E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce快速入门EMR on ECS 快速入门创建并运行作业
E-MapReduce快速入门EMR on ECS 快速入门创建并运行作业

本文将为您介绍如何通过火山引擎 E-MapReduce(EMR),在已创建的集群上创建并执行作业。
1 前提条件
- 已创建 EMR-Hadoop 的集群类型,详见创建集群。
- 需要在集群详情 > 访问链接 > 快速配置服务端口中,给源地址和对应端口添加白名单才可继续访问。
2 创建并运行作业
下文将通过三种作业提交方式,来创建并运行作业:
- 通过 EMR 内置开源组件 HUE 服务,进行作业提交并执行。
- 使用本地终端工具命令行工具,进行作业提交并执行。
- 通过开通一站式大数据研发治理套件(DataLeap),通过可视化方式完成作业开发。
2.1 通过 HUE 组件服务创建作业
- 登录 EMR 控制台。
- 在左侧导航栏中,进入集群列表 > 集群名称详情 > 访问链接, 点击 HUE UI 访问链接进入。
注意
若访问链接不能点击,请检查 Hue 所在 ECS 实例是否绑定弹性公网IP,详见访问链接。
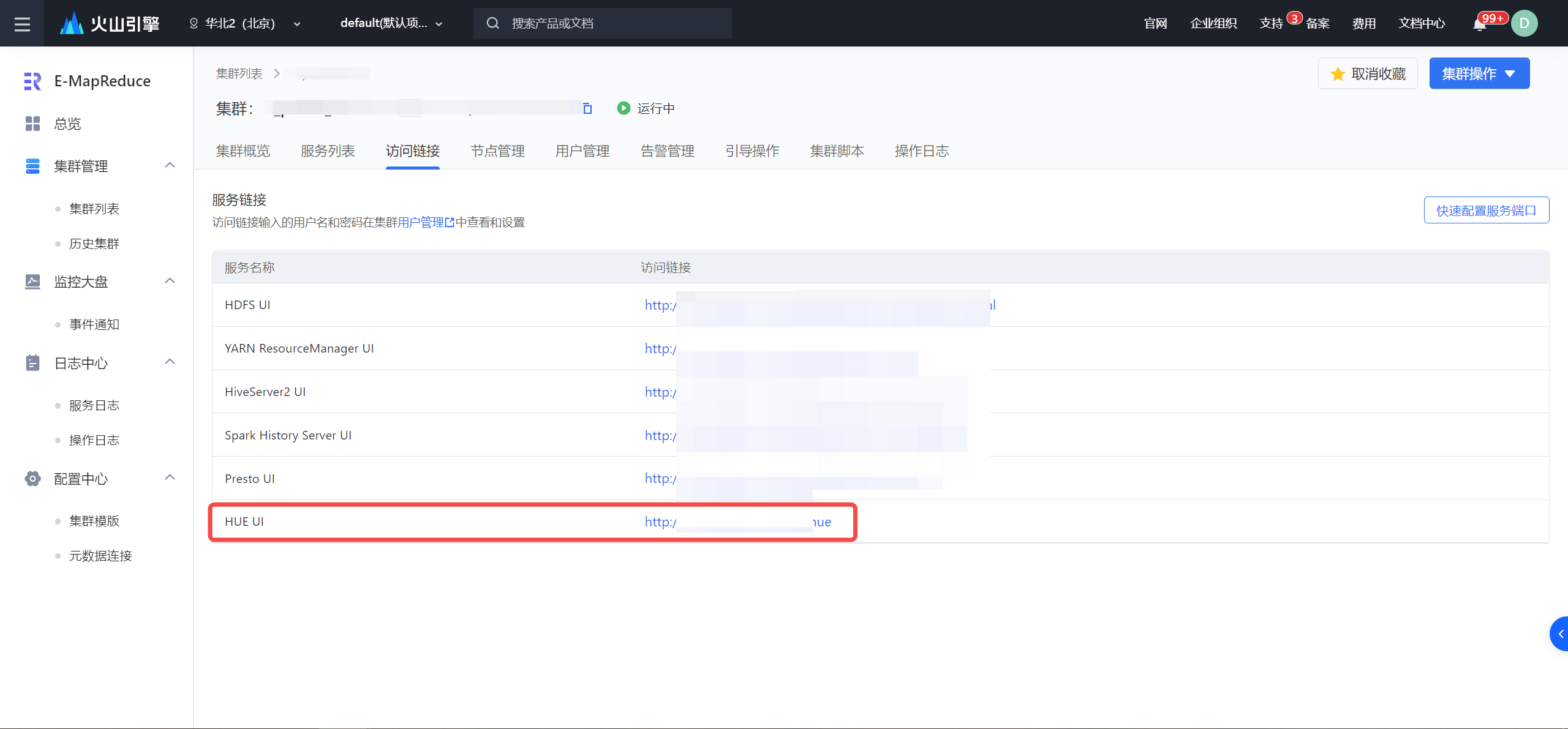
