E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南StarRocks最佳实践Starrocks跨大版本升级
E-MapReduce组件操作指南StarRocks最佳实践Starrocks跨大版本升级

1 背景需求
目前我们有一部分用户使用2.5.x版本, 该版本虽然是LTS版本, 但已经是近一年半以前发布的版本了, 新版本中很多的功能都不支持.
因此有不少客户希望能将Starrocks版本从2.5.x升级到3.2.x.
但SR社区由于元数据兼容性的问题, 无法直接升级, 需要中间3.0和3.1的过渡版本, 而这两个版本都非LTS版本, 升级版本本身可能会带来额外的问题, 因此在这里推荐迁移升级的模式.
2 升级方案
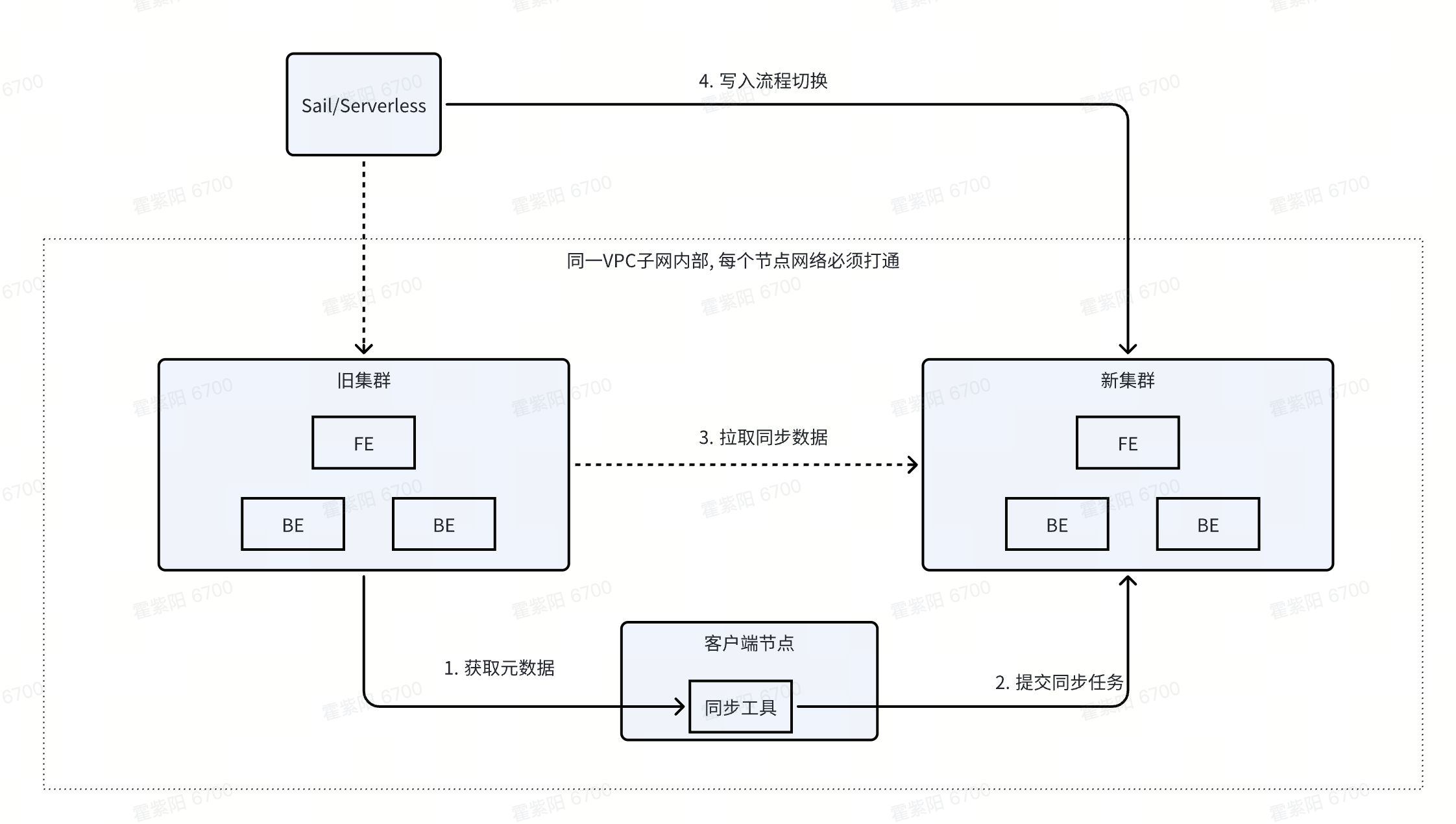
在旧集群的同一VPC子网中, 创建一个新版本的SR集群
找一个在子网内部, 能够联通两个集群的节点, 当做客户端节点, 部署同步工具
配置同步工具配置选项, 并启动同步任务
工具能够自动在旧集群获取元数据
并在新集群提交同步任务
同步任务会自动取旧集群拉取同步数据
等数据全部迁移完成后, 将实时写入部分切换流入地址, 完成新老集群的置换
3 迁移详细步骤
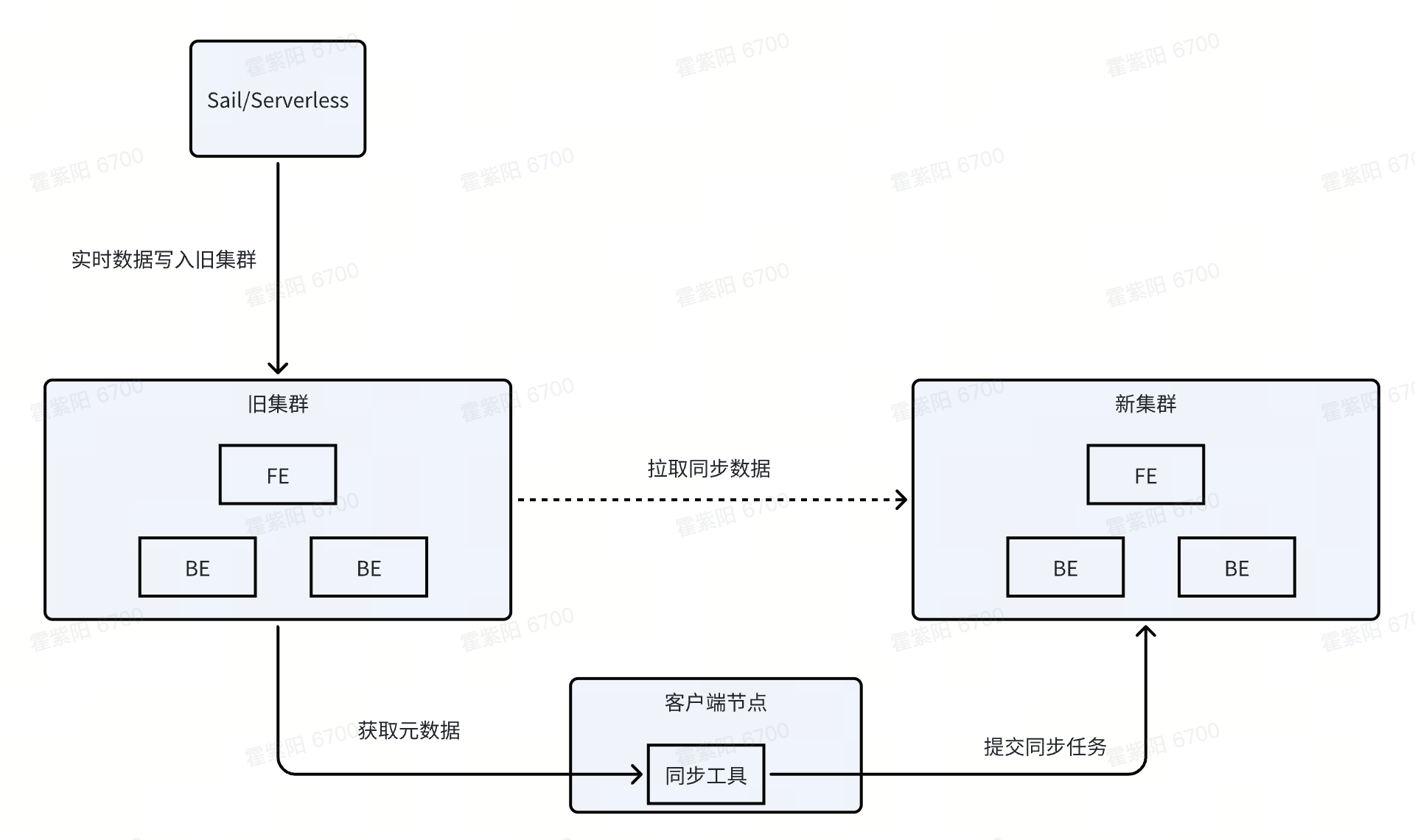
3.1 准备工作
以下准备工作需要在数据迁移的目标集群中进行。
3.1.1 关闭 Compaction(目标集群为存算分离集群)
如果数据迁移的目标集群为存算分离集群,在数据迁移之前,您需要手动关闭 Compaction,并在数据迁移完成后重新开启。
- 您可以通过以下语句查看当前集群是否开启 Compaction:
ADMIN SHOW FRONTEND CONFIG LIKE 'lake_compaction_max_tasks';
如果返回值为 0 则表示 Compaction 关闭。
- 动态关闭 Compaction:
ADMIN SET FRONTEND CONFIG("lake_compaction_max_tasks"="0");
- 为防止数据迁移过程中集群重启后 Compaction 自动开启,您还需要在 FE 配置文件 fe.conf 中添加以下配置项:
lake_compaction_max_tasks = 0
- 数据迁移完成后,您需要删除配置文件中的
lake_compaction_max_tasks = 0,并通过以下语句动态开启 Compaction:
ADMIN SET FRONTEND CONFIG("lake_compaction_max_tasks"="-1");
3.1.2 配置数据迁移(可选)
您可以通过以下 FE 和 BE 参数配置数据迁移操作。通常情况下,默认配置即可满足需求。如果您想保留默认配置,可以选择跳过该步骤。
注意
请注意,增大以下配置项可以加速迁移,但同样会增加源集群负载压力。
FE 参数
以下 FE 参数为动态参数。修改方式请参考 配置 FE 动态参数。
