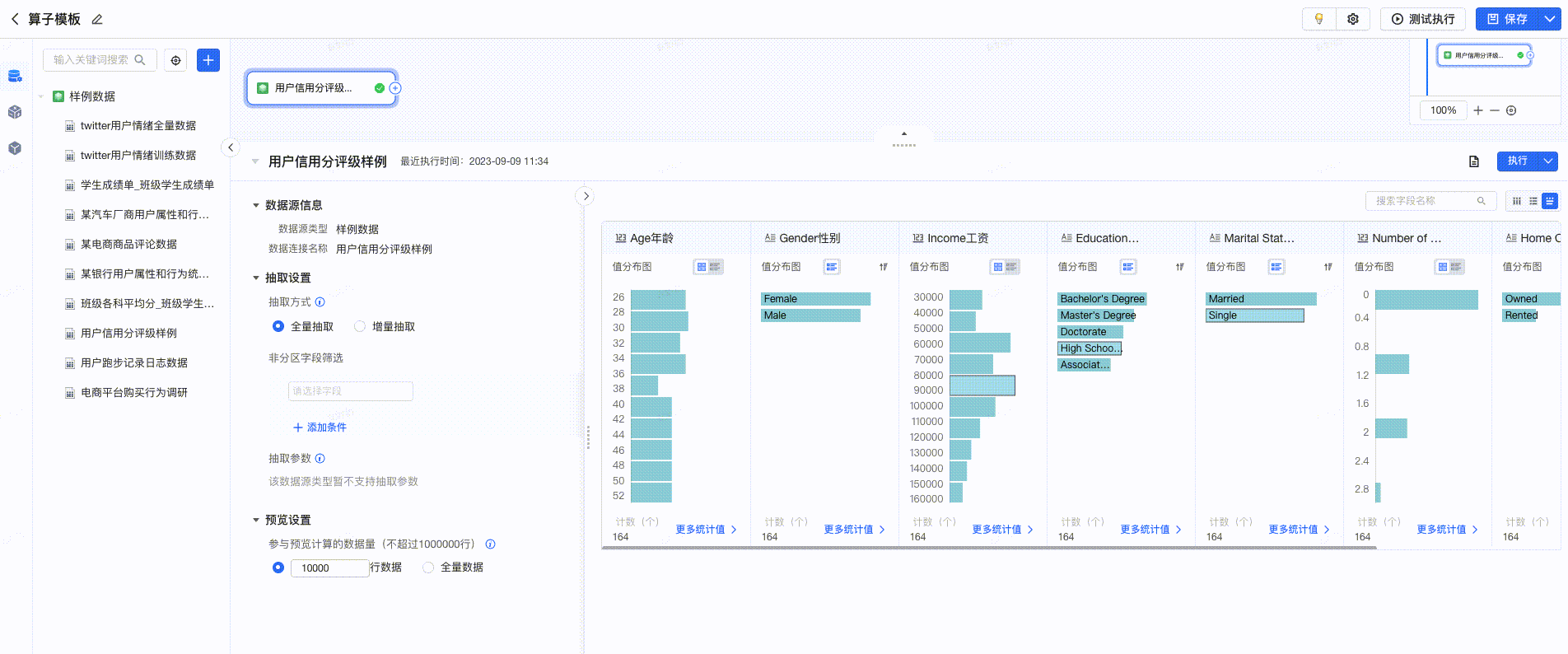
采纳建议
在预览中,提供数据清洗建议,用户点击后可一键完成清洗,提高数据清洗的效率。如下图所示: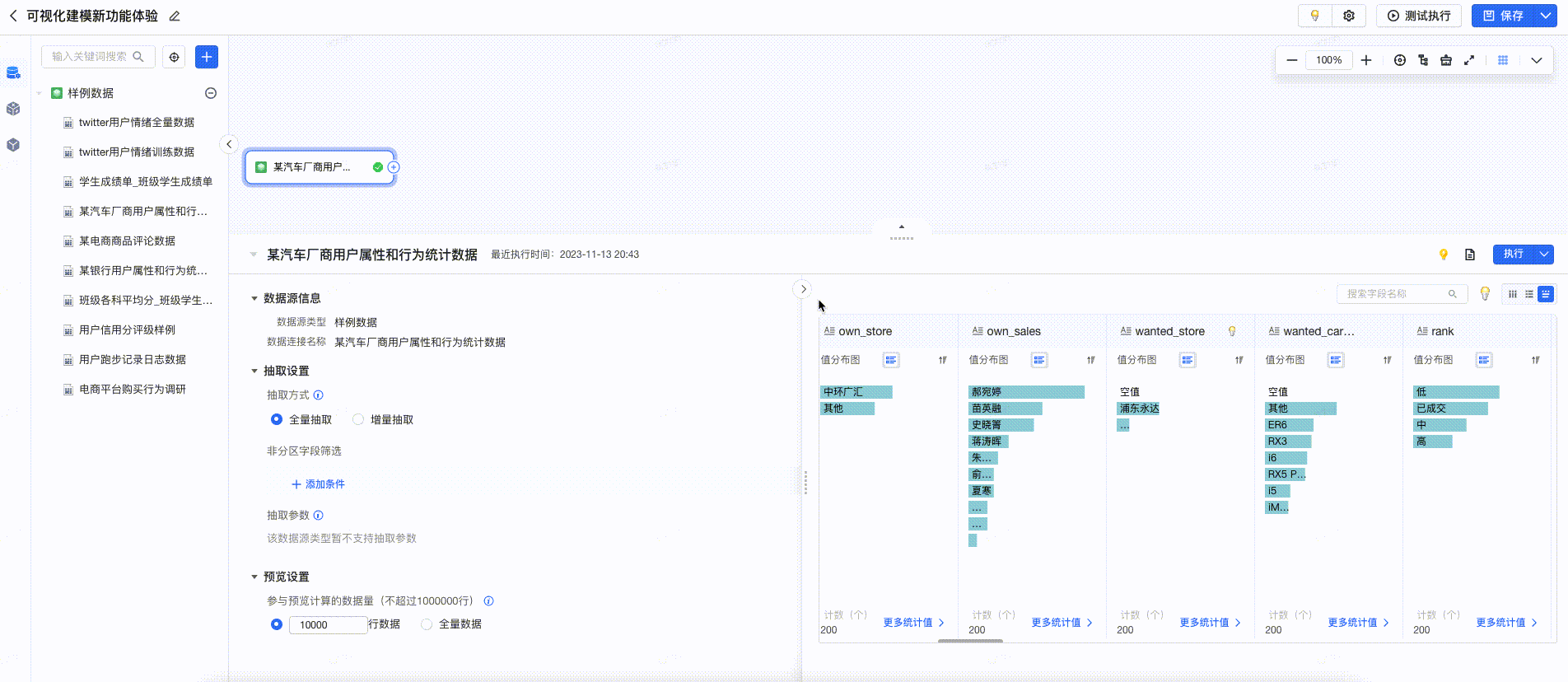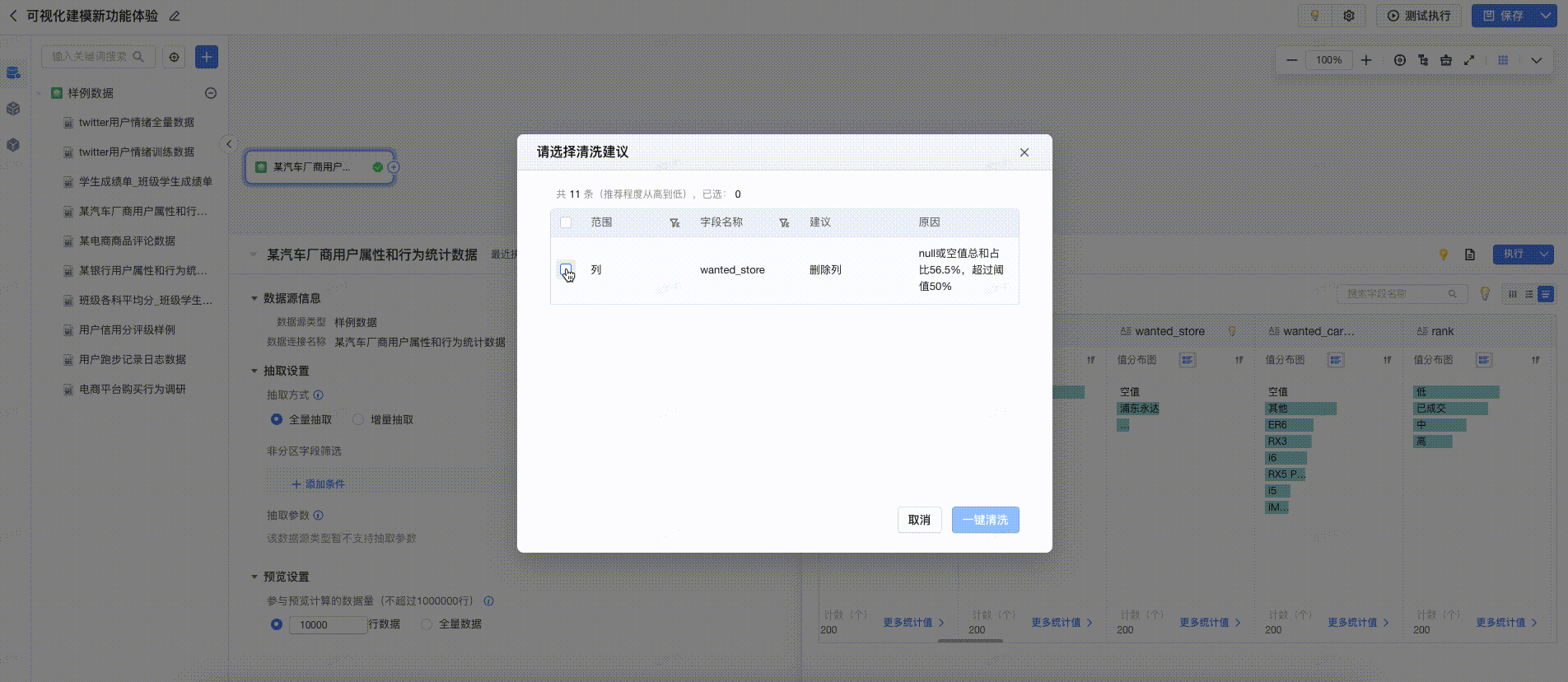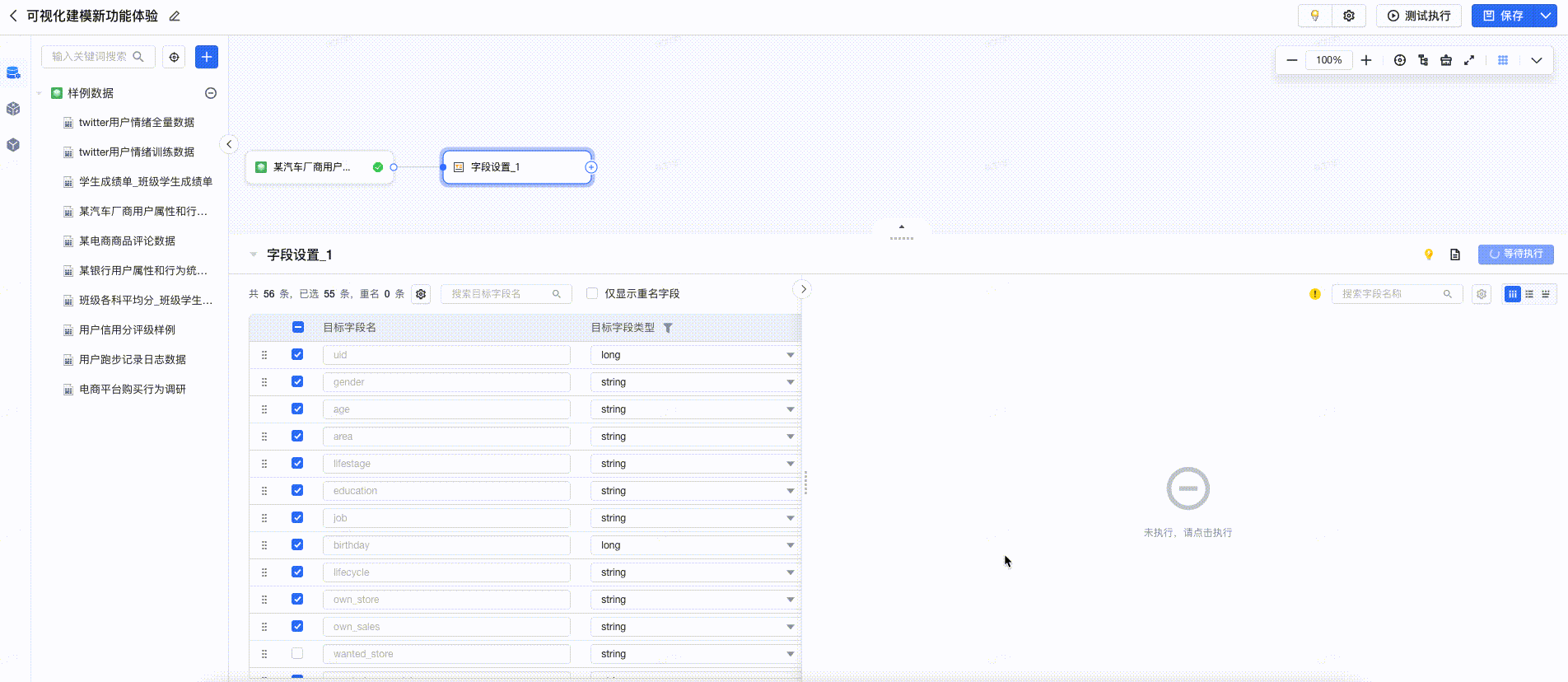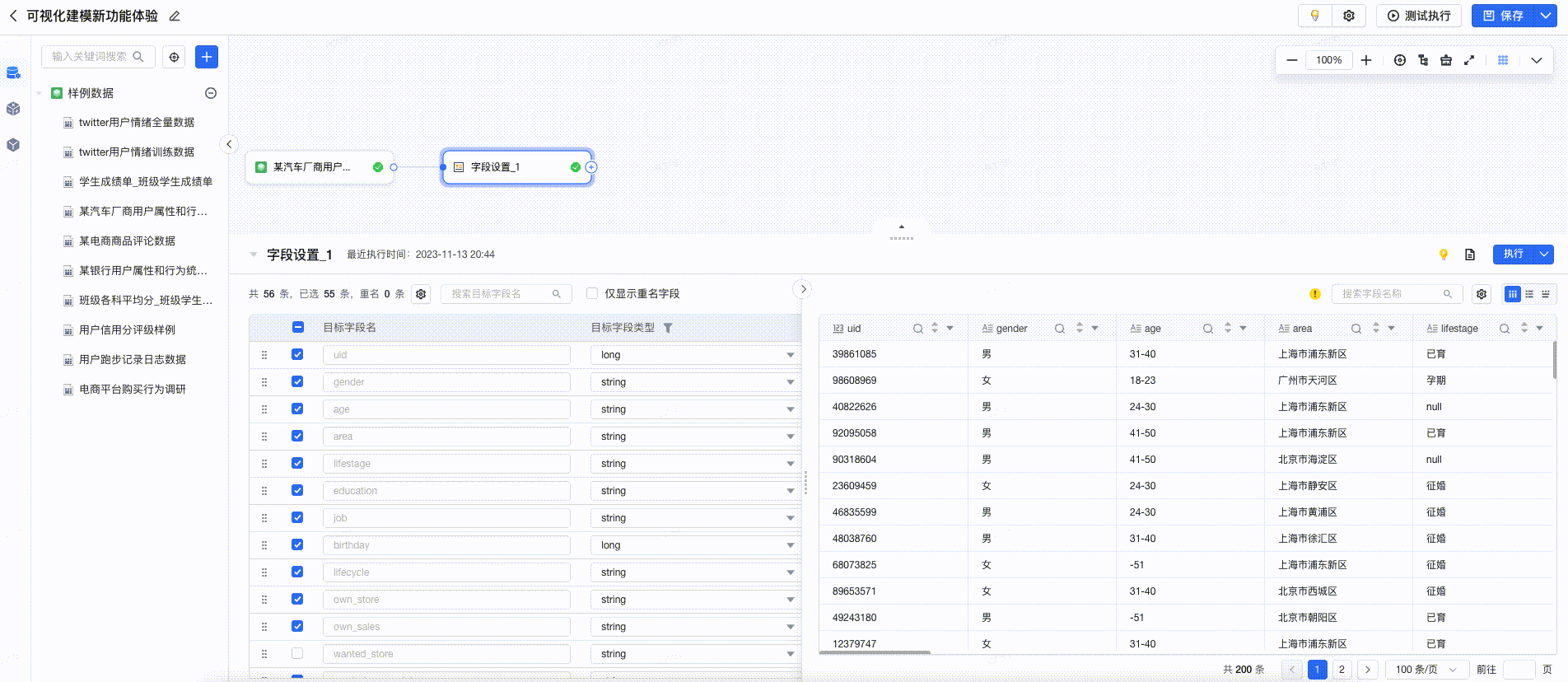
即时设置
