E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南Paimon高阶使用
E-MapReduce组件操作指南Paimon高阶使用

火山引擎 E-MapReduce(EMR)支持通过 Spark SQL 写入、支持 Hive 和 Presto 引擎查询 Paimon 表。在查询方面,EMR 的 Paimon 版本对 Presto 有相关的适配,直接内置集成在了 presto 中,无需额外配置。
Paimon - Spark 集成
本段主要介绍如何使用 Spark ThriftServer 配置连接 Paimon。
- 登录 EMR 控制台。
- 在左侧导航栏中,进入集群管理 > 集群列表 > 集群详情 > 服务列表 > Spark 服务参数界面。
- 安装完 Paimon 后,可以到 sparkthriftserver 配置页面,在 spark-defaults 中
- 修改 spark.sql.extensions 配置加上 org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions (如果已有存在的值,用逗号隔开)
- 增加 spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog
- 增加 spark.sql.catalog.paimon.metastore=hive
使用 beeline 连接 sparkthriftserver 用于测试, 参考 LDAP 文档和 Spark最佳实践 ,来配置用户名密码进行 sparkthriftserver 连接。
beeline -u jdbc:hive2://emr-30f8q2lxxxxxxxxxx-master-1:10000/default -n xxxx -p xxxxx
然后您可使用标准 SparkSQL 操作 Paimon 表。
Paimon - Presto 集成
修改 paimon.properties 的中的 warehouse 参数,指向实际的 hive warehouse 路径,比如:hdfs://emr-cluster/user/hive/warehouse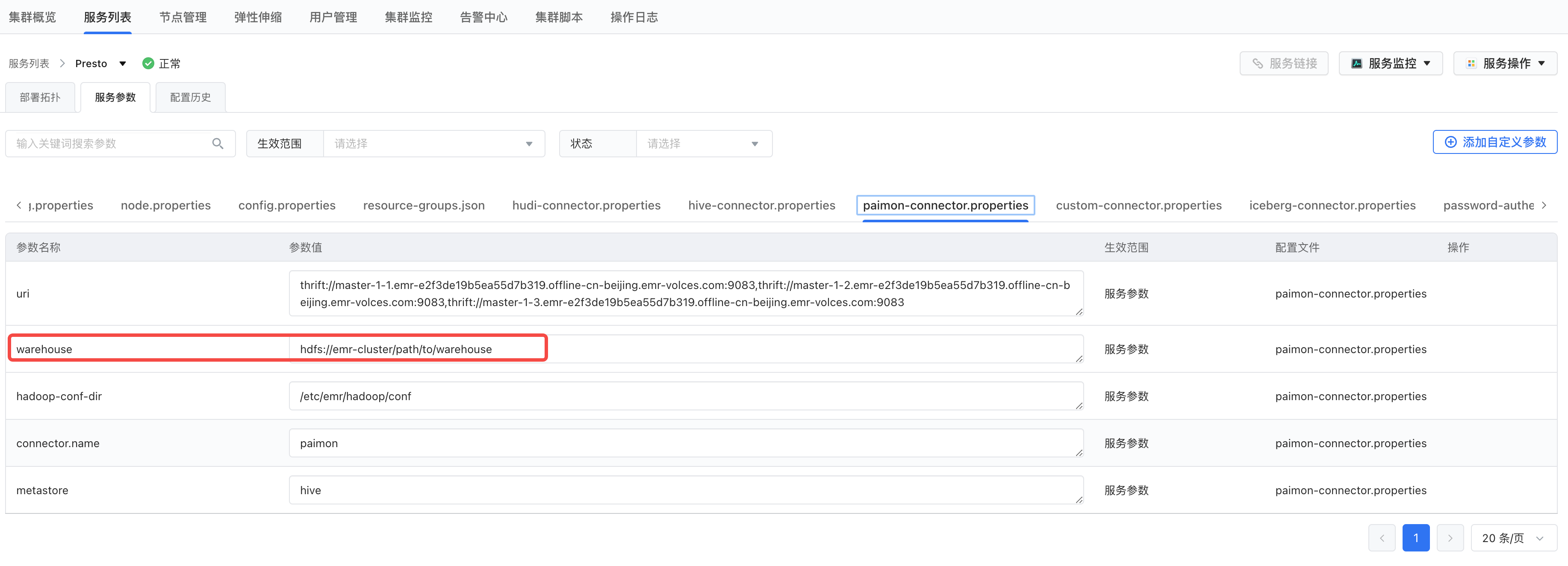
重启所有 presto 组件
查看 catalog
SHOW CATALOGS;
创建 schema
CREATE SCHEMA paimon.test_db;
查询数据
SELECT * FROM paimon.test_db.test_table;
Paimon - StarRocks 集成
环境集成
将 Hadoop 集群的 core-site.xml 和 hdfs-site.xml 配置文件拷贝到 StarRocks 集群,并重启 StarRocks 服务。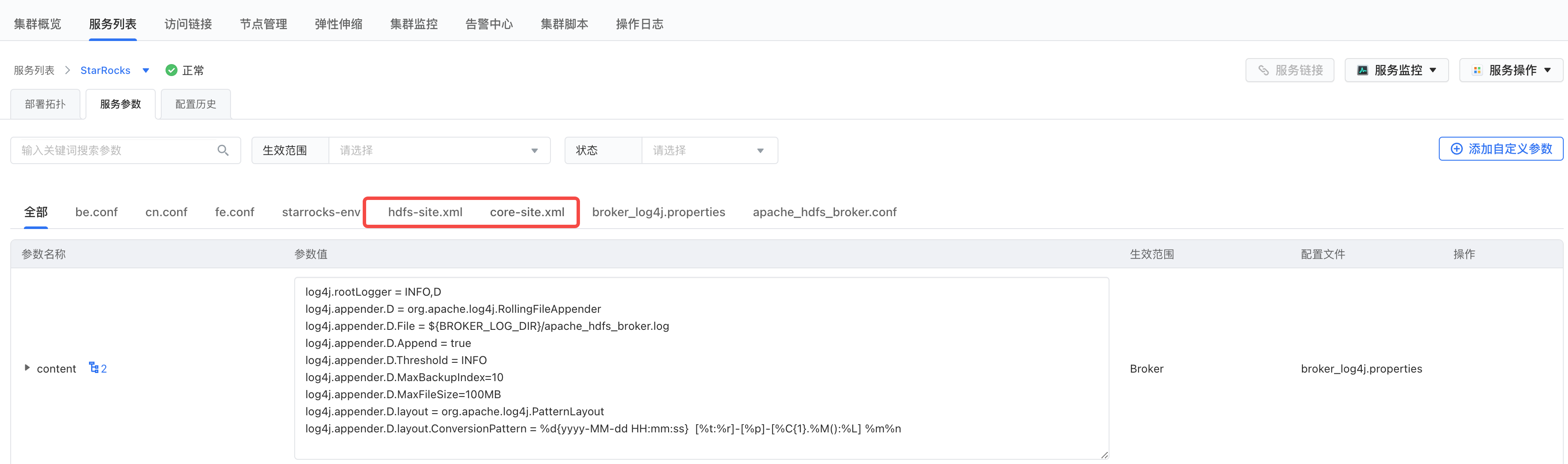
StarRocks 查询 Paimon 表