- 在窗口输入 Hue 登录的用户名和密码。
说明
- Hue 已默认接入了 LDAP 鉴权,用户可使用 LDAP 中已有账号进行登录。首次登录需先添加用户,详细操作请参考:1 用户管理。
- 进入 Hue 界面后,您可进行后续的创建作业并运行,具体实践详见 通过hue进行数据查询。
2.2 登陆命令行创建作业
获取 master 实例节点的公网 IP 地址:
- 登录 EMR 控制台。
- 在左侧导航栏中,进入集群列表 > 集群名称详情 > 服务列表 > Spark > 展开 Spark Client,获取公网 IP 信息。
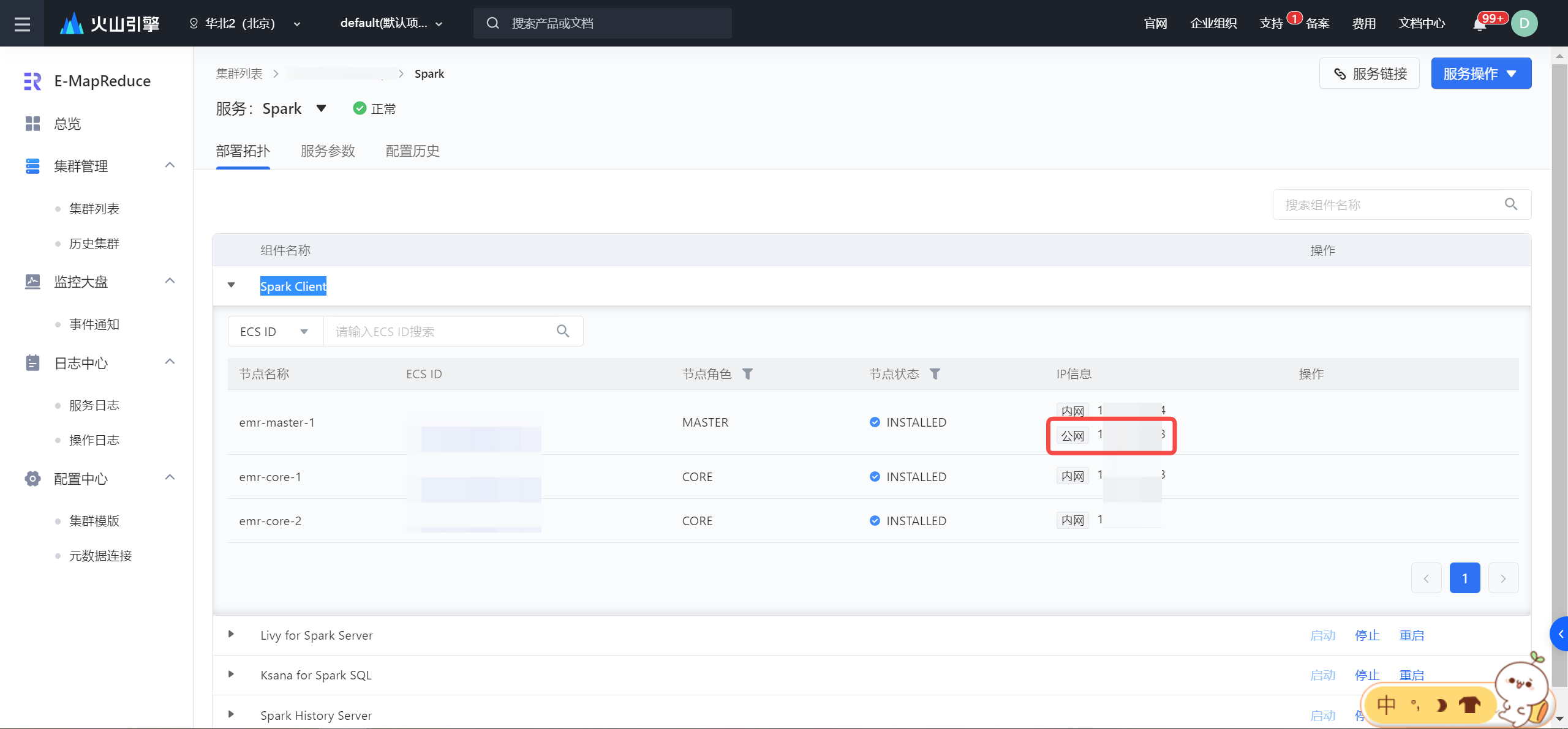
在本地使用终端工具命令行 SSH 方式运行如下命令登录主节点:ssh root@[主节点公网IP地址]。详见登陆集群。
使用命令行方式进行 SPARK 作业提交:
说明
Spark Jar 资源,在不同集群版本中,镜像路径会不一致,其余集群版本可根据实际情况进行替换。更多版本操作详见 Spark-快速开始。
以下提交命令,以 3.X 集群版本为例。命令中spark-examples_2.12-3.2.1.jar为集群中对应的JAR包名称。