| 参数名 | 默认值 | 单位 | 描述 |
|---|---|---|---|
| replication_max_parallel_table_count | 100 | - | 允许并发执行的数据同步任务数。StarRocks 为一张表创建一个同步任务。 |
| replication_max_parallel_data_size_mb | 10240 | MB | 允许并发同步的数据量。 |
| replication_transaction_timeout_sec | 3600 | 秒 | 同步任务的超时时间。 |
ADMIN SET FRONTEND CONFIG("replication_max_parallel_data_size_mb"="102400");
BE 参数
以下 BE 参数为动态参数。修改方式请参考 配置 BE 动态参数。
| 参数名 | 默认值 | 单位 | 描述 |
|---|---|---|---|
| replication_threads | 0 | - | 执行同步任务的线程数。0 表示设置线程数为 BE 所在机器的 CPU 核数。 |
3.2 第一步:安装工具
推荐您在数据迁移目标集群所在的服务器上安装迁移工具。
打开终端,下载工具安装包。
wget https://releases.starrocks.io/starrocks/starrocks-cluster-sync.tar.gz
解压安装包。
tar -xvzf starrocks-cluster-sync.tar.gz
3.3 第二步:配置工具
进入解压后的文件夹,并修改配置文件 conf/sync.properties。
cd starrocks-cluster-sync vi conf/sync.properties
文件内容如下:
If true, all tables will be synchronized only once, and the program will exit automatically after completion. one_time_run_mode=false source_fe_host= source_fe_query_port=9030 source_cluster_user=root source_cluster_password= source_cluster_token= target_fe_host= target_fe_query_port=9030 target_cluster_user=root target_cluster_password= meta_job_interval_seconds=180 ddl_job_interval_seconds=15 ddl_job_batch_size=10 ddl_job_allow_drop_target_only=false ddl_job_allow_drop_schema_change_table=true