创建 Catalog
CREATE EXTERNAL CATALOG <catalog_name> [COMMENT <comment>] PROPERTIES ( "type" = "paimon", "paimon.catalog.type" = "hive", "paimon.catalog.warehouse" = "hdfs://nn:8020/path/to/warehouse", "hive.metastore.uris" = "thrift://master-1-1.xxx.emr-volces.com:9083" )
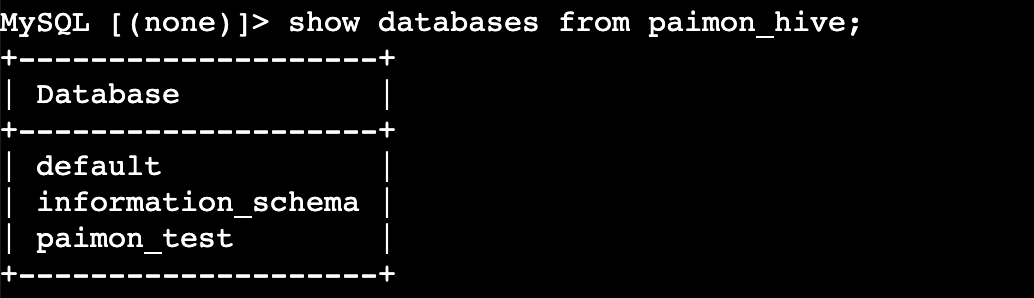
查看 Catalog下的库
SHOW DATABASES FROM <catalog_name>;
使用 Catalog
SET CATALOG <catalog_name>;
查询 Paimon表
SELECT * FROM <table_name>;

Paimon - Doris 集成
数据准备
创建 Hadoop 集群,并安装组件 Spark、Paimon 等必要组件,Hive 根路径选择为 HDFS。
登录 Hadoop 集群,通过 spark-sql 创建 paimon 数据表并插入数据。
-- spark-sql -- 数据表创建 CREATE TABLE IF NOT EXISTS paimon.default.order_detail ( order_id BIGINT NOT NULL, user_id BIGINT, order_amount DECIMAL(10,2), order_status STRING, create_time TIMESTAMP, dt STRING ) USING paimon PARTITIONED BY (dt) OPTIONS ( 'file.format' = 'orc', 'merge.engine' = 'deduplicate', 'bucket' = '4' ); -- 插入测试数据 INSERT OVERWRITE paimon.default.order_detail VALUES (1001, 101, 99.90, 'PAID', TIMESTAMP('2025-01-01 10:00:00'), '20250101'), (1002, 102, 199.90, 'UNPAID', TIMESTAMP('2025-01-01 11:00:00'), '20250101'), (1003, 103, 299.80, 'PAID', TIMESTAMP('2025-01-01 12:00:00'), '20250101'), (1004, 104, 399.70, 'REFUNDED', TIMESTAMP('2025-01-01 13:00:00'), '20250101'), (1005, 105, 499.60, 'PAID', TIMESTAMP('2025-01-01 