E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南DolphinScheduler快速开始
E-MapReduce组件操作指南DolphinScheduler快速开始

本文通过一系列 DolphinScheduler 的前置准备流程引导您认识服务的使用与相关概念。
1. 前提条件
- 如果您需要使用 DolphinScheduler 服务,请选择火山引擎 E-MapReduce(EMR) 3.1.0 / 2.1.0 及以上版本的 Hadoop 集群类型,不同版本详见:版本概述。
- 集群引入 DolphinScheduler 服务有两种方式:
- 对于已安装 DolphinScheduler 服务的集群,需要为该服务所在的 ECS 实例绑定弹性公网 IP,并配置服务端口(DolphinScheduler 默认的服务端口是 12345)才能访问 DolphinScheduler Web UI,详见访问链接。
2. 登录认证
访问 DolphinScheduler Web UI 需要您提供登录认证信息。
EMR DolphinScheduler 服务使用 OpenLDAP 进行登录认证,使用默认的admin账户作为服务管理员,您可以在集群的 master-1-1 机器上获取该用户的密码,密码文本文件所在位置为 /root/.emr/secret。
3. 创建队列
DolphinScheduler 在执行 Spark、Flink 等类型任务时,可能需要指定到特定的 YARN 队列上。
假设该队列已经在 YARN 中创建完毕,进一步的需要我们在 DolphinScheduler 中做相应的配置,可参考如下步骤进行创建队列操作:
- 进入 DolphinScheduler 集群详情 > 访问链接界面。
- 单击 DolphinScheduler UI 访问链接,输入获取的账号密码信息,进入到可视化 UI 界面。
说明
访问链接使用前提:
- 在界面导航栏中,单击进入安全中心 > Yarn 队列管理界面。
- 单击创建队列按钮,输入队列名和队列值,单击确定按钮,完成创建。
4. 创建租户
租户映射到一个操作系统用户,作为 Worker 进程提交作业时使用的用户。如果界面上配置的租户名称在系统中实际并不存在,则会导致任务运行失败。具备管理员权限的账号可以通过 DolphinScheduler Web UI 创建租户,在 Web UI 界面执行如下步骤:
- 在界面上方导航栏中,单击进入安全中心 > 租户管理界面。
- 单击创建租户按钮,输入操作系统租户名称,单击确定按钮,完成租户创建。
- 如果对应的用户在操作系统中并不存在,则可以通过 EMR 提供的
用户管理功能进行用户创建,用户管理功能详情请参考:用户管理文档。
5. 创建用户
DolphinScheduler 服务的用户分为管理员和普通用户两类:
- 管理员:具备对包括安全中心在内的完整功能进行操作的权限。
- 普通用户:可以创建项目,对工作流定义执行创建、编辑,以及执行等操作。
EMR DolphinScheduler 开箱已经接入 EMR OpenLDAP 认证系统,因此用户的创建需要通过用户管理进行。
DolphinScheduler 在使用时,需要为每个用户关联一个租户,并在操作系统层面由关联的租户执行该用户提交的工作流任务。
注意
当用户关联的租户由 A 变更为 B 时,则该用户所在租户 A 名下的所有资源将复制到租户 B 名下。
