E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南FlinkFlink SQL Client 使用参考
E-MapReduce组件操作指南FlinkFlink SQL Client 使用参考

Flink 官方提供的 SQL 客户端可以支持编写 SQL、调试和提交 Flink 任务到 Flink 集群上的功能,具体使用操作,可参考Flink官方文档。
本文将额外介绍几种火山引擎 E-MapReduce(EMR)Flink 的使用场景。
1 Flink SQL Client 运行模式
在火山 EMR Flink 下,我们可以通 SQL 客户端将 Flink SQL 任务提交到 standlone 集群或者 Yarn 集群。
1.1 Standlone 集群场景
Standlone 场景下需要先启动一个 Standlone 的集群,可在FLINK_HOME目录(默认为/usr/lib/emr/current/flink)下运行以下命令创建:
./bin/start-cluster.sh
Standlone 集群启动成功后,可以执行以下命令启动 SQL 客户端命令行界面:
./bin/sql-client.sh embedded
如果想停止 Standlone 集群,可执行以下命令停止:
./bin/stop-cluster.sh
1.2 Yarn 集群场景
Yarn 集群场景下支持多种 Flink 任务提交模式,包括 Yarn-Session 模式,Per-Job Cluster 模式,Application 模式。
Flink SQL Client 暂不支持 Application模式
1.2.1 Session 模式
Session 模式下,需要先执行以下命令启动 Yarn Session:
./bin/yarn-session.sh -d
Yarn Session 启动成功后,会创建一个/tmp/.yarn-properties-root文件,记录最近一次提交到 Yarn 的 Application ID,执行以下命令启动 SQL 客户端命令行界面,后续指定的 Flink SQL 会提交到之前启动的 Yarn Session Application。
./bin/sql-client.sh embedded -s yarn-session
可以执行以下命令停止当前启动的 Yarn Session
cat /tmp/.yarn-properties-root | grep applicationID | cut -d'=' -f 2 | xargs -I {} yarn application -kill {}
1.2.2 Per-Job Cluster 模式
Per-Job Cluster 模式无需提前启动集群,可以在启动 SQL 客户端命令行界面,设置execution.target,后续提交的每一个 Flink SQL 任务将会作为独立的任务提交到 Yarn。
说明
yarn-per-job 模式已经在 Flink 1.16 被标记为 deprecated 状态。
./bin/sql-client.sh embedded Flink SQL> set execution.target=yarn-per-job; [INFO] Session property has been set.
也可以通过在flink-conf.yaml文件预定义配置改参数
# flink-conf.yaml execution.target: yarn-per-job
2 Flink SQL 集成 TOS
火山 EMR Flink 支持多种方式对 TOS 对象存储进行读写操作,比如基于Hive Connector,Hudi Connector等。
2.1 Flink SQL 集成 Hive Connector
以下以 yarn-session 模式为例,显示如何集成 Hive Connector。
- 启动 SQL 客户端命令行界面
./bin/yarn-session.sh -d ./bin/sql-client.sh embedded -s yarn-session -j connectors/flink-sql-connector-hive-3.1.2_2.12-1.16.1.jar
- 创建 Hive Catalog 以及 Demo 数据库
Flink SQL> CREATE CATALOG hive WITH ( > 'type' = 'hive', > 'hive-conf-dir' = '/etc/emr/hive/conf' > ); [INFO] Execute statement succeed. Flink SQL> use catalog hive; [INFO] Execute statement succeed. Flink SQL> create database demo_db; [INFO] Execute statement succeed. Flink SQL> show databases; +---------------+ | database name | +---------------+ | default | | demo_db | +---------------+ 3 rows in set
- 建表
可以通过其它引擎创建 Hive 表,比如 Spark、Hive 等,也可以在 Flink SQL 客户端切换到 Hive Dialect 模式。
- Spark 引擎建表
# 启动Spark SQL命令行交互界面 spark-sql spark-sql> CREATE TABLE demo_tbl1 ( > uuid STRING, > name STRING, > age INT, > ts TIMESTAMP > ) > PARTITIONED BY (`partition` STRING); Time taken: 0.652 seconds spark-sql> desc formatted demo_tbl1; uuid string name string age int ts timestamp partition string # Partition Information # col_name data_type comment partition string # Detailed Table Information Database demo_db Table demo_tbl1 Created Time Fri Nov 25 15:04:43 CST 2022 Last Access UNKNOWN Created By Spark 3.2.1 Type MANAGED Provider hive Comment Table Properties [bucketing_version=2, sink.partition-commit.policy.kind=metastore, transient_lastDdlTime=1669359883] Location tos://xxxxx-v2/hms-warehouse/demo_db.db/demo_tbl1 Serde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe InputFormat org.apache.hadoop.mapred.TextInputFormat OutputFormat org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat Storage Properties [serialization.format=1] Partition Provider Catalog Time taken: 0.085 seconds, Fetched 25 row(s)
- Flink Hive Dialect 建表