14:00:00'), '20250101'), (1006, 106, 599.50, 'UNPAID', TIMESTAMP('2025-01-01 15:00:00'), '20250101'), (1007, 107, 699.40, 'PAID', TIMESTAMP('2025-01-01 16:00:00'), '20250101'), (1008, 108, 799.30, 'CLOSED', TIMESTAMP('2025-01-01 17:00:00'), '20250101'), (1009, 109, 899.20, 'PAID', TIMESTAMP('2025-01-01 18:00:00'), '20250101'), (1010, 110, 999.10, 'UNPAID', TIMESTAMP('2025-01-01 19:00:00'), '20250101');
Doris 查询 Paimon 表
创建 Catalog
-- <hadoop cluster address> like master-1-1.emr-ac4d37aae27728b54792.cn-beijing.emr-volces.com DROP CATALOG IF EXISTS <catalog_name>; CREATE CATALOG <catalog_name> PROPERTIES ( 'type' = 'paimon', 'paimon.catalog.type' = 'hms', 'hive.metastore.uris' = 'thrift://<hadoop cluster address>:9083', 'warehouse' = 'hdfs://<hadoop cluster address>:8020/warehouse/tablespace/managed/hive', 'hadoop.username' = 'doris', 'fs.defaultFS' = 'hdfs://<hadoop cluster address>:8020' );
查看 Catalog 下的库
SWITCH <catalog_name>; SHOW databases;
查询 Paimon 表
USE <database name>; SHOW tables; SELECT * FROM <table name>;
Paimon - Dateleap 使用
Flink 使用 HMS Catalog
说明
使用 Hive metastore 作为 Catalog 时,依赖 Flink Hive bunndle,请确保 Flink Hive bundle 已被添加至Flink相关依赖中。
Spark 作业
需要在控制台修改参数spark.driver.extraClassPath,添加 Spark jars 的路径, 如/usr/lib/emr/current/spark3/jars/*。
说明
由于不同版本路径存在差异,请根据实际情况填写。