在可视化建模任务的编辑页面,打开数据预览时,在预览界面左下方,可针对预览进行即时编辑或设置。用户可以配置参与预览计算的数据量(默认不超过1000000行),支持自定义行数或选择全量数据。配置后,预览将进行实时刷新。如下图所示: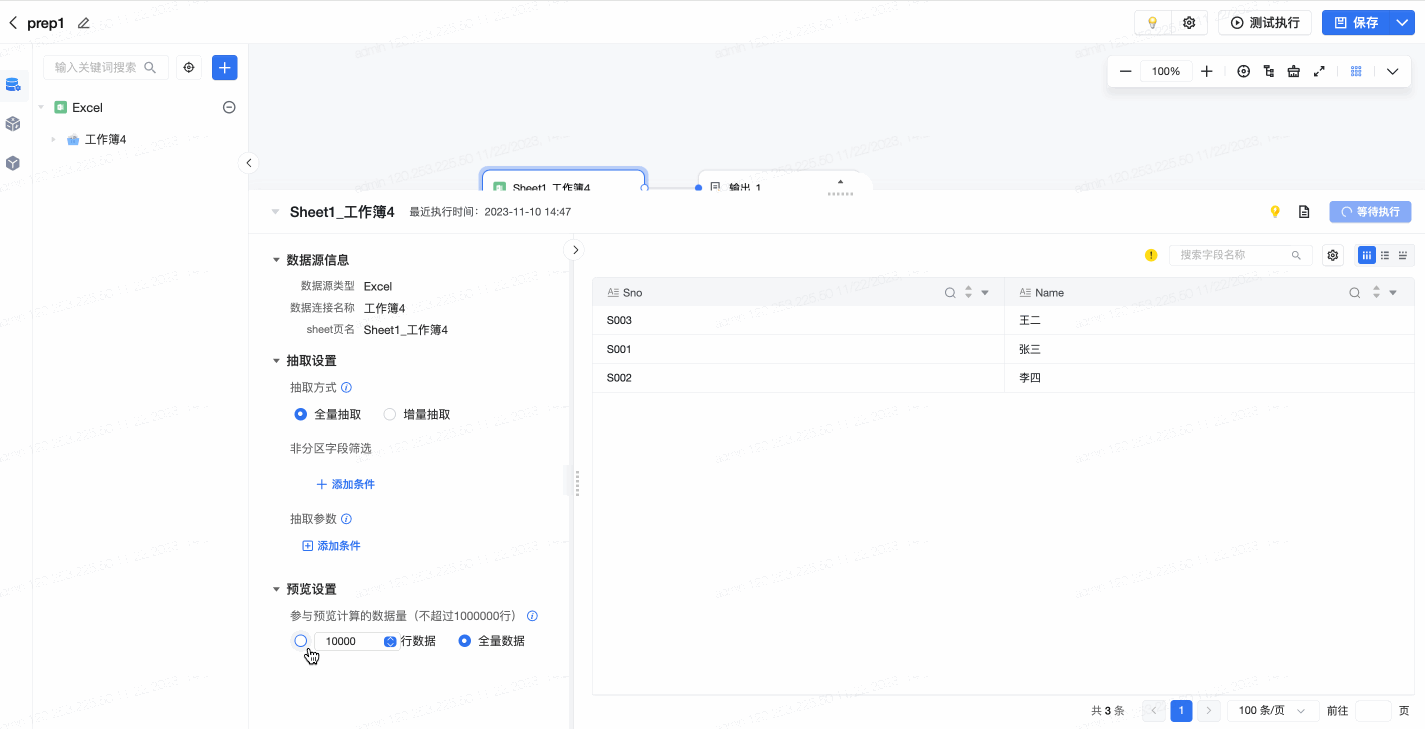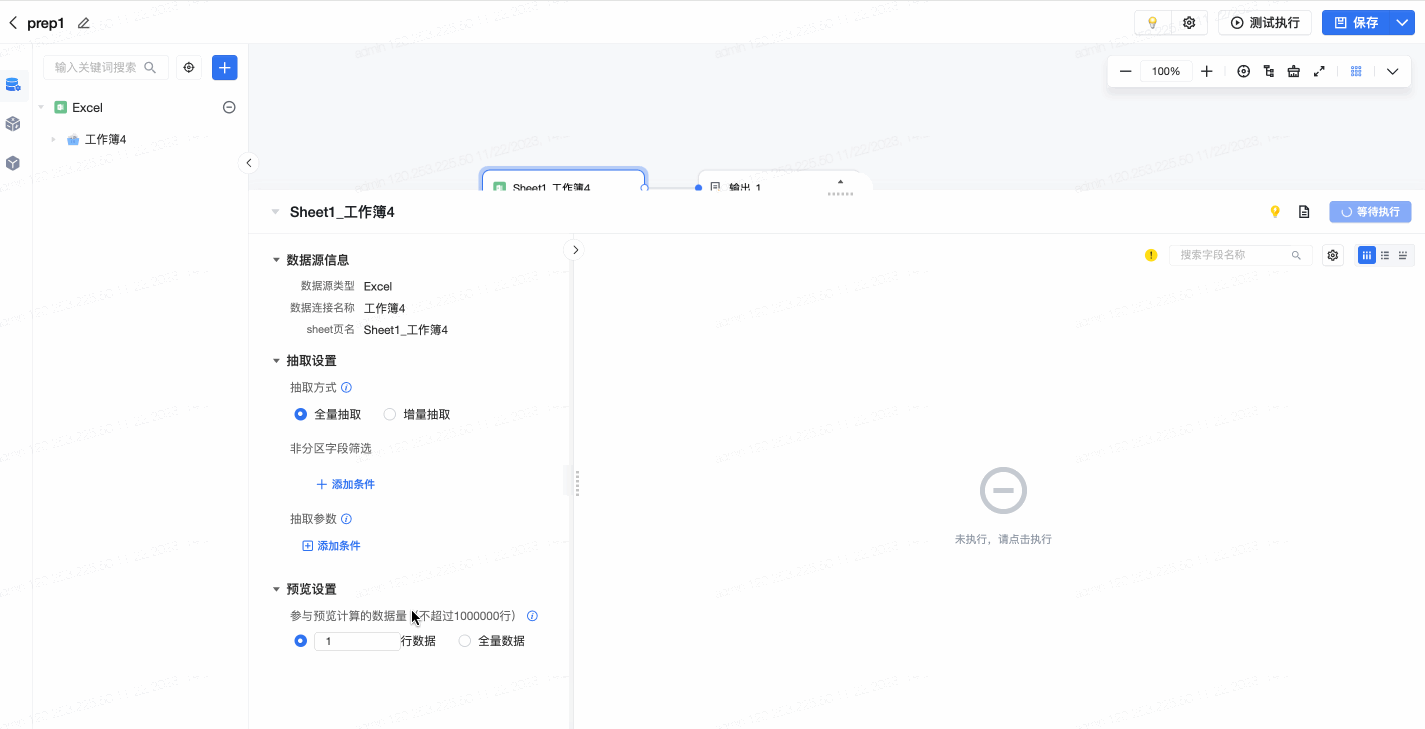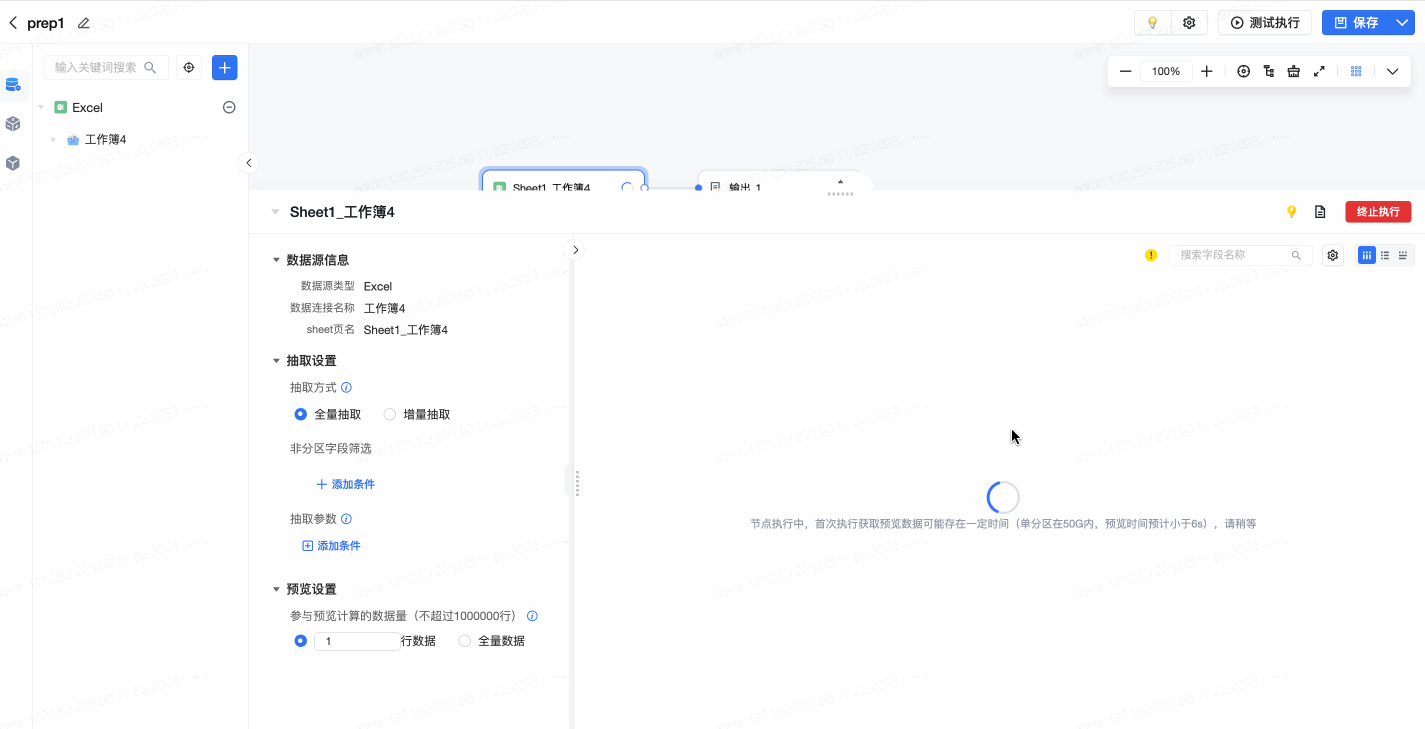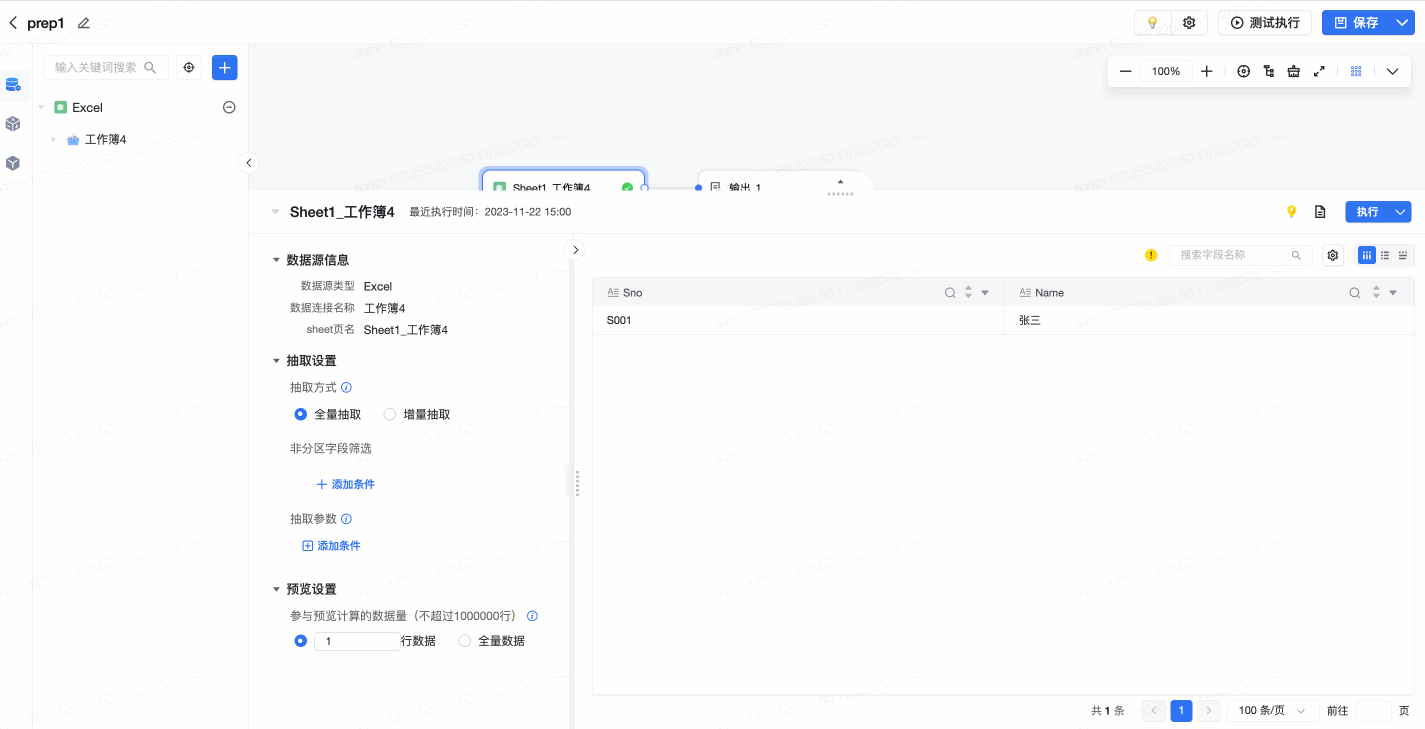
