E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南FlinkFlink 基础使用
E-MapReduce组件操作指南FlinkFlink 基础使用

1 背景信息
通过 SSH 方式登录火山引擎 E-MapReduce(EMR)的服务器,通过命令行提交 Flink 作业。
基于 YARN 模式部署的 Flink 支持 Application 模式、Session 模式以及 Per-Job 模式运维作业。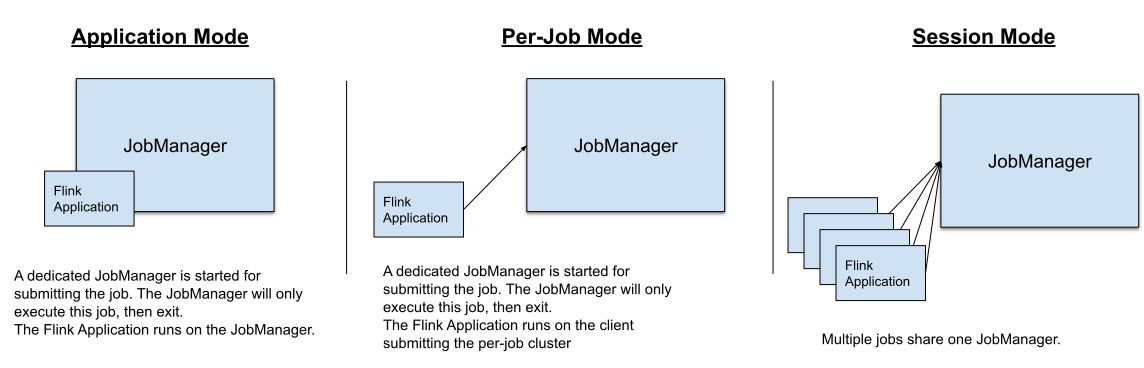
图片来自 Flink 官方文档:https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/overview/#deployment-modes
| 模式 | 描述 | 优缺点 |
|---|---|---|
Application模式 | Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是一个仅在特定应用程序的作业之间共享的 Session 集群,并在所有作业完成时关闭。在整个应用程序的粒度上,Application 模式提供了与 Per-Job 模式相同的资源隔离和负载均衡保证。作业的 main() 方法在 JobManager 上执行,这会降低提交端的 CPU 压力以及节省本地下载依赖所需的带宽 |
|
Per-Job 模式 | Per-Job 模式下每一个作业都会启动一个专属 Flink 集群,各个作业之间不会互相影响,提供了更好的资源隔离保证,作业完成后集群关闭。 |
|
Session 模式 | Session 模式会预先启动一个 flink 集群,可以在该集群中运行多个作业,该集群在作业运行结束之后不会自动释放。作业之间隔离性较差,当某个作业异常导致 Task Manager 退出时,其他所有运行在该Task Manager上的作业都会失败。 |
|
2 使用前提
已创建包含 Flink 组件服务的 EMR 集群。详见 创建集群。
集群的访问链接需要 emr-master-1 节点的 ECS ID 实例绑定弹性公网IP。详见 绑定公网IP。
需要在 集群详情 > 访问链接 > 快速配置服务端口 中,给源地址和对应端口添加白名单才可继续访问。
Flink version:1.16.1。
3 基础使用
3.1 Application 模式
通过 SSH 方式连接集群,详见 登录集群。
执行以下命令,提交作业。
flink run-application -t yarn-application -j /usr/lib/emr/current/flink/examples/streaming/WordCount.jar提交成功后,会返回已提交的 Flink 作业的 YARN Application ID。返回如下类似信息。

执行以下命令,查看作业状态。
flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
也可以通过访问 YARN ResourceManager UI,根据 YARN Application ID 搜索并查看 Flink Web UI执行以下命令,停止作业
flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
3.2 Session 模式
通过 SSH 方式连接集群,详见 登录集群。
执行以下命令,创建 session 集群。
/usr/lib/emr/current/flink/bin/yarn-session.sh --detached创建成功后,会返回 Session 集群的 YARN Application ID。返回如下类似信息。

执行以下命令,提交作业。
flink run -t yarn-session --detached -j /usr/lib/emr/current/flink/examples/streaming/TopSpeedWindowing.jar -Dyarn.application.id=application_XXXX_YY提交成功后,会返回已提交的 Flink 作业的 Job ID。返回如下类似信息

执行以下命令,查看作业状态。
flink list -t yarn-session -Dyarn.application.id=application_XXXX_YY
也可以通过访问 YARN ResourceManager UI,根据 YARN Application ID 搜索并查看 Flink Web UI执行以下命令,停止作业。
flink cancel -t yarn-session -Dyarn.application.id=application_XXXX_YY <jobId>
执行以下命令,停止集群
echo "stop" | /usr/lib/emr/current/flink/bin/yarn-session.sh -id application_XXXXX_XXX
3.3 Per-job 模式
通过 SSH 方式连接集群,详见 登录集群。
执行以下命令,提交作业。
flink run -t yarn-per-job --detached -j /usr/lib/emr/current/flink/examples/streaming/TopSpeedWindowing.jar提交成功后,会返回已提交的 Flink 作业的 YARN Application ID 以及 Job ID。返回如下类似信息。