5.1. 用户权限管理方式
开箱集群未经配置,在用户管理中创建的用户,默认都是普通用户的权限。
DolphinScheduler 通过配置security_authentication_ldap_user_admin的值,来决定哪个账户拥有管理员用户权限。通过将该配置指向一个尚未登录过的用户名,并通过用户管理创建同名用户并登录,该用户便直接拥有管理员权限。
6. 告警配置
在启动工作流时可以设置告警组参数,DolphinScheduler 会将工作流实例执行期间的各种状态信息,以告警组关联的告警实例中预先定义的插件方式进行投递。
6.1. 创建告警组实例
在创建告警组之前需要先创建告警实例,每个告警实例关联一种具体的通知方式,一个告警组可以同时关联多种告警实例以实现多样化的告警通知。告警实例的创建步骤如下:
单击进入安全中心 > 告警实例管理界面。
单击创建告警实例按钮,输入以下信息(已 Feishu 插件为例),完成创建:
配置项
说明
告警实例名称
输入告警实例名称信息。
选择插件
目前已支持 Script、WeChat、Email、Feishu、Http等十余种中告警插件方式。
告警类型
您可选择 success、failure 或 all 的告警类型。
Web钩子
输入插件对应的 Webhook 地址。
启用代理
判断告警实例是否需要启用代理,若启用代理,需完成以下信息的填写。
代理
输入代理地址信息。
端口
代理对应的端口号信息。
用户
输入身份验证的用户信息。
密码
输入身份验证时所需的密码信息。
不同插件,需填写不同的配置信息,视界面实际情况而定。详见告警插件指导。
6.2. 创建告警组
DolphinScheduler 通过告警组实现将工作流任务与具体的告警实例之间进行关联。一个告警组可以同时关联多个告警实例,具体的创建步骤如下:
单击进入安全中心 > 告警组管理界面。
单击创建告警组按钮,输入以下信息,完成创建:
配置项
说明
告警组名称
输入告警组名称信息
告警组实例
选择已创建成功的告警组实例信息,支持多选。
描述
输入告警组描述信息,方便后续管理。
7. 创建 Worker 分组
DolphinScheduler 支持对 Worker 节点进行分组,并需要在执行工作流任务时指定具体的 Worker 节点分组。DolphinScheduler 默认定义并使用 default 分组,我们也可以按需对 Worker 节点进行自定义分组,具体操作如下:
单击进入安全中心 > Worker 分组管理界面。
单击创建 Worker 分组按钮,输入以下信息,完成创建:
配置项
说明
分组名称
输入 Worker 分组名称
Worker 地址
下拉选择当前集群的 Worker Server 地址。
8. 创建环境
环境配置作用于 Worker 节点实际运行任务时的环境变量配置,每个环境配置等价于一份 dolphinscheduler_env.sh 文件。Worker 节点默认使用 dolphinscheduer_env.sh 文件中预定义的内容,如果需要修改可以按照如下图所示进行操作:
单击进入安全中心 > 环境管理界面。
单击创建环境按钮,输入以下信息,完成创建:
配置项
说明
环境名称
输入环境名称
环境配置
默认环境为 dolphinscheduler_env.sh 文件内容,您可根据实际业务场景,进行环境修改配置。
环境描述
输入环境描述信息,便于后续管理环境。
