E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南Delta Lake使用说明
E-MapReduce组件操作指南Delta Lake使用说明

1 Delta Lake 简介
Delta Lake 是 Databricks 公司推出的一款表存储格式,是用于构建 Lakehouse 架构的基础组件。Delta Lake 支持 ACID 事务、更新与删除、基于多版本的历史回溯、Schema 校验与演化、流式写入读取等特性,以及支持多个开源生态引擎。
Delta Lake 的表格式形态是介于数据湖形态与数据仓库形态之间的中间形态,它兼具了数据湖的原生数据存储和开放性的优点,也加入了数据仓库才有的事务、数据校验等功能,既解决了数据湖数据混乱难于治理的问题,也解决了数据仓库数据封闭、信息损失以及时效性不强的问题。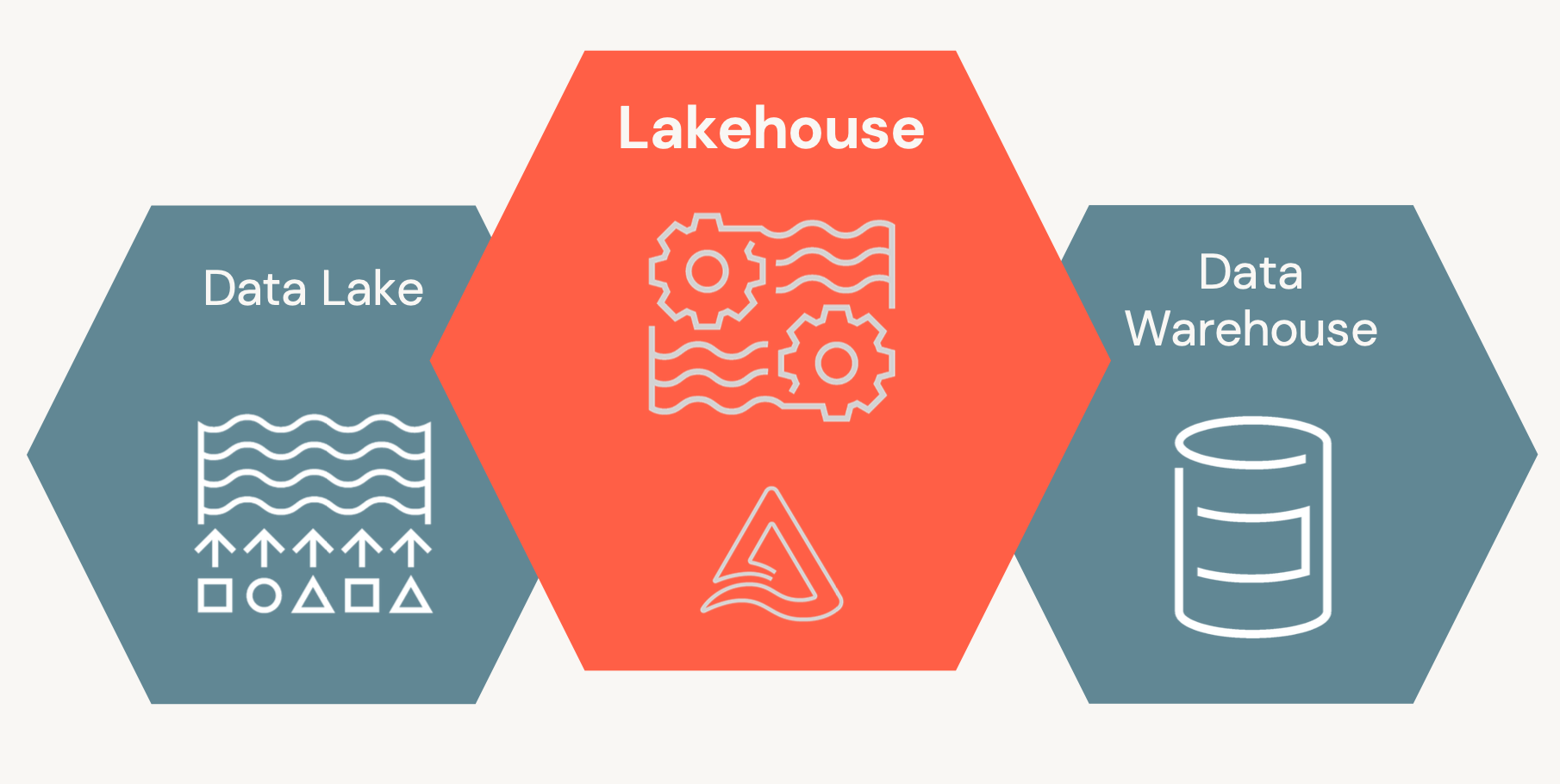 Lakehouse 定位(图片来源于 Spark-Submit 2022)
Lakehouse 定位(图片来源于 Spark-Submit 2022)
基于 Delta Lake 可以构建所谓的 Lakehouse 解决方案,原始数据以流式或者批式的方式写入 Delta Lake,在 Delta Lake 内部完成 Bronze Table 到 Gold Table 的 transform 过程(类比数据仓库的 ODS 到 ADS 的过程)。