执行以下命令,查看作业状态。
flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
也可以通过访问 YARN ResourceManager UI,根据 YARN Application ID 搜索并查看 Flink Web UI。执行以下命令,停止作业。
flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
4 DataStream 开发指南
4.1 Pom 依赖
Flink 核心依赖不需要打入最终 jar 包,maven-shade-plugin 插件用来构建 fat jar。下面给了Demo,如需更多信息可参考:Flink打包Pom依赖示例
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <flink.version>1.16.1</flink.version> </properties> <dependencies> <!--flink 核心依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> <scope>provided</scope> </dependency> <!-- kafka connector 依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>${flink.version}</version> </dependency> </dependencies> <build> <finalName>kafka-2-kafka-job</finalName> <plugins> <!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. --> <!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
4.2 Java 实现
import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.connector.base.DeliveryGuarantee; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.sink.PrintSinkFunction; public class Kafka2KafkaJob { private static final String BROKERS = "ip:port,ip1:port1,ip2:port2"; public static void main(final String[] args) { new Kafka2KafkaJob().run(); } private void run() { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.getConfig().setParallelism(1); final KafkaSource<String> source = KafkaSource.<String>builder() .setBootstrapServers(BROKERS) .setTopics("emr-topic-test") .setGroupId("emr-group") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); final DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source"); /* * print sink. */ kafkaSource.addSink(new PrintSinkFunction<>()); /* * kafka sink. */ final KafkaSink<String> kafkaSink = KafkaSink.<String>builder() .setBootstrapServers(BROKERS) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("emr-topic-test-1") .setValueSerializationSchema(new SimpleStringSchema()) .build() ) .setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE) .build(); kafkaSource.sinkTo(kafkaSink); try { env.execute("kafka2KafkaJob"); } catch (final Exception e) { e.printStackTrace(); } } }
4.3 作业 UI 图
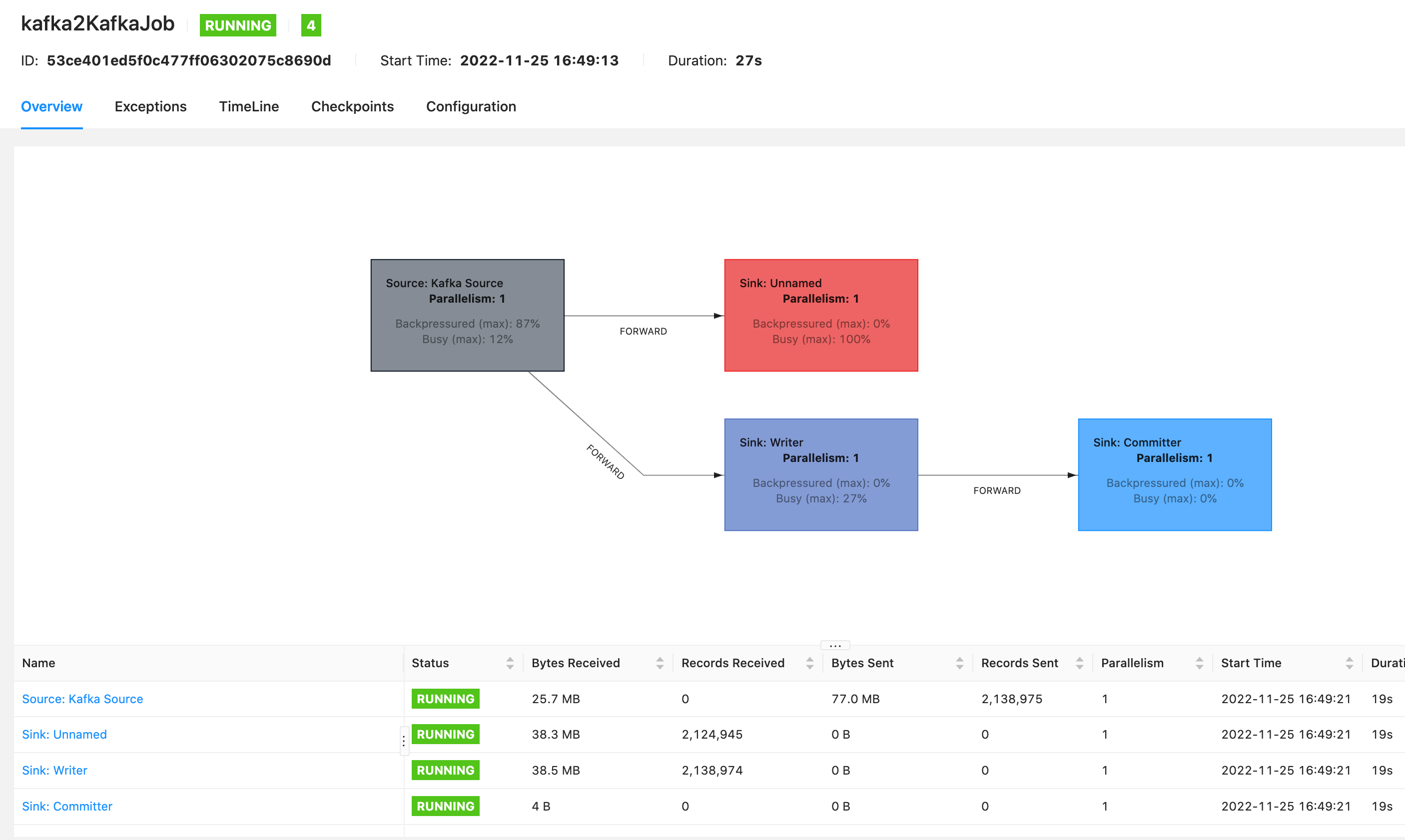
4.4 注意事项:
代码中不可使用匿名类,可使用 lambda 或显示声明的方式。
提交 kafka 作业时需指定父类优先加载 class,以避免依赖冲突,参数为
-D classloader.resolve-order=parent-first