从 Flink 1.16 开始,如果要使用 Hive Dialect 模式,需要对 Flink 系统部分 Jar 依赖进行调整,详情参考 官方文档,可执行以下命令进行依赖 Jar 包准备。
# 进入FLINK_HOME mv lib/flink-table-planner-loader-1.16.1.jar opt/ cp opt/flink-table-planner_2.12-1.16.1.jar lib/ cp connectors/flink-sql-connector-hive-3.1.2_2.12-1.16.1.jar lib/
依赖 Jar 包调整之后,需重启 yarn-session 以及 sql-client,建表内容如下:
./bin/sql-client.sh embedded -s yarn-session Flink SQL> set table.sql-dialect=hive; [INFO] Session property has been set. Flink SQL> CREATE CATALOG hive WITH ( > 'type' = 'hive', > 'hive-conf-dir' = '/etc/emr/hive/conf' > ); [INFO] Execute statement succeed. Flink SQL> use catalog hive; [INFO] Execute statement succeed. CREATE TABLE `hive`.`demo_db`.`demo_tbl2` ( uuid STRING, name STRING, age INT, ts TIMESTAMP ) PARTITIONED BY (`partition` STRING) LOCATION 'tos://{bucket_name}/hms-warehouse/demo_db.db/demo_tbl2' TBLPROPERTIES ( 'sink.partition-commit.policy.kind'='metastore' );
建议非 hive dialect 场景,不要将 connector 的 Jar 包依赖放入 lib 目录下。
- 读写数据
- 批式读写数据
Flink SQL> SET 'execution.runtime-mode' = 'batch'; # 建议配置flink-conf.yaml中 [INFO] Session property has been set. Flink SQL> INSERT INTO `hive`.`demo_db`.`demo_tbl1` VALUES > ('id21','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), > ('id22','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), > ('id23','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), > ('id24','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), > ('id25','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), > ('id26','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), > ('id27','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), > ('id28','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4'); [INFO] Submitting SQL update statement to the cluster... Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau'; # 建议配置在flink-conf.yaml中 [INFO] Session property has been set. Flink SQL> select * from `hive`.`demo_db`.`demo_tbl1`; +------+---------+-----+-------------------------------+-----------+ | uuid | name | age | ts | partition | +------+---------+-----+-------------------------------+-----------+ | id27 | Bob | 44 | 1970-01-01 00:00:07.000000000 | par4 | | id26 | Emma | 20 | 1970-01-01 00:00:06.000000000 | par3 | | id22 | Stephen | 33 | 1970-01-01 00:00:02.000000000 | par1 | | id25 | Sophia | 18 | 1970-01-01 00:00:05.000000000 | par3 | | id21 | Danny | 23 | 1970-01-01 00:00:01.000000000 | par1 | | id28 | Han | 56 | 1970-01-01 00:00:08.000000000 | par4 | | id23 | Julian | 53 | 1970-01-01 00:00:03.000000000 | par2 | | id24 | Fabian | 31 | 1970-01-01 00:00:04.000000000 | par2 | +------+---------+-----+-------------------------------+-----------+ 8 rows in set