配置中可以选中某节点并运行节点,进行运行检查。需注意的是,当上游节点更改后,必须重新执行上游节点后才能执行当前及下游节点。
- 执行该节点:运行当前节点,需要上游节点均执行完成
- 执行到此处:依次运行上游未执行的节点和当前节点
- 从此处开始执行:依次运行当前节点和后续节点,需要上游节点均执行完成,一般在当前节点更改后使用
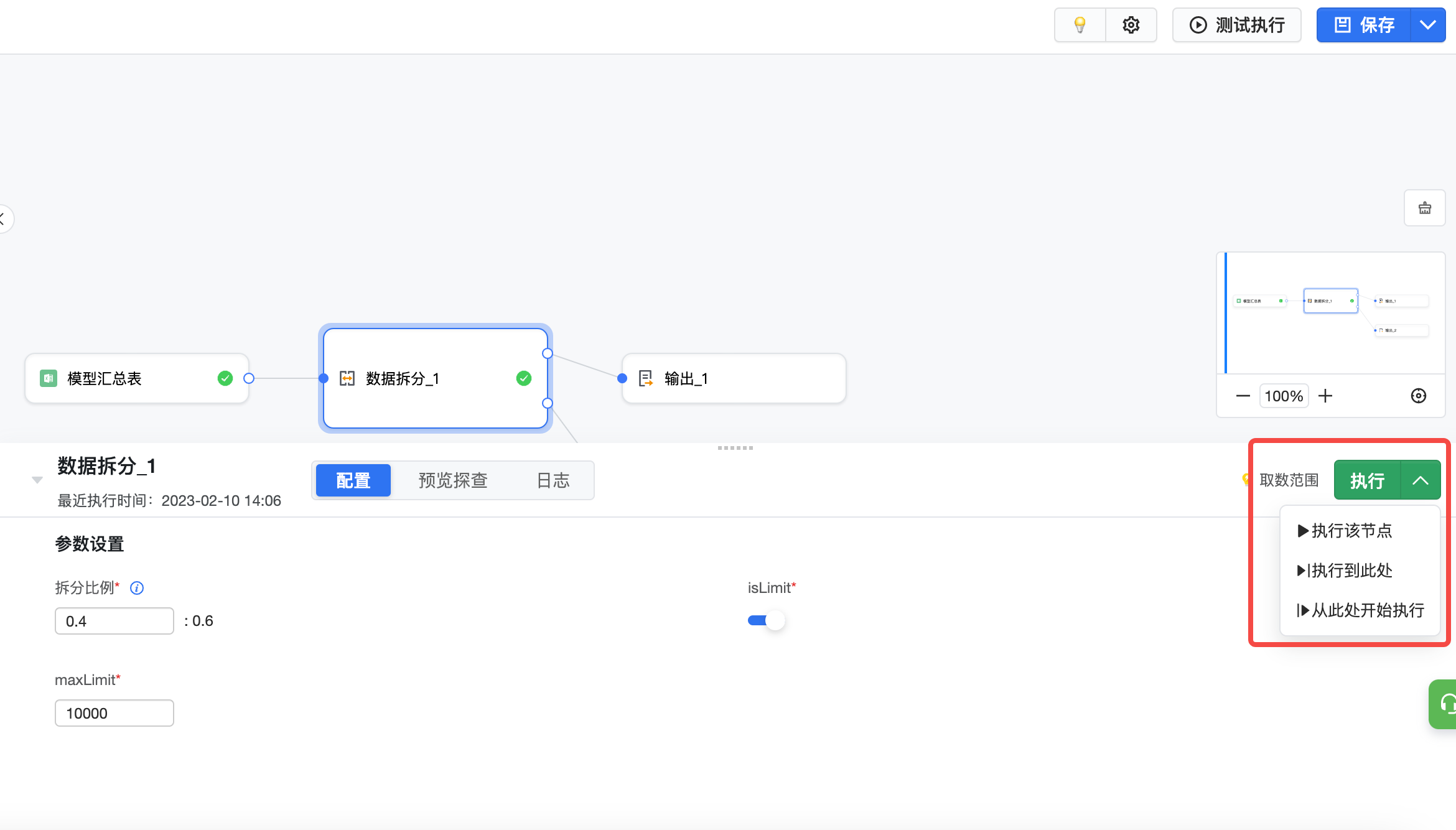
节点执行完成后,节点旁会有绿色对号标记,表示当前节点已完成执行。