不论是原始表、中间表和结果表,都支持上层多种查询引擎,数据则存储在大数据存储或者对象存储上。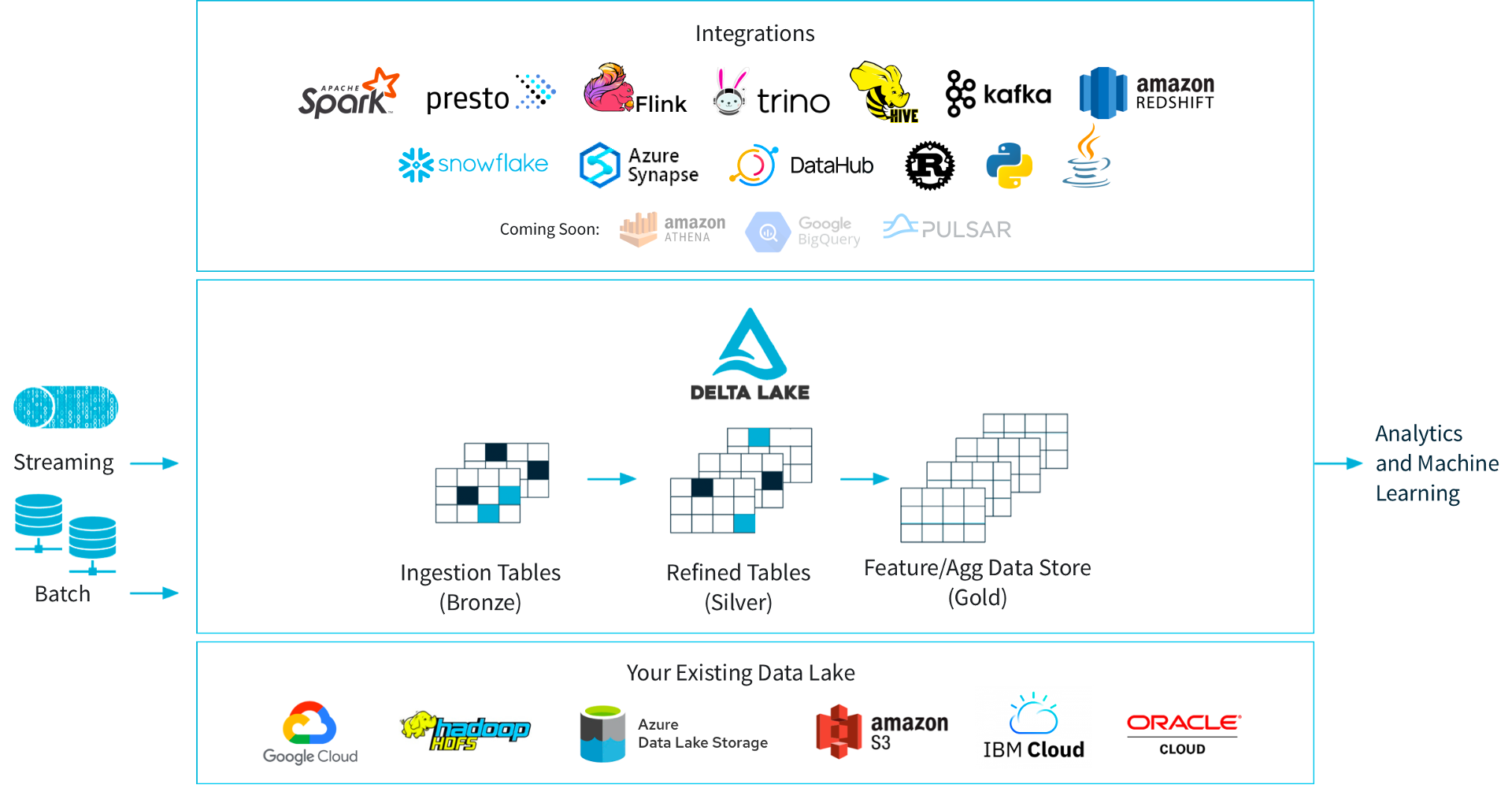 Lakehouse 架构(图片来源于 Delta Lake 官网)
Lakehouse 架构(图片来源于 Delta Lake 官网)
与 Delta Lake 类似的表格式存储还有 Iceberg 和 Hudi,E-MapReduce(EMR) 上对于两者亦有提供,用户可以查阅相关文档。
2 Delta Lake 原理
Delta Lake 与直接使用湖存储最大的区别在于其在湖存储之上引入了一个元数据层。Delta Lake 的所有增加特性都与这个元数据的设计有关。简而言之,这个元数据记录了表的多版本信息,任何对于表的变动都会生成一个新的版本,旧的版本会被保留一段时间,在过期后可以被删除。
其原理如下图所示: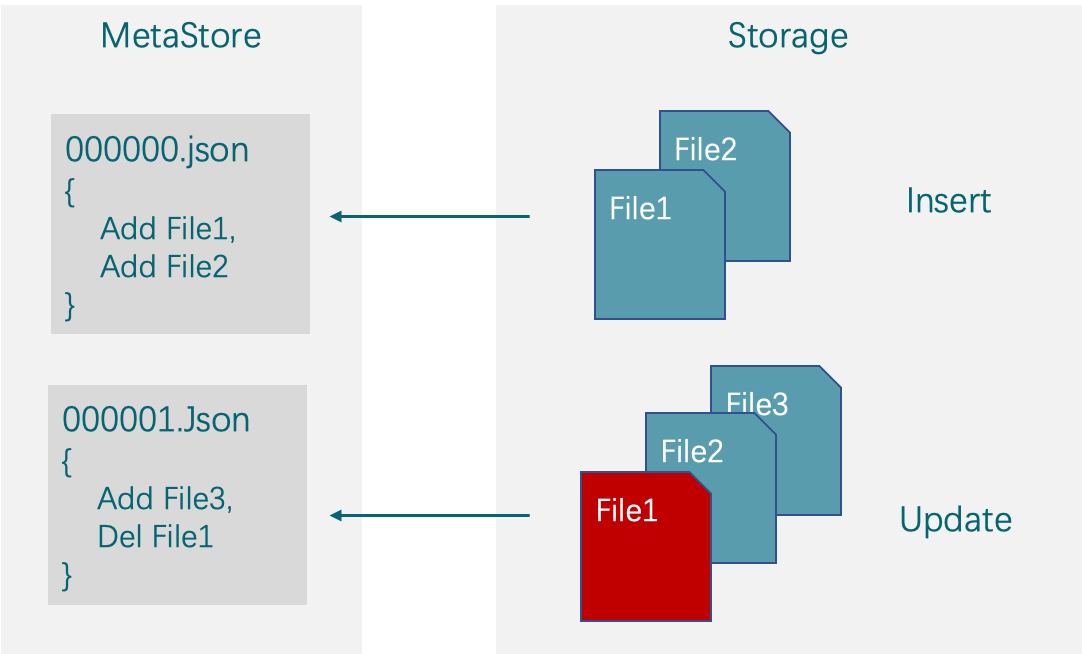
在左侧的元数据层,当我们第一次执行 insert 时,元数据记录了本地 insert 生成的文件 File1 和 File2。第二次操作执行 update 的时候,含有相关被 update 数据的文件 File1 被删除,更新后的数据连同被删除文件中不涉及 update 的数据一起生成新的文件 File3 被写入元数据,同时生成一个新版本。
