E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce数据导入与导出数据导入Stream Load
E-MapReduce数据导入与导出数据导入Stream Load

本文介绍 Stream Load 事务接口、以及如何使用该事务接口把数据导入到 StarRocks 中。本文图片和内容来源于开源StarRocks的StreamLoad章节。
1 功能介绍
Stream Load 是一种基于 HTTP 协议的同步导入方式,支持将本地文件或数据流导入到 StarRocks 中。您提交导入作业以后,StarRocks 会同步地执行导入作业,并返回导入作业的结果信息。您可以通过返回的结果信息来判断导入作业是否成功。
支持CSV、JSON文件格式,数据量建议在10 GB以下。
说明
Stream Load 当前不支持导入某一列为 JSON 的 CSV 文件的数据。
2 基本原理
用户通过HTTP协议提交Stream Load导入作业请求,FE收到该请求后,会将其转发给某个BE节点。该BE节点成为Coordinator节点,负责接收数据并分发数据到其他数据节点,导入完成后将结果返回给用户。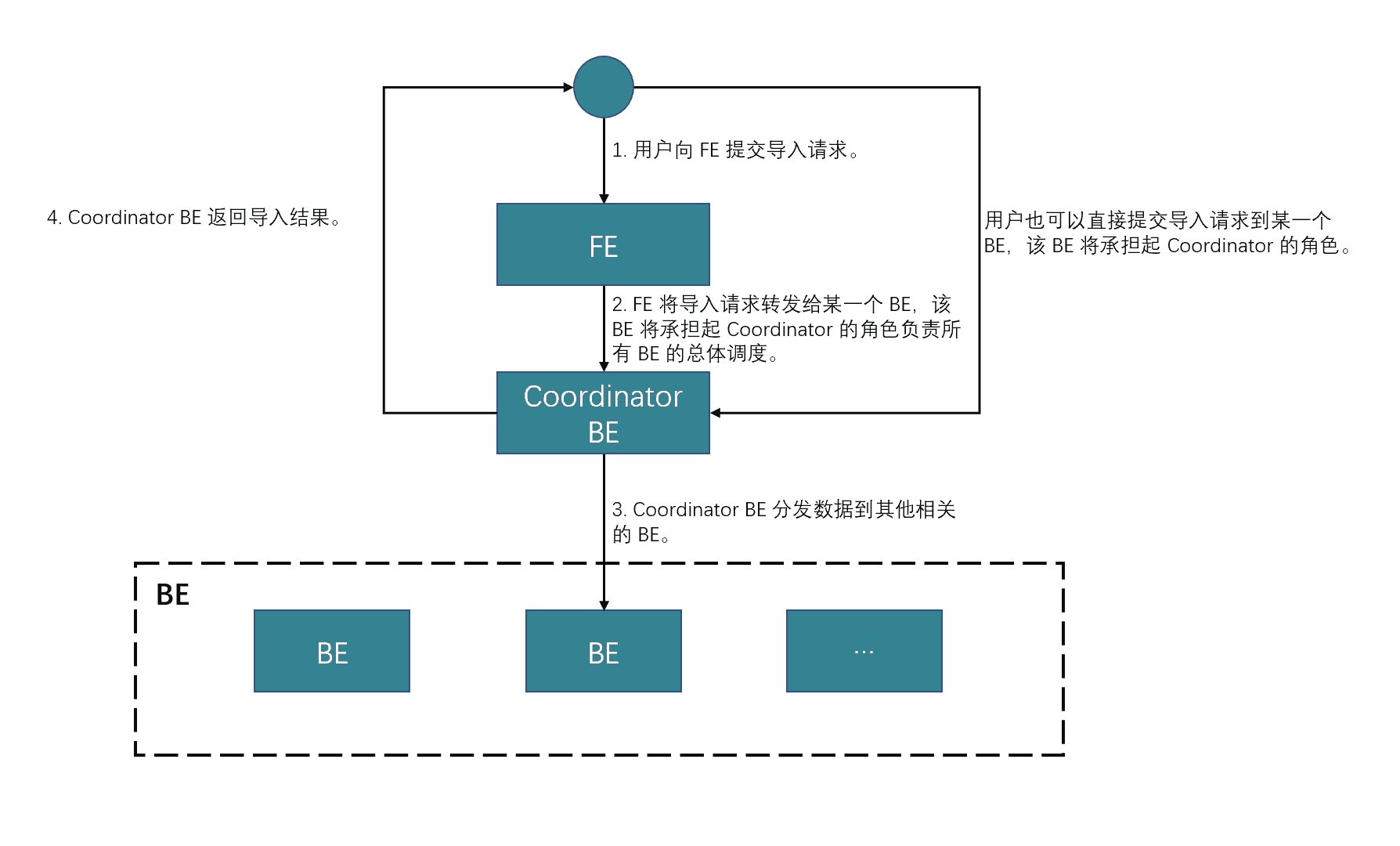
2.1 使用介绍
Stream Load通过HTTP协议提交和传输数据。本示例通过curl命令介绍提交导入任务方式。您也可以通过其他HTTP Client进行操作。
2.2 语法
curl --location-trusted -u username:password [data_desc] -T file_path -XPUT \ http://fe_host:fe_http_port/api/database_name/table_name/_stream_load
参数说明如下:
| 参数 | 描述 |
|---|---|
| username:password | 用于指定 StarRocks 集群账号的用户名和密码。必选参数。 |
| file_path | 源数据文件的保存路径。 |
| fe_host:fe_http_port | FE的IP和端口(端口默认是8030)。 |
| database_name | 目标表所在的数据库的名称。 |
| table_name | 目标表的名称。 |
data_desc | 可选。用于描述源数据文件。语法是:
参数描述如下可参考StarRocks社区data_desc章节。 |
导入任务完成后,Stream Load会以JSON格式返回导入任务的相关内容,返回结果示例如下:
{ "TxnId": 13, "Label": "123", "Status": "Success", "Message": "OK", "NumberTotalRows": 4, "NumberLoadedRows": 4, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 42, "LoadTimeMs": 45, "BeginTxnTimeMs": 8, "StreamLoadPlanTimeMs": 9, "ReadDataTimeMs": 0, "WriteDataTimeMs": 6, "CommitAndPublishTimeMs": 21 }
返回值的参数介绍参考StarRocks社区返回值章节。
3 导入示例
3.1 导入 CSV 格式的数据
- 准备数据
在本地文件系统中创建一个 CSV 格式的数据文件example1.csv,内容如下:
1,Lily,23 2,Rose,23 3,Alice,24 4,Julia,25
在数据库
test_db中创建目标表table1CREATE DATABASE IF NOT EXISTS test_db; USE test_db; CREATE TABLE `table1` ( `id` int(11) NOT NULL COMMENT "用户 ID", `name` varchar(65533) NULL COMMENT "用户姓名", `score` int(11) NOT NULL COMMENT "用户得分" ) ENGINE=OLAP PRIMARY KEY(`id`) DISTRIBUTED BY HASH(`id`);创建导入作业
curl --location-trusted -u <username>:<password> -H "label:123" \ -H "Expect:100-continue" \ -H "column_separator:," \ -H "columns: id, name, score" \ -T example1.csv -XPUT \ http://<fe_host>:8030/api/test_db/table1/_stream_load
说明
1. column\_separator参数:定义文件分隔符。`example1.csv` 文件中包含三列,跟 `table1` 表的 `id`、`name`、`score` 三列一一对应,并用逗号 (,) 作为列分隔符。
导入完成后,查询
table1表的数据SELECT * FROM table1;
3.2 导入 JSON 格式的数据
准备数据
创建一个 JSON 格式的数据文件
example2.json,内容如下:{"name": "北京", "code": 2}在数据库