添加输出节点,选择输出到已有数据集或新建数据集。关于输出数据集的细节设置,请查看数据输出。
已支持输出数据集:以Hive、ClickHouse、ByteHouse存储的数据集
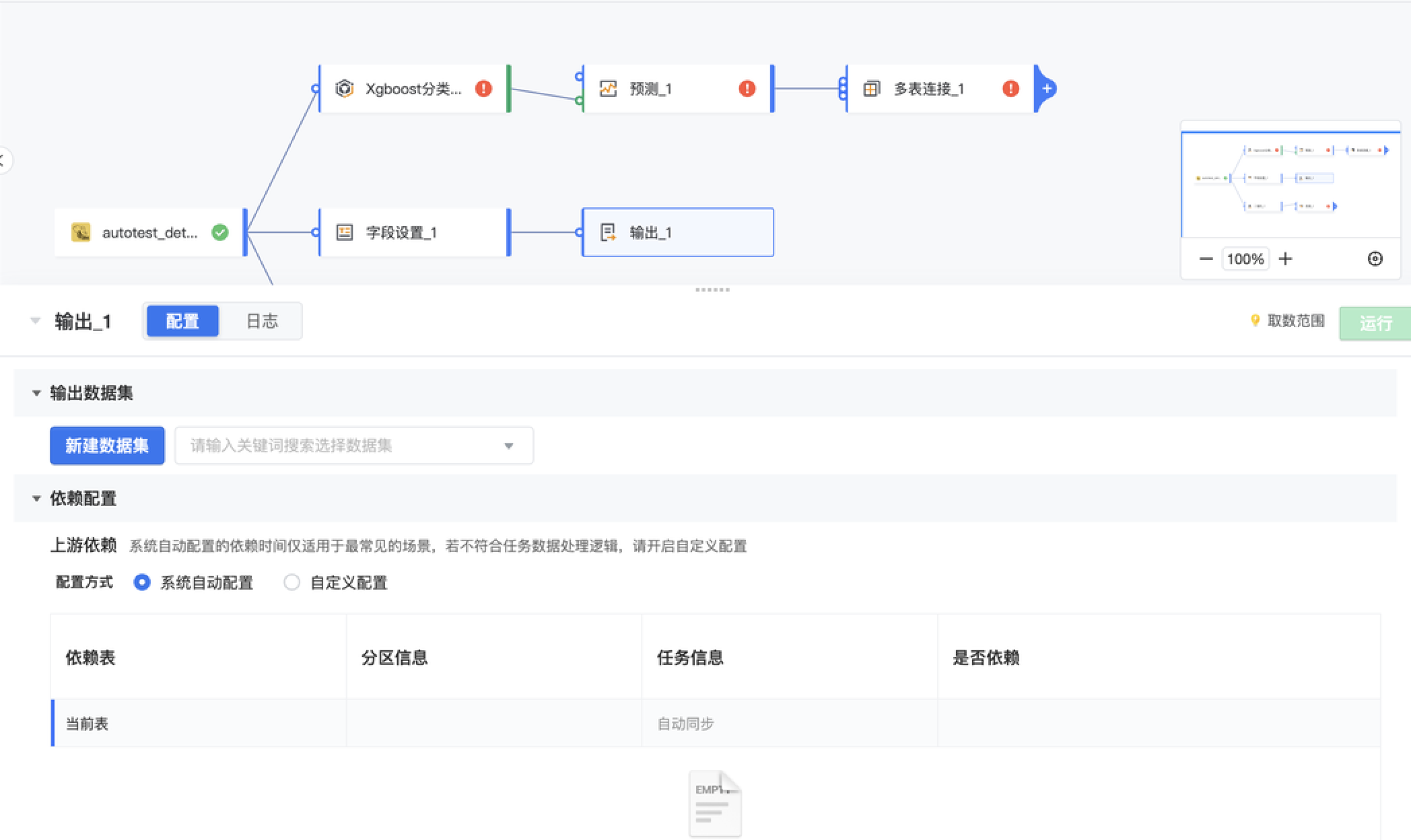
在可视化建模任务构建完毕后,可以点击「测试执行」,检验执行效果。
测试成功后,您可以打开「编辑任务信息」弹窗,设置任务名称、描述、路径以及运行类型。
相关参数配置说明如下:参数
配置说明
名称
可视化建模任务名称
描述
可视化建模任务描述,可包含任务目标、任务内容等信息