3 Delta Lake 使用场景
Delta Lake 适用场景如下:
有更新删除的需求
有 Schema 演化的需求
有流式读写的需求
有数据校验的需求
有 CDC 的需求
有在云上对象存储构建数仓的需求
Delta Lake 不适用于
有频繁更新删除的场景,此类场景下,Delta Lake 会因为写放大出现严重的性能下降。
有高并发写的场景,Delta Lake 的事务实现是乐观锁机制,高并发写会造成大量的写资源消耗最后却写失败。
实时性要求非常高(秒级甚至亚秒级)的场景,此类场景下,Delta Lake 会产生大量的小文件,进而影响查询性能。
4 Delta Lake 与 Spark 兼容性列表
Delta Lake 对 Spark 存在比较强的依赖关系:诸如,Delta 2.0.x 依赖于 Spark 3.2.x 及以上,Delta 2.1.x 依赖于 Spark 3.3.x 及以上等。
| Delta Lake version | Apache Spark version |
|---|---|
| 2.1.x | 3.3.x |
| 2.0.x | 3.2.x |
| 1.2.x | 3.2.x |
| 1.1.x | 3.2.x |
| 1.0.x | 3.1.x |
| 0.7.x and 0.8.x | 3.0.x |
| Below 0.7.0 | 2.4.2 - 2.4.<latest> |