- 流式读写数据
对分区表进行流式写入时,需要设置分区提交策略,通知下游某个分区已经写完毕可以被读取了。非分区表可以不设置,亦可以在建表时设置到表的 properties 中。
# 切换到Streaming模式 Flink SQL> SET 'execution.runtime-mode' = 'streaming'; [INFO] Session property has been set. # 对分区表,修改表Properties,或者在建表时设置该属性 Flink SQL> ALTER TABLE `hive`.`demo_db`.`demo_tbl1` SET ('sink.partition-commit.policy.kind'='metastore'); [INFO] Execute statement succeed. Flink SQL> INSERT INTO `hive`.`demo_db`.`demo_tbl1` VALUES > ('id11','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), > ('id12','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), > ('id13','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), > ('id14','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), > ('id15','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), > ('id16','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), > ('id17','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), > ('id18','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4'); [INFO] Submitting SQL update statement to the cluster... Flink SQL> select * from `hive`.`demo_db`.`demo_tbl1`; +----+--------------------------------+--------------------------------+-------------+-------------------------------+--------------------------------+ | op | uuid | name | age | ts | partition | +----+--------------------------------+--------------------------------+-------------+-------------------------------+--------------------------------+ | +I | id14 | Fabian | 31 | 1970-01-01 00:00:04.000000000 | par2 | | +I | id28 | Han | 56 | 1970-01-01 00:00:08.000000000 | par4 | | +I | id26 | Emma | 20 | 1970-01-01 00:00:06.000000000 | par3 | | +I | id13 | Julian | 53 | 1970-01-01 00:00:03.000000000 | par2 | | +I | id12 | Stephen | 33 | 1970-01-01 00:00:02.000000000 | par1 | | +I | id15 | Sophia | 18 | 1970-01-01 00:00:05.000000000 | par3 | | +I | id18 | Han | 56 | 1970-01-01 00:00:08.000000000 | par4 | | +I | id11 | Danny | 23 | 1970-01-01 00:00:01.000000000 | par1 | | +I | id27 | Bob | 44 | 1970-01-01 00:00:07.000000000 | par4 | | +I | id22 | Stephen | 33 | 1970-01-01 00:00:02.000000000 | par1 | | +I | id17 | Bob | 44 | 1970-01-01 00:00:07.000000000 | par4 | | +I | id25 | Sophia | 18 | 1970-01-01 00:00:05.000000000 | par3 | | +I | id24 | Fabian | 31 | 1970-01-01 00:00:04.000000000 | par2 | | +I | id16 | Emma | 20 | 1970-01-01 00:00:06.000000000 | par3 | | +I | id23 | Julian | 53 | 1970-01-01 00:00:03.000000000 | par2 | | +I | id21 | Danny | 23 | 1970-01-01 00:00:01.000000000 | par1 | +----+--------------------------------+--------------------------------+-------------+-------------------------------+--------------------------------+ Received a total of 16 rows
2.2 Flink SQL 集成 Hudi Connector
Flink 直接集成 Hudi 进行读写 TOS 操作,并将元数据同步到 HMS 中,供其它引擎查询。下面以 Yarn per-job 为例,演示相关集成操作。
Flink 集成 Hudi 需要引入 hudi-flink-bundle 包,目前在 EMR 集群启用 Hudi 的场景下,默认已经提供 hudi-flink-bundle 包。
- 启动 SQL 客户端命令行页面
./bin/sql-client.sh embedded -j connectors/flink-sql-connector-hive-3.1.2_2.12-1.16.1.jar