路径
可选择保存到某个任务列表文件夹中,方便后续查看
运行类型
可设置任务运行周期
- 手动运行:系统不会自动运行,需用户手动在任务列表中选择任务,点击运行
- 周期运行:系统自动按照设定周期自动运行可视化建模任务,无需用户手动运行
周期运行-运行频率提供两种设置方式,说明如下:
精确时间
间隔时长
- 包含小时级、天级、天级(按交易日历)、天级(按交易日历后一天)、周级、月级
- 支持设置多个时间,当选择多个时间,调度时执行多次,例如设置每天9点、10点两个时间,则任务每天执行两次
- 对呀天级(按交易日历)、天级(按交易日历后一天),支持选择交易日历类型,交易日历设置见火山引擎「系统配置」-「企业日历」-「标签管理」。
- 支持每10、20、30分钟执行一次
- 支持设置每日生效时间,需包含开始时间和结束时间,为空则生效时间为全天
注意
全量同步/大数据量同步使用分钟级同步将消耗大量资源,且性能不佳,请按需使用
注意
- 修改运行频率后,请检查输出-依赖配置(依赖信息等配置)是否需要进行相应修改。
- 保存任务-运行类型-运行频率中的交易日历及多次同步功能目前仅支持私有化部署V2.83.0及以上版本产品使用,如您需要使用该功能,请联系火山引擎产团队为您开通
