E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南ImpalaImpala 概述
E-MapReduce组件操作指南ImpalaImpala 概述

Apache Impala 项目为存储在 Apache Hadoop 文件格式下的数据,提供了高性能、低延迟的 SQL 查询。它对查询进行快速响应,同时支持对分析查询进行交互式的数据探索和查询调整,而不是传统上那种与 SQL-on-Hadoop 技术相关联的长时间批量作业。
Impala 与 Apache Hive 数据库集成,在两个组件之间共享数据库和表。与 Hive 的高度集成,以及与 HiveQL 语法的兼容性,可以使用 Impala 或 Hive 创建表、发起查询、加载数据等。
1 Impala 优点
为了避免延迟,Impala 没有使用 MapReduce,而是使用 MPP 架构的分布式查询引擎直接访问数据。
Impala 相对于 Hadoop 上 SQL 查询,有以下几个优点:
支持 SQL 查询,快速查询大数据。
可以对已有数据进行查询,减少数据的加载,转换。
多种存储格式可以供您选择(Parquet, Text, Avro, RCFile, SequeenceFile)。
可以与 Hive 配合使用。
Impala的详细信息,请参见Apache Impala。
2 架构
火山引擎 E-MapReduce(EMR) 中 Impala 的架构如下图。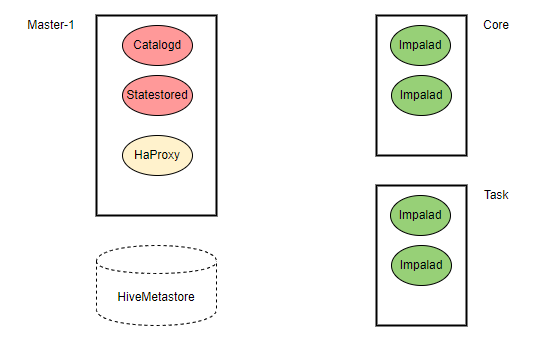
Impala组件如下:
组件 | 说明 |
|---|---|
Impalad | 部署在 Core 节点和 Task 节点,允许扩容和缩容。 |
Statestored | 部署在 Master 节点的 master-1 机器。 |
Catalogd | 部署在 Master 节点的 master-1 机器。 |
HaProxy | 部署在 Master 节点的 master-1机器。 |