- 创建 Hudi 表,开启 HMS Hive Sync 同步
以创建 COW 表为例,并持久化 Flink 创建的 Hudi 表在 HMS 中。Flink 集成 Hudi 详细细节可参考Hudi官方文档,Flink 集成 Hudi 开启 Hive Sync 详细细节可参考 Hudi官方文档。
CREATE CATALOG hive WITH ( 'type' = 'hive', 'hive-conf-dir' = '/etc/emr/hive/conf' ); CREATE TABLE `hive`.`demo_db`.`flink_hudi_cow_tbl_hms_sync_demo_original` ( uuid VARCHAR(20), name VARCHAR(10), age INT, ts TIMESTAMP(3), `partition` VARCHAR(20) ) PARTITIONED BY (`partition`) WITH ( 'connector' = 'hudi', 'path' = 'tos://{bucket_name}/hms-warehouse/demo_db.db/flink_hudi_cow_tbl_hms_sync_demo', 'table.type' = 'COPY_ON_WRITE', 'hive_sync.enable' = 'true', 'hive_sync.mode' = 'hms', 'hive_sync.metastore.uris' = 'thrift://{ip}:{port}', 'hive_sync.table'='flink_hudi_cow_tbl_hms_sync_demo', 'hive_sync.db'='demo_db' );
- 使用 Flink SQL 进行读写操作
向 COW 表中写入数据,数据写入成功后,会将元数据同步到hive_sync.table指定的 table 中,COW 场景下只会创建一个目标表,MOR 场景下除了目标表以外,还会额外创建RO和RT表。
INSERT INTO `hive`.`demo_db`.`flink_hudi_cow_tbl_hms_sync_demo_original` VALUES ('id41','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'), ('id42','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'), ('id43','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'), ('id44','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'), ('id45','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'), ('id46','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'), ('id47','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'), ('id48','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4'); Flink SQL> show tables; +-------------------------------------------+ | table name | +-------------------------------------------+ | flink_hudi_cow_tbl_hms_sync_demo | | flink_hudi_cow_tbl_hms_sync_demo_original | +-------------------------------------------+ Flink SQL> select * from `hive`.`demo_db`.`flink_hudi_cow_tbl_hms_sync_demo_original`; +----+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+ | op | uuid | name | age | ts | partition | +----+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+ | +I | id38 | Han | 56 | 1970-01-01 00:00:08.000 | par4 | | +I | id37 | Bob | 44 | 1970-01-01 00:00:07.000 | par4 | | +I | id31 | Danny | 23 | 1970-01-01 00:00:01.000 | par1 | | +I | id32 | Stephen | 33 | 1970-01-01 00:00:02.000 | par1 | | +I | id35 | Sophia | 18 | 1970-01-01 00:00:05.000 | par3 | | +I | id36 | Emma | 20 | 1970-01-01 00:00:06.000 | par3 | | +I | id33 | Julian | 53 | 1970-01-01 00:00:03.000 | par2 | | +I | id34 | Fabian | 31 | 1970-01-01 00:00:04.000 | par2 | +----+--------------------------------+--------------------------------+-------------+-------------------------+--------------------------------+
- 使用 Spark 引擎进行读操作