模型配置完成时,可以点击右上角的保存或另存为。如果模型未完成,也可以将运行频率调整为手动运行后点保存或另存为。
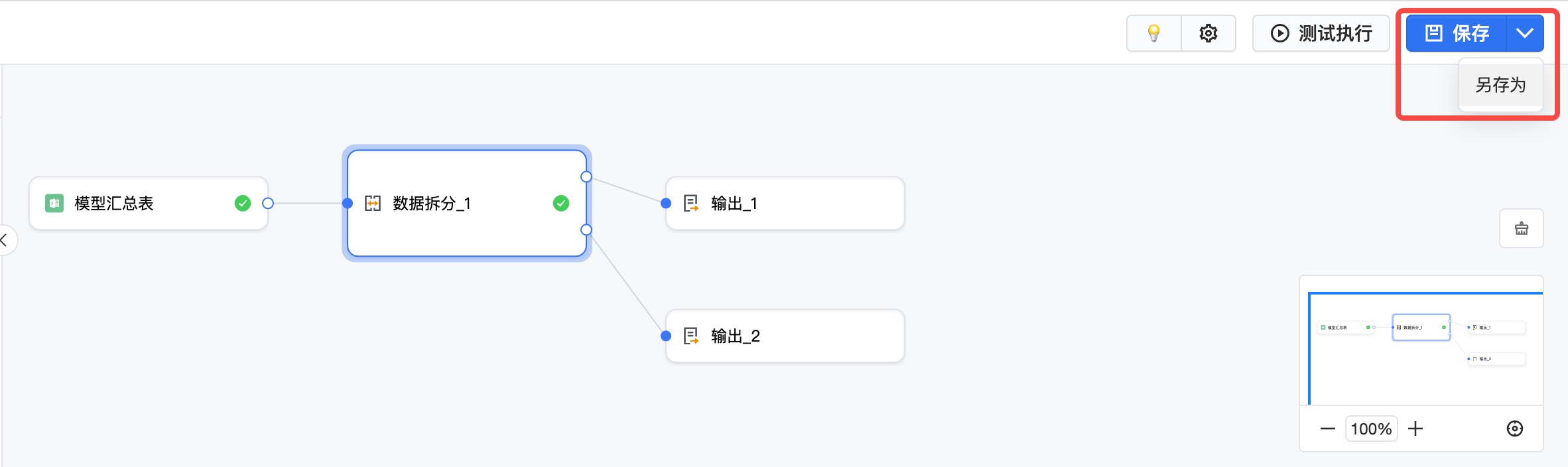
保存完任务配置,点击左上角返回可跳转到任务详情。
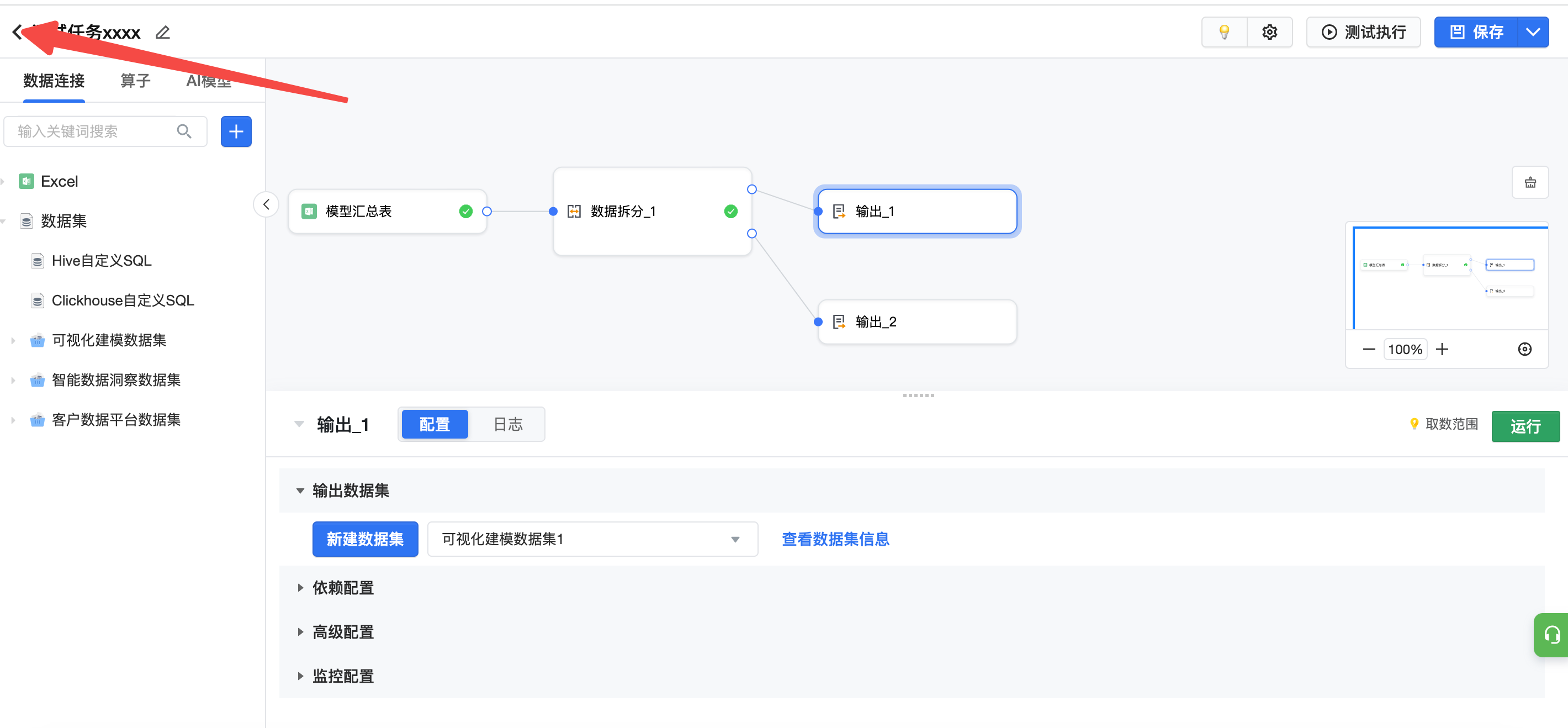
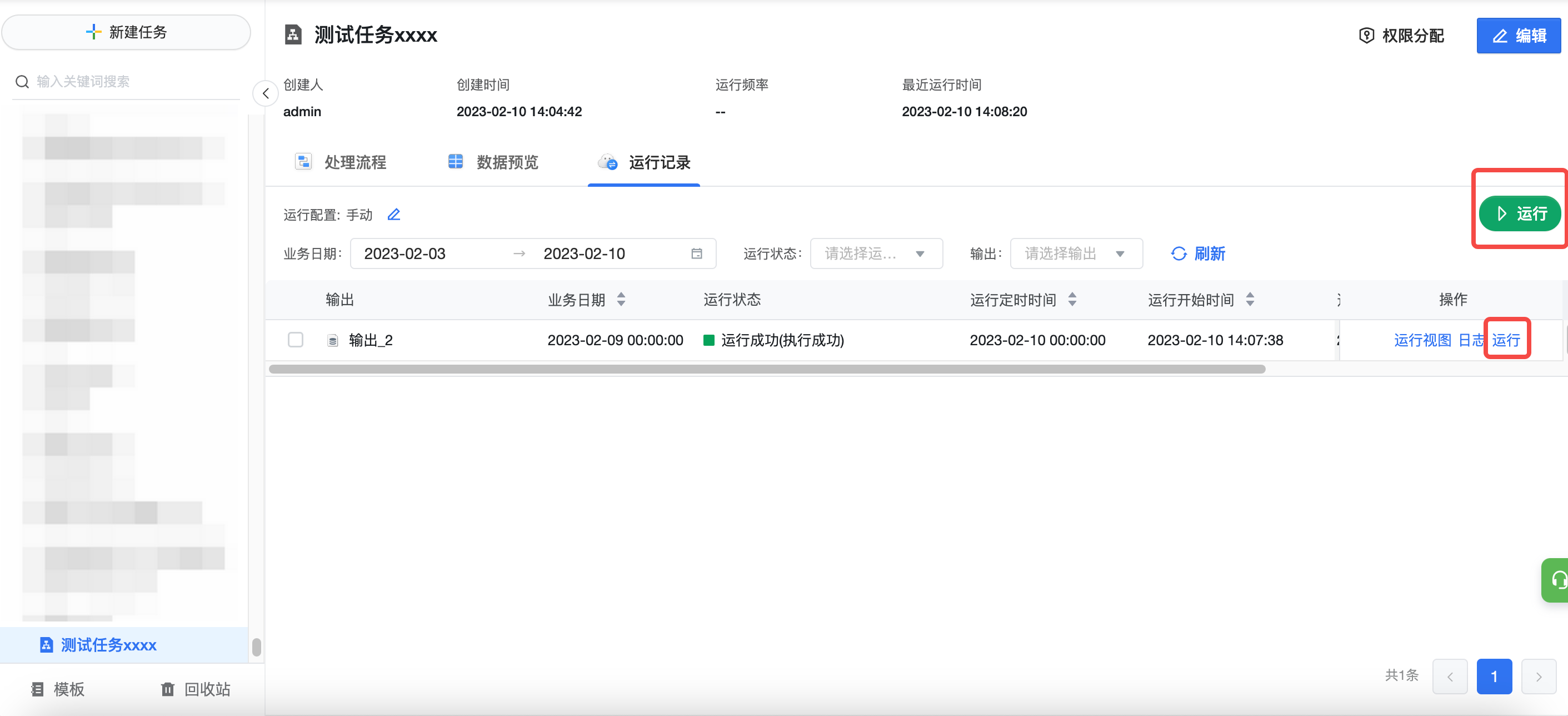
返回可视化建模页面,点击当前任务的「运行记录」,可以手动运行。更多任务管理能力,请查看任务管理。
在数据集详情及数据预览页面,点击「下载」可进行数据下载。其中,数据格式支持 CSV 与 Excel 两种格式。数据条数有 100 条、500 条、1000 条、5000 条、当前预览数据这几个预设选项,也支持自定义数据条数 。
说明
目前可视化建模模块仅提供离线任务,若您需要使用实时任务,数据源支持Kafka。(实时任务功能需同时购买DataWind 私有化版本、客户数据平台 CDP 和 Kafka,如您需要使用,请联系贵公司的商务人员或客户成功经理咨询购买事宜)。