E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南StarRocks常见问题
E-MapReduce组件操作指南StarRocks常见问题

1 使用建议
StarRocks 官网优化性能章节提供了一些优化性能的方式。下文为您介绍几种 StarRocks 的性能优化方式。
1.1 如何分桶
Bucket 的个数影响导入和查询性能。建议:
采用高基数的列做分桶,避免出现数据倾斜。
数据压缩后建议 Bucket 的大小为 100MB 至 1GB。因此可以基于表的大小配置 Bucket 的大小:
数据量较小时,按 128M 单桶。
大于 4G 以上的数据,建议按照 1~10G 一个桶。
不建议超过 32 个桶。
在机器比较少的情况下,考虑使用
BE数量 * cpu core / 2来设置 Bucket 数量,这样可充分利用机器资源。不建议采用 Random 分桶方式。建表时,请指定明确的 Hash 分桶列。
1.2 如何选择数据模型
StarRocks 官网数据模型章节详细介绍了四种模式,您可以根据实际情况选择。
一般建议如下:
| 数据模型 | 适用场景 |
|---|---|
明细模型(DUPLICATE KEY) |
|
聚合模型(AGGREGATE KEY) |
|
更新模型(UNIQUE KEY) |
|
主键模型(PRIMARY KEY |
|
1.3 建表注意事项
- 关于 ordery by,在 StarRocks 2.5 版本及以下版本不建议使用。
1.4 删除表注意事项
StarRocks 提供删除表的功能,语句参考如下:
DROP TABLE [IF EXISTS] [db_name.]table_name [FORCE]
执行删除表时,若没有
FORCE关键字,表会被放在回收站中(默认保留1天),这时数据并没有删除掉,可以通过 RECOVER 语句恢复被删除的表。执行
DROP TABLE FORCE,则系统不会检查该表是否存在未完成的事务,表将直接被删除并且不能被恢复。
2 故障排除
2.1 数据导入过程中报 tablet too many version
问题现象:
数据导入过程中报下面的错误信息:
{ "label": "_1693125063307_fe1fc397da6644dd856c2b05211aec1b", "existingJobStatus": null, "txnId": 351688, "status": "Fail", "message": "Too many versions. tablet_id: 177006, version_count: 1002, limit: 1000, replica_state: 0: be:xx.xx.xx.xx", }原因分析:
上述报错是因为导入频率太快,数据没能及时合并 (Compaction) ,从而导致版本数超过支持的最大未合并版本数。默认支持的最大未合并版本数为 1000。
处理步骤:
一般通过增大单次导入的数据量,降低导入频率解决。根据下面步骤查看导入频率:
登录 StarRocks 集群 BE 实例的 ECS 节点上,分析 BE 的日志,该日志所在的目录是:
/var/log/emr/starrocks/be。登录方式详见登录集群。执行下面的命令,查看导入数据的频率:
cd /var/log/emr/starrocks/be/sys cat be.INFO |grep 'new income streaming load ' | grep '${表名}' |grep '${时间点}'说明
BE 的日志配置归档策略,需要根据错误发生的时间,找到 be.INFO 对应的日志文件路径。
参数 ${表名},是数据导入的表名。
参数 ${时间点},是错误发生的时间,如"0906 15:54",是 9月6日15点54分。
遍历所有 BE 实例,查看是否有频率较高的数据导入现象,如 1秒导入2次。
如:下面图,连续时间内,每秒基本 5次 的写入,频率有些高:
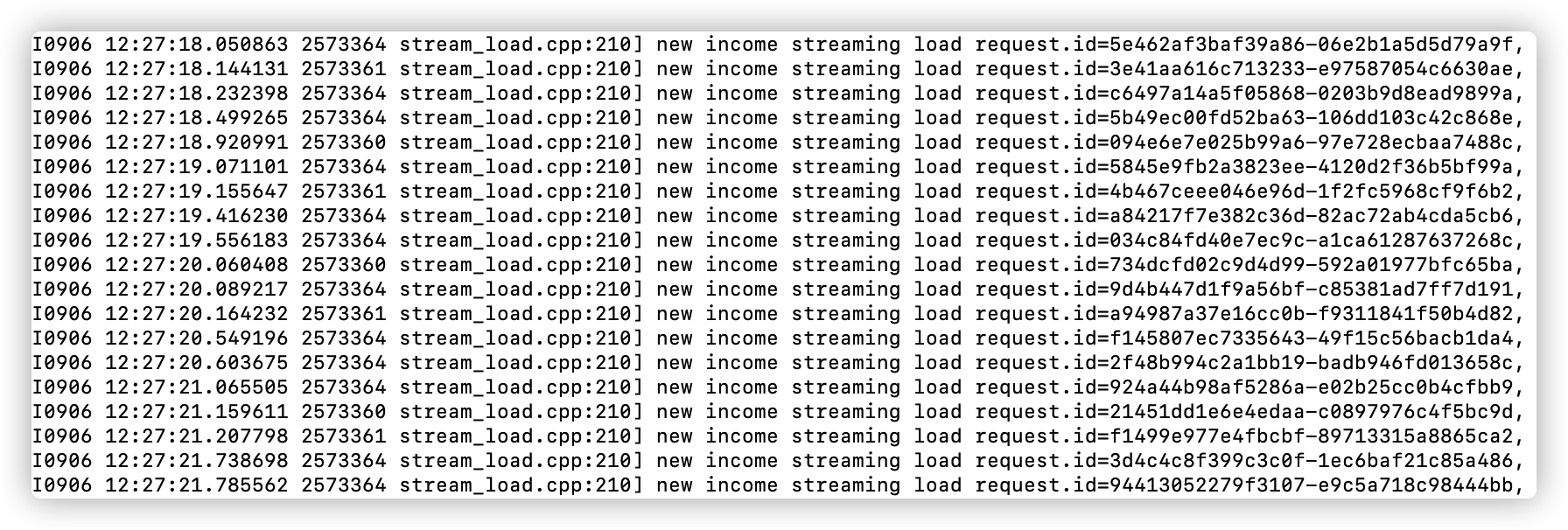
已确认导入频率过高的问题,则增加单次导入的数据量。建议 5秒 导入一次。
若确认不是导入频率过高,可以通过调整合并策略实现加快合并。登录 EMR StarRocks 集群的控制台,在集群详情 > 服务列表 > StarRocks 服务参数中的 be.conf 文件中添加下面参数,并重启 StarRocks。
非主键模型时,参数如下:
cumulative_compaction_num_threads_per_disk = 4 base_compaction_num_threads_per_disk = 2 cumulative_compaction_check_interval_seconds = 2主键模型时,参数如下:
update_compaction_check_interval_seconds = 2 update_compaction_num_threads_per_disk = 2
2.2 数据导入过程中报 The size of this batch exceed the max size
问题现象:
{ "txnId": -1, "existingJobStatus": null, "label": "_1693983827223_815bd46ac1f24c49a984a30281fd3c8e", "status": "Fail", "message": "The size of this batch exceed the max size [104857600] of json type data data [ 300569714 ]. Set ignore_json_size to skip the check, although it may lead huge memory consuming.", "TxnId": -1, "Label": "_1693983827223_815bd46ac1f24c49a984a30281fd3c8e", "Status": "Fail", "ExistingJobStatus": null, "Message": "The size of this batch exceed the max size [104857600] of json type data data [ 300569714 ]. Set ignore_json_size to skip the check, although it may lead huge memory consuming.", "NumberTotalRows": 0, "NumberLoadedRows": 0, "NumberFilteredRows": 0, "NumberUnselectedRows": 0, "LoadBytes": 0, "LoadTimeMs": 0, "BeginTxnTimeMs": 0, "StreamLoadPutTimeMs": 0, "ReadDataTimeMs": 0, "WriteDataTimeMs": 0, "CommitAndPublishTimeMs": 0, "ErrorURL": null }原因分析:
执行 Stream Load 时 JSON Body 的大小过大时则报上述错误,参考官网流式数据源导入参数配置。
处理步骤:
方案一:在 HTTP 请求头中添加
"ignore_json_size:true"设置,忽略对 JSON Body 大小的检查。方案二:在集群的 ECS 实例节点上,对每个 BE 实例执行下面命令,动态修改 BE 参数,即不需要重启 StarRocks,增加 JSON Body 的大小:
curl -XPOST http://${BE地址}:8040/api/update_config?streaming_load_max_batch_size_mb=${size}说明
参数 ${size},根据实际情况配置 JSON Body 的大小。
该参数是动态生效的。当 StarRocks 重启后该参数便生效。
方案三:登录 EMR StarRocks 集群的控制台,在集群详情 > 服务列表 > StarRocks 服务参数中的 be.conf 文件中添加参数:
streaming_load_max_batch_size_mb(默认值为 100),并重启 StarRocks。
2.3 数据导入时报 Mem usage has exceed the limit of BE
问题现象:
Caused by: java.io.IOException: stream load error: Memory of process exceed limit. try consume:2097152 Used: 27644351240, Limit: 27051754291. Mem usage has exceed the limit of BE原因分析:
一般是由于表的 bucker 设置不合理,或者写入数据太小且频率较高, 造成小文件过多。
处理步骤:
估算表的大小,分析 bucket 数量是否合理。一般一个 bucket 大小为 100MB 至 1GB(数据压缩后大小)。
登录 BE 实例的 ECS 节点上,查看数据存储目录(默认是
/data01/ju/output/be/storage/data) 下 Segment 文件增长速度:find /data01/starrocks/be/storage/data -name *.dat |wc -l示例:从数据开始导入,经过两个小时的导入文件数高达20万。导入频率较大,可以增加导入数据的大小

在任务执行过程中分析 BE 的内存消耗,参考官网[管理内存]管理内存。
2.4 数据导入时报 Primary-key index exceeds the limit
问题现象:
stream load error: Primary-key index exceeds the limit. tablet_id: 347620, consumption: 66234184315, limit: 65516516056. Memory stats of top five tablets: 347628(2038M)347640(2038M)347620(2038M)347624(2038M)347644(2038M): be:XX.XX.XX.XX原因分析:
主键索引占有内存过大,可以将其持久化。
处理步骤:
执行下面 SQL 语句,这种主键索引的持久化:
ALTER TABLE ${表名} SET ("enable_persistent_index"="true")说明
- 参数 ${size},根据实际情况配置 JSON Body 的大小。
- 该参数是动态生效的。当 StarRocks 重启后该参数便生效。
- 在开源的 StarRocks 3.x 版本中,参数 enable_persistent_index 默认值已为 true。
2.5 如何查看日志?
日志目录通常在以下路径:
FE
/var/log/emr/starrocks/fe/log
/var/log/emr/starrocks/fe/sys
BE
/var/log/emr/starrocks/be/log
/var/log/emr/starrocks/be/sys