spark-sql --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \ --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \ --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' spark-sql> use demo_db; spark-sql> show tables; flink_hudi_cow_tbl_hms_sync_demo flink_hudi_cow_tbl_hms_sync_demo_original Time taken: 0.072 seconds, Fetched 2 row(s) spark-sql> select * from flink_hudi_cow_tbl_hms_sync_demo; 20221125181029843 20221125181029843_2_0 id31 par1 1bde4613-4260-4349-bf4a-23a4a5d35c77_2-4-0_20221126092842836.parquet id31 Danny 231970-01-01 08:00:01 par1 20221125181029843 20221125181029843_2_1 id32 par1 1bde4613-4260-4349-bf4a-23a4a5d35c77_2-4-0_20221126092842836.parquet id32 Stephen 331970-01-01 08:00:02 par1 20221126092842836 20221126092842836_2_2 id42 par1 1bde4613-4260-4349-bf4a-23a4a5d35c77_2-4-0_20221126092842836.parquet id42 Stephen 331970-01-01 08:00:02 par1 20221126092842836 20221126092842836_2_3 id41 par1 1bde4613-4260-4349-bf4a-23a4a5d35c77_2-4-0_20221126092842836.parquet id41 Danny 231970-01-01 08:00:01 par1 20221125181029843 20221125181029843_1_0 id33 par2 4bd429d0-6af4-47c5-829f-887568c015f7_1-4-0_20221126092842836.parquet id33 Julian 531970-01-01 08:00:03 par2 20221125181029843 20221125181029843_1_1 id34 par2 4bd429d0-6af4-47c5-829f-887568c015f7_1-4-0_20221126092842836.parquet id34 Fabian 311970-01-01 08:00:04 par2 20221126092842836 20221126092842836_1_2 id44 par2 4bd429d0-6af4-47c5-829f-887568c015f7_1-4-0_20221126092842836.parquet id44 Fabian 311970-01-01 08:00:04 par2 20221126092842836 20221126092842836_1_3 id43 par2 4bd429d0-6af4-47c5-829f-887568c015f7_1-4-0_20221126092842836.parquet id43 Julian 531970-01-01 08:00:03 par2 20221125181029843 20221125181029843_0_0 id35 par3 8f4f152c-898c-44f1-aeea-4d8e158a24ff_0-4-0_20221126092842836.parquet id35 Sophia 181970-01-01 08:00:05 par3 20221125181029843 20221125181029843_0_1 id36 par3 8f4f152c-898c-44f1-aeea-4d8e158a24ff_0-4-0_20221126092842836.parquet id36 Emma 201970-01-01 08:00:06 par3 20221126092842836 20221126092842836_0_2 id46 par3 8f4f152c-898c-44f1-aeea-4d8e158a24ff_0-4-0_20221126092842836.parquet id46 Emma 201970-01-01 08:00:06 par3 20221126092842836 20221126092842836_0_3 id45 par3 8f4f152c-898c-44f1-aeea-4d8e158a24ff_0-4-0_20221126092842836.parquet id45 Sophia 181970-01-01 08:00:05 par3 20221125181029843 20221125181029843_3_0 id38 par4 24b3d004-5111-4ecd-8bb3-aa8ee80d5f7a_3-4-0_20221126092842836.parquet id38 Han 561970-01-01 08:00:08 par4 20221125181029843 20221125181029843_3_1 id37 par4 24b3d004-5111-4ecd-8bb3-aa8ee80d5f7a_3-4-0_20221126092842836.parquet id37 Bob 441970-01-01 08:00:07 par4 20221126092842836 20221126092842836_3_2 id48 par4 24b3d004-5111-4ecd-8bb3-aa8ee80d5f7a_3-4-0_20221126092842836.parquet id48 Han 561970-01-01 08:00:08 par4 20221126092842836 20221126092842836_3_3 id47 par4 24b3d004-5111-4ecd-8bb3-aa8ee80d5f7a_3-4-0_20221126092842836.parquet id47 Bob 441970-01-01 08:00:07 par4 Time taken: 7.876 seconds, Fetched 16 row(s)
2.3 Flink SQL 集成 Doris Connector
火上EMR Flink支持通过Flink Doris Connector将数据写入Doris中,并在connector目录下内置了Doris Connector。下面以Yarn per-job为例,演示通过Flink读写Doris。
- 启动SQL客户端命令行页面
# 注意不同EMR版本,connector包的版本有差异,可根据实际connector的版本进行调整 /usr/lib/emr/current/flink/bin/sql-client.sh embedded \ -j connectors/flink-doris-connector-1.16-1.3.0-ve-1.jar
- 远程连接Doris,并创建目标表。
可参考火山EMR-Doris-基础使用,创建对应用户账号。