用户可登录集群,在/opt/apps/SPARK3/spark-current/examples/jars路径下查看对应的JAR包名称。spark-submit --class org.apache.spark.examples.SparkPi --master yarn --num-executors 3 --driver-memory 512m --executor-memory 512m --executor-cores 1 /usr/lib/emr/current/spark/examples/jars/spark-examples_2.12-3.2.1.jar部分重要任务参数说明如下:
参数
样例
备注
driver-memory
512m
driver程序使用的内容,最大不可超过该节点的总内存资源
num-executors
3
并行executor个数
executor-memory
512m
单个executor使用的内存大小,最大不可超过该节点的总内存资源
executor-cores
1
单个executor的并行数
class
org.apache.spark.examples.SparkPi
程序入口类
master
yarn
程序执行模式,可选yarn,yarn-client
完成作业提交后,您可通过 YARN UI 访问链接查看作业运行状态和历史作业记录:
- 进入集群列表 > 集群名称详情 > 访问链接 > YARN ResourceManager UI,单击访问链接进入 YARN UI 界面,详见访问YARN UI。
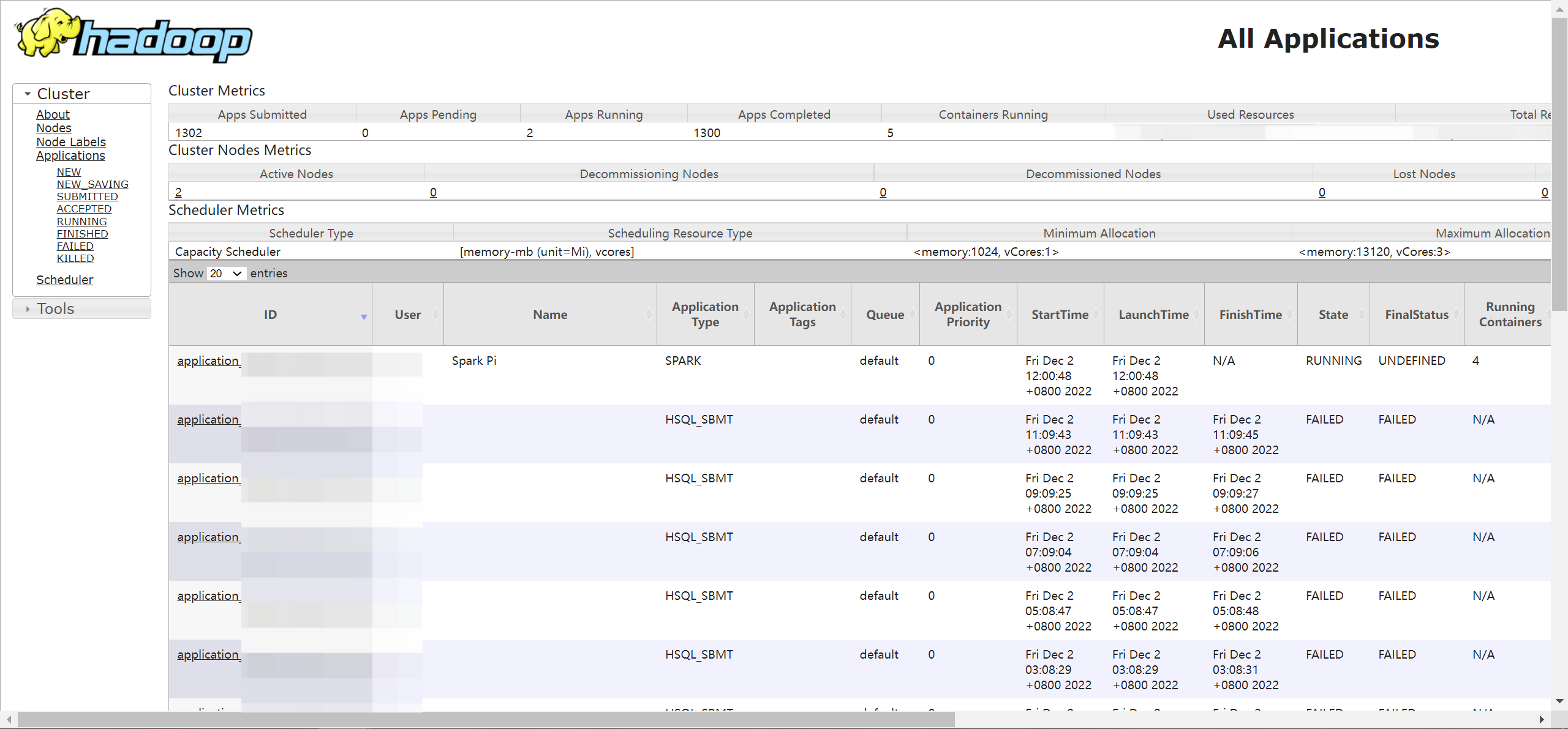
- 进入集群列表 > 集群名称详情 > 访问链接 > YARN ResourceManager UI,单击访问链接进入 YARN UI 界面,详见访问YARN UI。
2.3 通过 DataLeap 创建作业
一站式大数据研发治理套件(DataLeap),帮助您快速完成数据集成、数据开发、运维、治理、安全等全套数据中台建设,来帮助企业提升数据研发效率,降低运维管理成本。DataLeap 项目可通过绑定 EMR 引擎实例的方式,来创建 EMR 作业并运行。
使用租户主账号开通 DataLeap 产品,并授予云资源相应角色权限。详见开通服务。
进入 DataLeap 控制台,在左侧导航栏中单击项目管理 > 创建项目,进行项目创建。
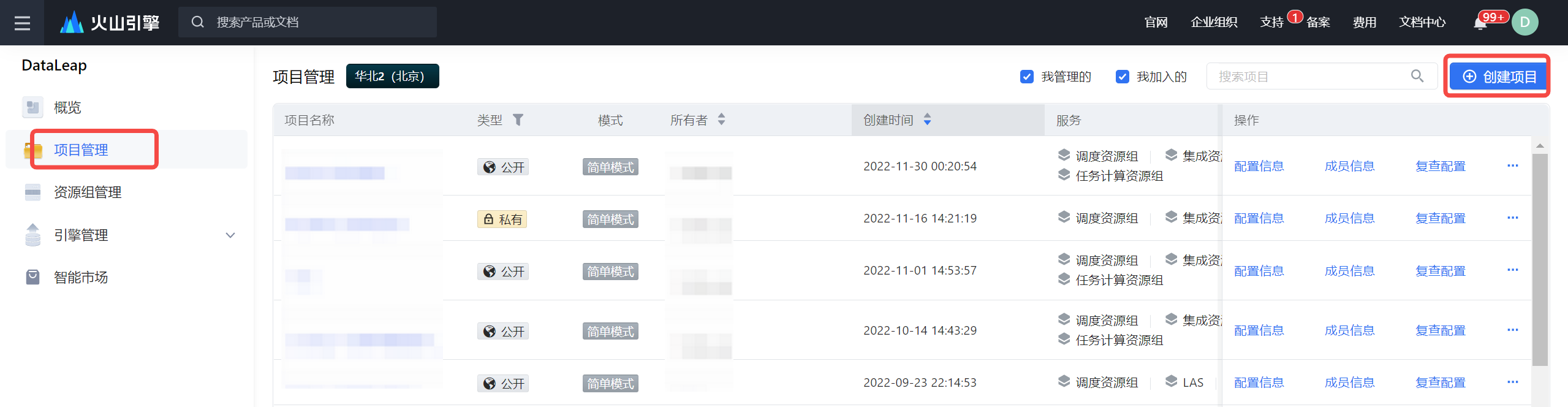
在创建项目界面,完成项目基础信息、项目管控、服务绑定等配置信息。
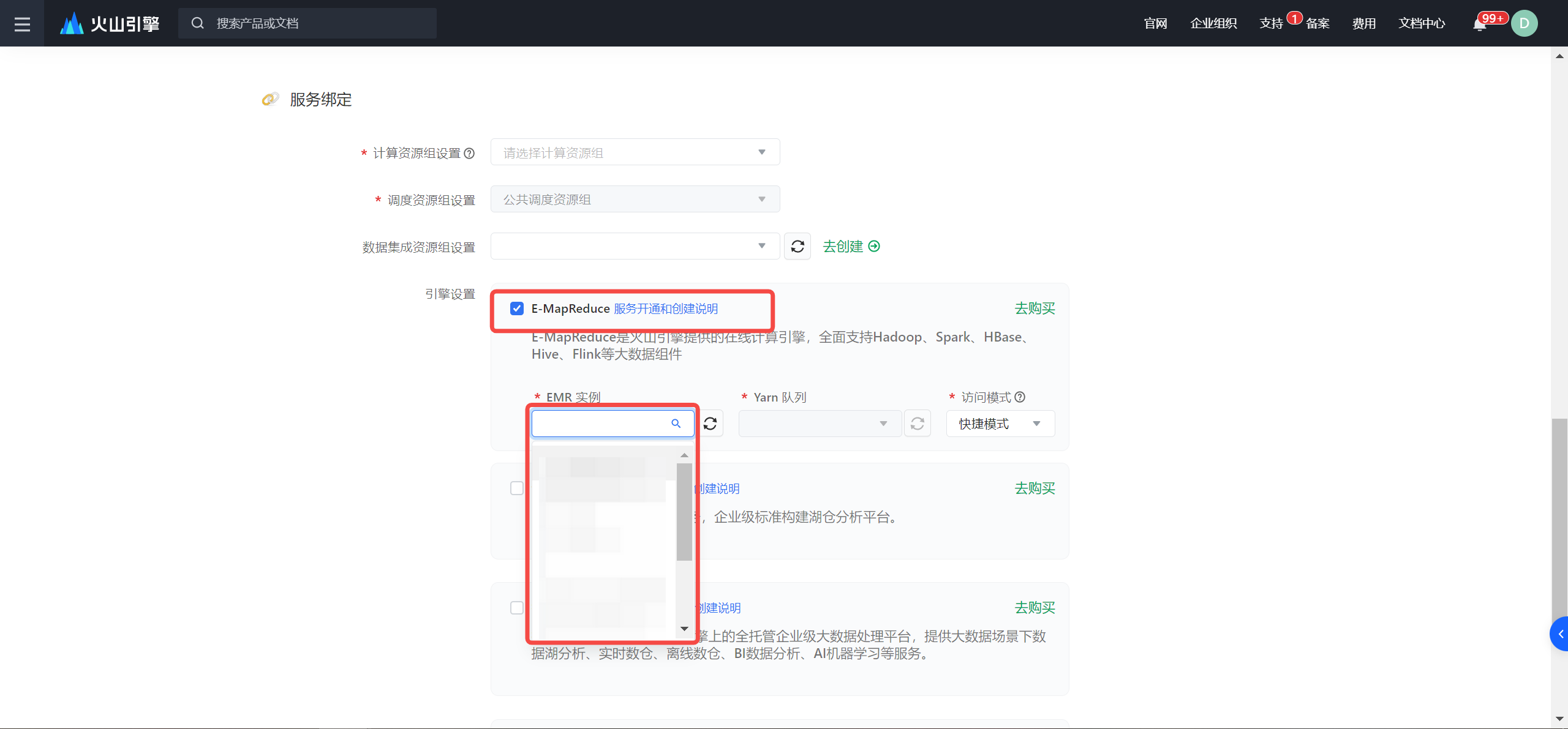