ddl_job_allow_drop_inconsistent_partition=true replication_job_interval_seconds=15 replication_job_batch_size=10 Comma-separated list of database names or table names like <db_name> or <db_name.table_name> example: db1,db2.tbl2,db3 Effective order: 1. include 2. exclude include_data_list= exclude_data_list=
参数说明如下:
| 参数名 | 描述 |
|---|---|
| one_time_run_mode | 是否开启一次性同步模式。开启一次性同步模式后,迁移工具只进行全量同步,不进行增量同步。 |
| source_fe_host | 源集群 FE 的 IP 地址或 FQDN。 |
| source_fe_query_port | 源集群 FE 的查询端口(query_port)。 |
| source_cluster_user | 用于登录源集群的用户名。此用户需要有 SYSTEM 级 OPERATE 权限。 |
| source_cluster_password | 用于登录源集群的用户密码。 |
| source_cluster_token | 源集群的 Token。关于如何获取集群 Token,见以下获取集群 Token部分。 |
| target_fe_host | 目标集群 FE 的 IP 地址或 FQDN。 |
| target_fe_query_port | 目标集群 FE 的查询端口(query_port)。 |
| target_cluster_user | 用于登录目标集群的用户名。此用户需要有 SYSTEM 级 OPERATE 权限。 |
| target_cluster_password | 用于登录目标集群的用户密码。 |
| meta_job_interval_seconds | 迁移工具获取源集群和目标集群元数据的周期,单位为秒。此项您可以使用默认值。 |
| ddl_job_interval_seconds | 迁移工具在目标集群执行 DDL 的周期,单位为秒。此项您可以使用默认值。 |
| ddl_job_batch_size | 迁移工具在目标集群执行 DDL 的批大小。此项您可以使用默认值。 |
| ddl_job_allow_drop_target_only | 迁移工具是否自动删除仅在目标集群存在而源集群不存在的数据库,表或分区。默认为 false,即不删除。此项您可以使用默认值。 |
| ddl_job_allow_drop_schema_change_table | 迁移工具是否自动删除源集群和目标集群 Schema 不一致的表,默认为 true,即删除。此项您可以使用默认值。迁移工具会在同步过程中自动同步删除的表。 |