-- mysql -hxxx.xxx.xx -P9030 -uxxxx -p CREATE DATABASE demo_db; USE demo_db; CREATE TABLE all_employees_info ( emp_no int NOT NULL, birth_date date, first_name varchar(20), last_name varchar(20), gender char(2), hire_date date ) UNIQUE KEY(`emp_no`, `birth_date`) DISTRIBUTED BY HASH(`birth_date`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
- Flink建表Doris Sink表,并插入数据
-- 创建Doris Sink表 CREATE TABLE doris_sink ( emp_no int , birth_date STRING, first_name STRING, last_name STRING, gender STRING, hire_date STRING ) WITH ( 'connector' = 'doris', 'fenodes' = '192.168.1.41:8030', 'table.identifier' = 'demo_db.all_employees_info', 'username' = 'test_user', 'password' = 'test_passwd', 'sink.properties.two_phase_commit'='true', 'sink.label-prefix'='doris_demo_emp_001' ); Flink SQL> INSERT INTO `doris_sink` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26'), (10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21'), (10003,'1959-12-03','Parto','Bamford','M','1986-08-28'), (10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01'), (10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12'), (10006,'1953-04-20','Anneke','Preusig','F','1989-06-02'), (10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10'), (10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15'), (10009,'1952-04-19','Sumant','Peac','F','1985-02-18'), (10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
- Flink创建Doris Source表,并读取数据
-- 创建Doris Source表 Flink SQL> CREATE TABLE doris_source ( emp_no int , birth_date DATE, first_name STRING, last_name STRING, gender STRING, hire_date DATE ) WITH ( 'connector' = 'doris', 'fenodes' = '192.168.1.41:8030', 'table.identifier' = 'demo_db.all_employees_info', 'username' = 'test_user', 'password' = 'test_passwd', 'doris.read.field' = 'emp_no,birth_date,first_name,last_name,gender,hire_date' ); -- 读取数据 Flink SQL> select * from doris_source; +----+-------------+------------+--------------------------------+--------------------------------+--------------------------------+------------+ | op | emp_no | birth_date | first_name | last_name | gender | hire_date | +----+-------------+------------+--------------------------------+--------------------------------+--------------------------------+------------+ | +I | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | +I | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | | +I | 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | | +I | 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | | +I | 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | | +I | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | | +I | 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 | | +I | 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 | | +I | 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 | | +I | 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 | +----+-------------+------------+--------------------------------+--------------------------------+--------------------------------+------------+ Received a total of 10 rows
