E-MapReduce
E-MapReduce



组件与 API 参考
请输入


CLI 参考
API 参考
EMR on ECS API参考
集群管理
节点组管理
用户管理
用户组管理
应用管理
EMR on VKE API参考
组件操作指南
Celeborn
DolphinScheduler
HBase
Hive
Iceberg
Knox
Lance
Livy
MapReduce2
OpenLDAP
Phoenix
Proton
基础使用
高阶使用
Ranger
Ray
RayCluster 使用
Spark
StarRocks
数据湖分析
最佳实践
Tez
YARN
- 文档首页
 E-MapReduce组件操作指南Ranger组件集成Spark集成
E-MapReduce组件操作指南Ranger组件集成Spark集成

Spark集成
在 Ranger 中,Spark 和 Hive 共用一套 policy 都是 HADOOP SQL -> default_hive,所以具体的配置可以直接参考 Hive集成。
1 使用前提 #
- 已创建 E-MapReduce(EMR)包含 Ranger 服务的集群,操作详见:创建集群。
- Ranger UI 的登录界面操作,详见:Ranger 概述---Ranger Admin UI 访问。
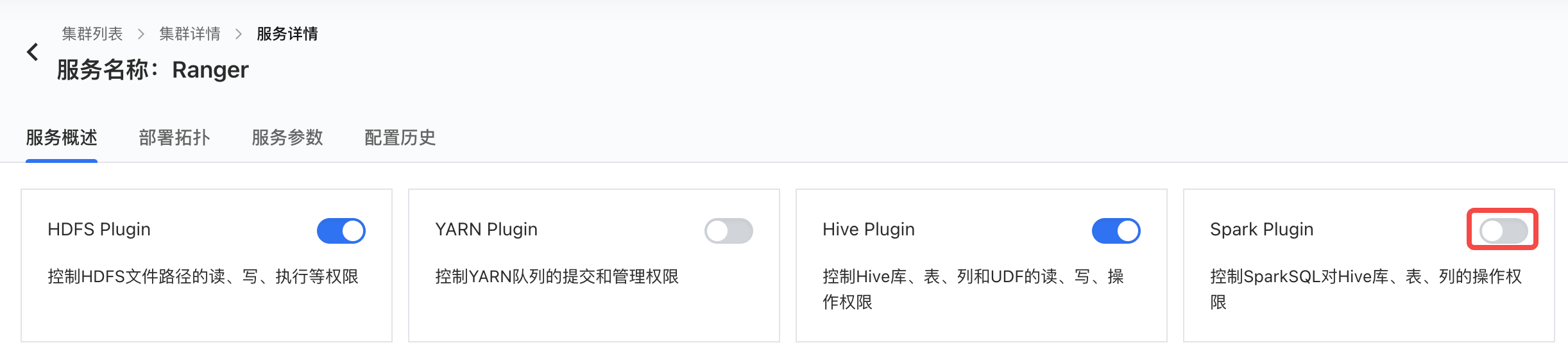
2 启用 Ranger Spark Plugin #
注意
当前版本ranger-spark-plugin不适用于spark-submit等非交互式场景,会导致任务无法退出,如需要执行spark-submit任务,请关闭ranger-spark-plugin,如有疑问可通过 提工单 的方式,联系火山引擎技术支持人员。
- 集群详情 -> 服务列表 -> Ranger 服务详情 -> 服务概述页面,点击启用 Spark Plugin 开关。
- 按照提示重启 Spark 服务后生效。
3 Beeline 访问 #
Spark的使用方法详见 EMR Spark 快速开始
# spark 3.x beeline -u jdbc:hive2://emr-master-1-1:10005 -n <user> -p <password> # spark 2.x spark-beeline -u jdbc:hive2://emr-master-1-1:10016 -n <username> -p <password>
说明
不同 EMR 版本中节点的域名命名方式可能不同,所以上方“emr-master-1-1”可参考 EMR 的域名规则做相应调整。
最近更新时间:2024.09.13 11:34:49
这个页面对您有帮助吗?
有用
有用
无用
无用