| ddl_job_allow_drop_inconsistent_partition | 迁移工具是否自动删除源集群和目标集群数据分布方式不一致的分区,默认为 true,即删除。此项您可以使用默认值。迁移工具会在同步过程中自动同步删除的分区。 |
| replication_job_interval_seconds | 迁移工具触发数据同步任务的周期,单位为秒。此项您可以使用默认值。 |
| replication_job_batch_size | 迁移工具触发数据同步任务的批大小。此项您可以使用默认值。 |
| include_data_list | 需要迁移的数据库和表,多个对象使用逗号(,)分隔。示例:db1,db2.tbl2,db3。此项优先于 exclude_data_list 生效。如果您需要迁移集群中所有数据库和表,则无须配置该项。 |
| exclude_data_list | 不需要迁移的数据库和表,多个对象使用逗号(,)分隔。示例:db1,db2.tbl2,db3。include_data_list 优先于此项生效。如果您需要迁移集群中所有数据库和表,则无须配置该项。 |
3.3.1 获取集群 Token
您可以通过 FE 的 HTTP 端口获取,或通过 FE 节点的元数据获取集群 Token。
- 通过 FE 的 HTTP 端口获取集群 Token
运行以下命令:
curl -v http://<fe_host>:8030/check
fe_host:集群 FE 的 IP 地址或 FQDN。fe_http_port:集群 FE 的 HTTP 端口。
返回如下:
About to connect() to xxx.xx.xxx.xx port 8030 (#0) Trying xxx.xx.xxx.xx... Connected to xxx.xx.xxx.xx (xxx.xx.xxx.xx) port 8030 (#0) GET /check HTTP/1.1 User-Agent: curl/7.29.0 Host: xxx.xx.xxx.xx:8030 Accept: / < HTTP/1.1 200 OK < content-length: 0 < cluster_id: yyyyyyyyyyy < content-type: text/html < token: wwwwwwww-xxxx-yyyy-zzzz-uuuuuuuuuu < connection: keep-alive < Connection #0 to host xxx.xx.xxx.xx left intact
其中 token 字段即为当前集群的 Token。
- 通过 FE 节点的元数据获取集群 Token
登录 FE 节点所在的服务器,运行以下命令:
cat fe/meta/image/VERSION | grep token
返回如下:
token=wwwwwwww-xxxx-yyyy-zzzz-uuuuuuuuuu
3.4 第三步:启动迁移工具
配置完成后,启动迁移工具开始数据迁移。
./bin/start.sh
注意