2.4 Flink SQL集成StarRocks Connector
与Doris Connector类似,火上EMR Flink支持通过Flink StarRocks Connector将数据写入StarRocks中,并在connector目录下内置了StarRocks Connector。下面以Yarn per-job为例,演示通过Flink读写StarRocks。
- 启动SQL客户端命令行页面
# 注意不同EMR版本,connector包的版本有差异,可根据实际connector的版本进行调整 /usr/lib/emr/current/flink/bin/sql-client.sh embedded \ -j connectors/flink-starrocks-connector-1.16-1.2.5-ve-1.jar set execution.target=yarn-per-job;
- 远程连接StarRocks,并创建目标表
可参考火山EMR-StarRocks-基础使用,创建对应用户账号。
-- mysql -hxxx.xxx.xx -P9030 -uxxxx -p mysql> CREATE DATABASE demo_db; mysql> USE demo_db; mysql> CREATE TABLE all_employees_info ( emp_no int NOT NULL, birth_date date, first_name varchar(20), last_name varchar(20), gender char(2), hire_date date ) UNIQUE KEY(`emp_no`, `birth_date`) DISTRIBUTED BY HASH(`birth_date`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1" );
- Flink 创建 StarRocks Sink 表,并插入数据
-- 创建Sink表 Flink SQL> CREATE TABLE sr_sink ( emp_no int , birth_date STRING, first_name STRING, last_name STRING, gender STRING, hire_date STRING ) WITH ( 'connector' = 'starrocks', 'load-url' = '192.168.1.26:8030', 'jdbc-url' = 'jdbc:mysql://192.168.1.26:9030', 'database-name' = 'demo_db', 'table-name' = 'all_employees_info', 'username' = 'test_user', 'password' = 'test_passwd' ); Flink SQL> INSERT INTO `sr_sink` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26'), (10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21'), (10003,'1959-12-03','Parto','Bamford','M','1986-08-28'), (10004,'1954-05-01','Chirstian','Koblick','M','1986-12-01'), (10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12'), (10006,'1953-04-20','Anneke','Preusig','F','1989-06-02'), (10007,'1957-05-23','Tzvetan','Zielinski','F','1989-02-10'), (10008,'1958-02-19','Saniya','Kalloufi','M','1994-09-15'), (10009,'1952-04-19','Sumant','Peac','F','1985-02-18'), (10010,'1963-06-01','Duangkaew','Piveteau','F','1989-08-24');
- Flink创建StarRocks Source表,并查询数据
-- 创建Source表 Flink SQL> CREATE TABLE sr_source ( emp_no int , birth_date STRING, first_name STRING, last_name STRING, gender STRING, hire_date STRING ) WITH ( 'connector' = 'starrocks', 'scan-url' = '192.168.1.26:8030', 'jdbc-url' = 'jdbc:mysql://192.168.1.26:9030', 'database-name' = 'demo_db', 'table-name' = 'all_employees_info', 'username' = 'test_user', 'password' = 'test_passwd' ); Flink SQL> SELECT * FROM sr_source; +----+-------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+ | op | emp_no | birth_date | first_name | last_name | gender | hire_date | +----+-------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+ | +I | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | +I | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | | +I | 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 | | +I | 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 | | +I | 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | | +I | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | | +I | 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 | | +I | 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 | | +I | 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 | | +I | 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 | +----+-------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+--------------------------------+ Received a total of 10 rows