其中,在服务绑定-引擎绑定项,您需勾选 E-MapReduce 引擎服务,并在下拉框中,选择已创建的集群名称信息。其余配置信息,详见新建项目。注意
EMR 实例首次绑定 DataLeap 项目时,需打开 EMR 实例所在安全组的访问权限,方可继续选择 Yarn 队列。详见如何开放EMR实例所在安全组的访问权限?
项目创建完成后,您可以在 DataLeap 控制台上进行 EMR 作业的数据开发、任务运维监控、元数据采集等相关操作。完整详见 DataLeap on EMR 快速入门。
相关模块功能描述如下,详见各功能指导文档:模块
描述
指导文档
数据开发
您可以根据实际业务场景,选择创建合适的 EMR 节点类型进行作业开发。
任务运维
提供线上任务的管理运维操作,支持离线、流式的任务运维;通过配置监控规则,实现对任务运行状态的监控。
数据质量
提供对离线、流式数据产出表的数据质量监控。
通过配置模板规则、自定义规则方式,来监控表数据量、数据个性化指标的波动及异常报警,数据内容探查及差异对比等能力,保证了数据在生产及使用流程中的可靠性和合理性,从而避免因为数据质量问题而导致数据失信、决策失误。数据地图元数据
通过元数据采集方式可视化管理 EMR 元数据,您可以在数据地图中查看 EMR 表数据、血缘图谱等。