请务必确保源集群与目标集群的 BE 节点已通过网络连通。
运行期间,迁移工具会周期性地检查目标集群的数据是否落后于源集群,如果落后则会发起数据迁移任务。
如果源集群持续有新数据导入,数据同步会一直进行,直至目标集群与源集群数据一致。
您可以查询目标集群中处于迁移过程中的表,但请不要导入新数据(当前迁移工具未禁止导入),否则会导致目标集群数据与源集群不一致。
请注意数据迁移不会自动结束。您需要手动检查确认迁移完成后停止迁移工具。
3.5 第四步:迁移进度校验
3.5.1 查看迁移工具日志
您可以通过迁移工具日志 log/sync.INFO.log 查看迁移进度。
示例:
主要指标如下:
Sync progress:数据迁移进度。由于迁移工具会周期性地检查目标集群的数据是否落后于源集群,所以当进度为 100% 时,仅代表当前检查周期内数据同步完成。如果源集群持续有新数据导入,该进度可能在下次检查周期内变小。total:本次迁移操作的各类 Job 总数。ddlPending:所有待执行的 DDL Job 数量。jobPending:所有待执行的数据同步 Job 数量。sent:已从源集群发送但未开始运行的数据同步 Job 数量。理论上该值不会太大,若出现该值持续增加的情况,请联系研发人员。running:正在执行的数据同步 Job 数量。finished:执行成功的数据同步 Job 数量。failed:执行失败的数据同步 Job 数量。失败的数据同步 Job 将会重新发送。因此,通常情况下您可以忽略该指标。若出现该值较大的情况,请联系研发人员。unknown:未知状态 Job 的数量。理论上该值恒常为0。若出现该值不为0的情况,请联系研发人员。
3.5.2 查看迁移事务状态
迁移工具会为每张表开启一个事务。您可以通过查看该事务的状态了解该表迁移的状态。
SHOW PROC "/transactions/<db_name>/running";
其中 <db_name> 为该表所在数据库的名称。
3.5.3 查看分区数据版本
您可以对比源集群和目标集群中对应分区的数据版本了解该分区的迁移状态。
SHOW PARTITIONS FROM <table_name>;
其中 <table_name> 为该分区所属表的名称。
3.5.4 查看数据量
您可以对比源集群和目标集群的数据量了解迁移的状态。
SHOW DATA;
3.5.5 查看表行数
您可以对比源集群和目标集群中表的行数了解各表迁移的状态。
SELECT TABLE_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE = 'BASE TABLE' ORDER BY TABLE_NAME;
3.5.6 实时任务
如果是实时任务, 那么源集群的数据在不断的增加, 因此两边的行数和数据量不一定会完全相等.
我们可以通过分区的行数对比结果, 如果历史分区的数据一致, 说明数据已经同步完成, 而当天分区的数据不做对比.
实时写入切流之后, 可以在实时链路中, 回溯一天的数据, 保证当天实时分区内的数据不遗留.