2.5 Flink SQL 集成 Bytehouse(云数仓版)
火上 Bytehouse(云数仓版)支持通过 Flink ByteHouse-Cdw Connector 将数据写入 ByteHouse(云数仓版)中,并在 connectors 目录下内置了 Bytehouse-cdw Connector。下面以 Yarn per-job 为例,演示通过 datagen 写入ByteHouse(云数仓版本)。
参考 ByteHouse云数仓版 / 快速入门 创建bytehouse集群和建表, 其中建库和建表语句如下
create databese flink_bytehouse_test;CREATE TABLE `flink_bytehouse_test`.`cnch_table_test` ( test_key STRING, test_value UInt64, ts UInt64 ) ENGINE = CnchMergeTree ORDER BY (test_key);启动 SQL 客户端命令行页面
# 注意不同EMR版本,connector包的版本有差异,可根据实际connector的版本进行调整 /usr/lib/emr/current/flink/bin/sql-client.sh embedded \ -j connectors/flink-sql-connector-bytehouse-cdw_2.12-1.25.4-1.16.jar set execution.target=yarn-per-job;Flink创建ByteHouse(云数仓版本)Sink表,通过datagen 插入数据到ByteHouse(云数仓表)
CREATE TABLE random_source ( test_key STRING, test_value BIGINT, ts BIGINT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1' ); CREATE TABLE cnch_table (test_key STRING, test_value BIGINT, ts BIGINT) WITH ( 'connector' = 'bytehouse-cdw', 'database' = 'flink_bytehouse_test', 'table-name' = 'cnch_table_test', 'bytehouse.gateway.region' = 'VOLCANO', 'bytehouse.gateway.access-key-id' = '<此处填写用户实际的 AK>', 'bytehouse.gateway.secret-key' = '<此处填写用户实际的 SK>' ); INSERT INTO cnch_table SELECT * FROM random_source;
- 进入bytehouse SQL 工作表 页签,单击选择对应角色和正在运行的计算组, 执行查询插入数据的条数
select count(*) from `flink_bytehouse_test`.`cnch_table_test`;
2.6 Flink SQL 集成 Bytehouse(企业版)
类似ByteHouse(云数仓版), 火上ByteHouse(企业版)支持通过Flink ByteHouse-CE connector将数据写入到ByteHouse(企业版)中。并在 connectors 目录下内置了 Bytehouse-CE Connector(EMR 1.8.0 开始内置)。下面以 Yarn per-job 为例,演示通过 datagen 写入ByteHouse(企业版)。
- 参考ByteHouse(企业版)库表创建,创建bytehouse集群和建表
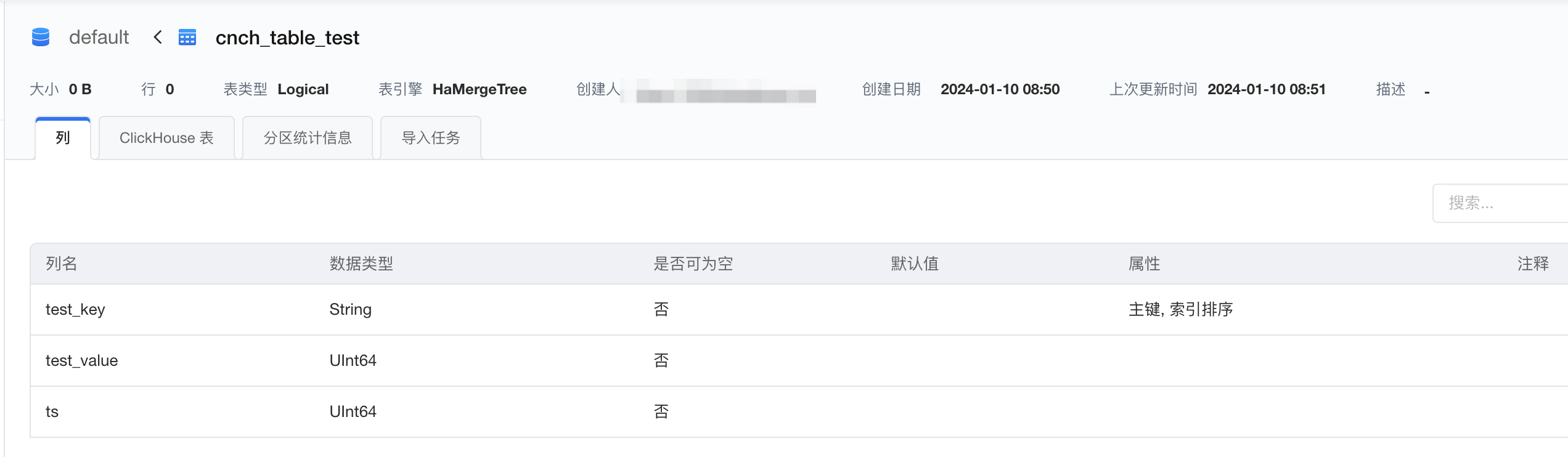
- 启动 SQL 客户端命令行页面
/usr/lib/emr/current/flink/bin/sql-client.sh embedded \ -j connectors/flink-sql-connector-bytehouse-ce_2.12-1.25.4-1.16.jar set execution.target=yarn-per-job;
- 通过gateway的方式的插入数据到Bytehouse(企业版)
CREATE TABLE random_source ( test_key STRING, test_value BIGINT, ts BIGINT ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '1' ); CREATE TABLE cnch_table (test_key STRING, test_value BIGINT, ts BIGINT) WITH ( 'connector' = 'bytehouse-ce', 'clickhouse.shard-discovery.kind' = 'CE_GATEWAY', 'bytehouse.ce.gateway.host' = '7322262036938936630.bytehouse-ce.ivolces.com', 'bytehouse.ce.gateway.port' = '8123', 'sink.enable-upsert' = 'false', 'clickhouse.cluster' = 'bytehouse_cluster_enct', -- bytehouse集群名称 'database' = 'default', -- 目标数据库 'table-name' = 'cnch_table_test', -- 目标表 注意是local表:{table_name}_local 'username' = 'xxxx@bytedance.com', -- bytehouse 用户 'password' = 'xxx' -- bytehouse 密码 ); INSERT INTO cnch_table SELECT * FROM random_source;
- 进入ByteHouse(企业版) 数据查询页面,选择对应的集群,执行查询插入数据的条数
select count(*) FROM `default`.`cnch_table_test`;