test_db中创建目标表table2CREATE TABLE `table2` ( `id` int(11) NOT NULL COMMENT "城市 ID", `city` varchar(65533) NULL COMMENT "城市名称" ) ENGINE=OLAP PRIMARY KEY(`id`) DISTRIBUTED BY HASH(`id`);创建导入作业,把
example2.json文件中的数据导入到table2表中curl -v --location-trusted -u <username>:<password> -H "strict_mode: true" \ -H "Expect:100-continue" \ -H "format: json" -H "jsonpaths: [\"$.name\", \"$.code\"]" \ -H "columns: city,tmp_id, id = tmp_id * 100" \ -T example2.json -XPUT \ http://<fe_host>:8030/api/test_db/table2/_stream_loadexample2.json文件中包含name和code两个键,跟table2表中的列之间的对应关系如下图所示。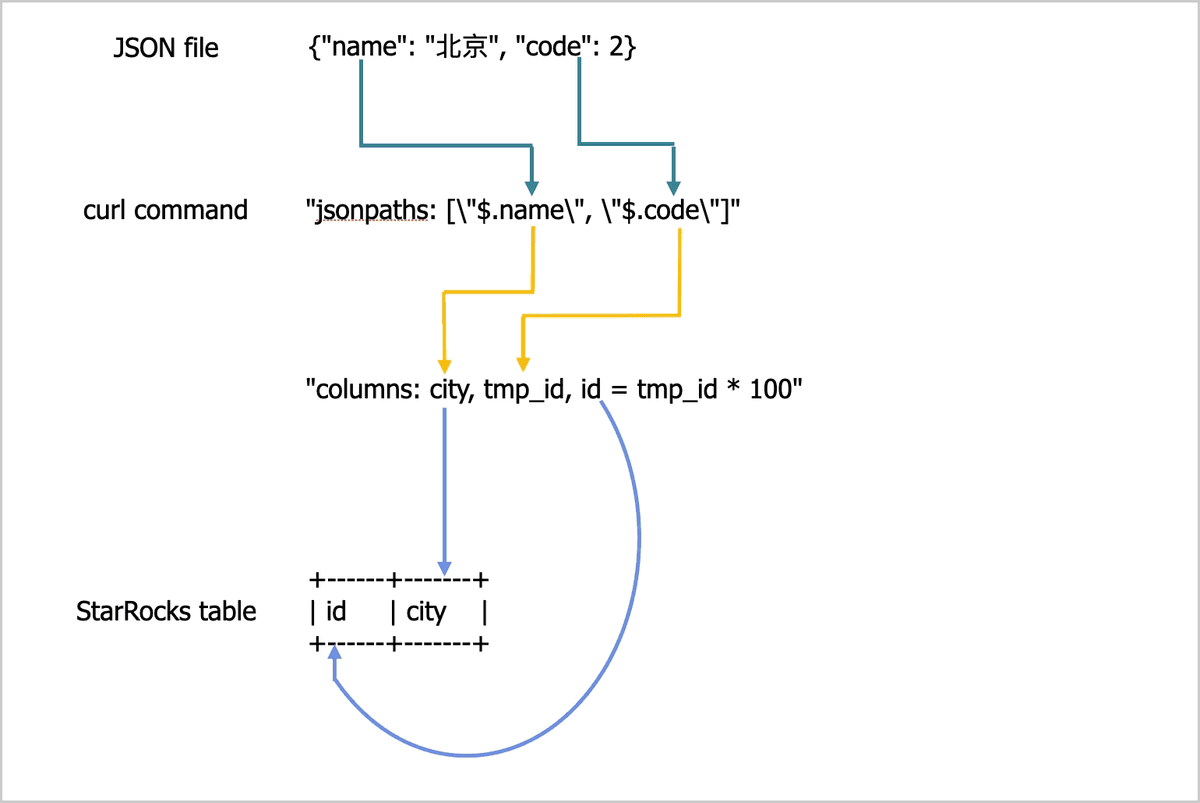
上图所示的对应关系描述如下:提取
example2.json文件中包含的name和code两个字段,按顺序依次映射到jsonpaths参数中声明的name和code两个字段。提取
jsonpaths参数中声明的name和code两个字段,按顺序映射到columns参数中声明的city和tmp_id两列。提取
columns参数声明中的city和id两列,按名称映射到table2表中的city和id两列。
说明
1. jsonpaths参数:按照 JSON 文件中 Key 的顺序一一指定待导入的 Key。 2. columns参数: 源数据文件中的列与目标表中的列不能按顺序一一对应,包括数量或顺序不一致,则必须通过 `COLUMNS` 参数来指定列映射和转换关系。 3. 有关导入 JSON 数据字段之间的对应关系,请参见 STREAM LOAD 文档中“[列映射](https://docs.starrocks.io/zh/docs/sql-reference/sql-statements/data-manipulation/STREAM_LOAD#%E5%88%97%E6%98%A0%E5%B0%84)”章节。
导入完成后,查询
table2表的数据SELECT * FROM table2;