Worker 分组
下拉选择已创建成功的 Worker 分组信息。
环境配置参考:
# JAVA_HOME, will use it to start DolphinScheduler server export JAVA_HOME=${JAVA_HOME:-/usr/lib/jvm/java-8-openjdk-velinux-amd64} # Tasks related configurations, need to change the configuration if you use the related tasks. export HADOOP_HOME=${HADOOP_HOME:-/usr/lib/emr/current/hadoop} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/emr/hadoop/conf} export SPARK_HOME1=${SPARK_HOME:-/usr/lib/emr/current/spark} export HIVE_HOME=${HIVE_HOME:-/usr/lib/emr/current/hive} export FLINK_HOME=${FLINK_HOME:-/usr/lib/emr/current/flink} export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$PATH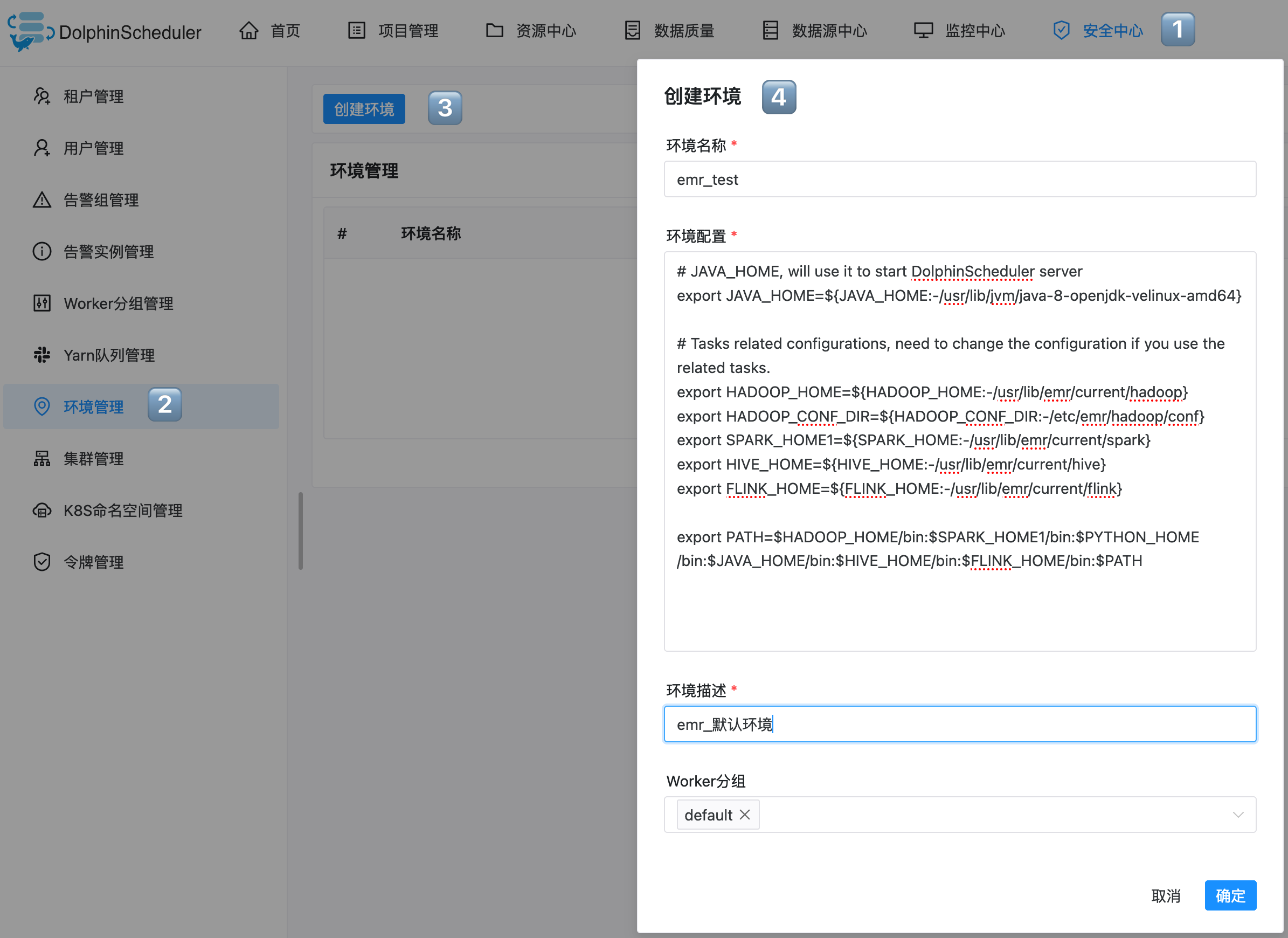
9. 创建 Token 令牌
DolphinScheduler 的后端接口都有准入认证,使用令牌在保证安全的同时也能够更加方便用户对于后端接口的调用。通过 DolphinScheduler Web UI 可以按照如下所示步骤创建并管理 Token 令牌:
单击进入安全中心 > 令牌管理界面。
单击创建令牌按钮,输入以下信息,完成创建:
配置项
说明
失效时间
设置令牌失效时间,有效限制对接口的调用。
用户
选择该令牌对应的用户信息,便于用户自行管理
令牌
主动生成的令牌信息,可通过右侧的刷新按钮,来刷新生成新的令牌信息。
说明
管理员可以管理所有用户的令牌信息,普通用户则只允许操作自己的令牌信息。
10. 编排工作流
在配置好上述信息之后,我们可以为普通用户分配账号,并允许普通用户开始使用 DolphinScheduler 编排和执行工作流任务。
10.1 创建项目
工作流按照项目进行组织,所以在创建工作流之前需要在项目管理页面中选择或创建对应的项目信息:
切换对应的用户信息,重新进入到 DolphinScheduler Web UI 界面中。
在界面上方导航栏中,单击进入项目管理界面。
单击创建项目按钮,完成以下项目参数配置:
配置项
说明
项目名称
输入项目名称,来区分管理不同的工作流。
所属用户
项目默认归属当前登录的用户。
项目描述
输入项目描述信息,便于后续项目管理。
完成信息配置后,单击确定按钮,完成项目创建。
10.2 创建工作流定义
单击创建成功的项目名称, 进入到项目概览详情页,在具体项目左边栏可以看到项目概览、工作流,以及任务等选项卡。
单击“工作流 > 工作流定义 > 创建工作流”进入工作流编排页面。DolphinScheduler 提供了丰富的任务类型,以支持复杂多样的工作流编排场景。您可以参考官方任务类型文档了解每种任务类型的具体参数配置。
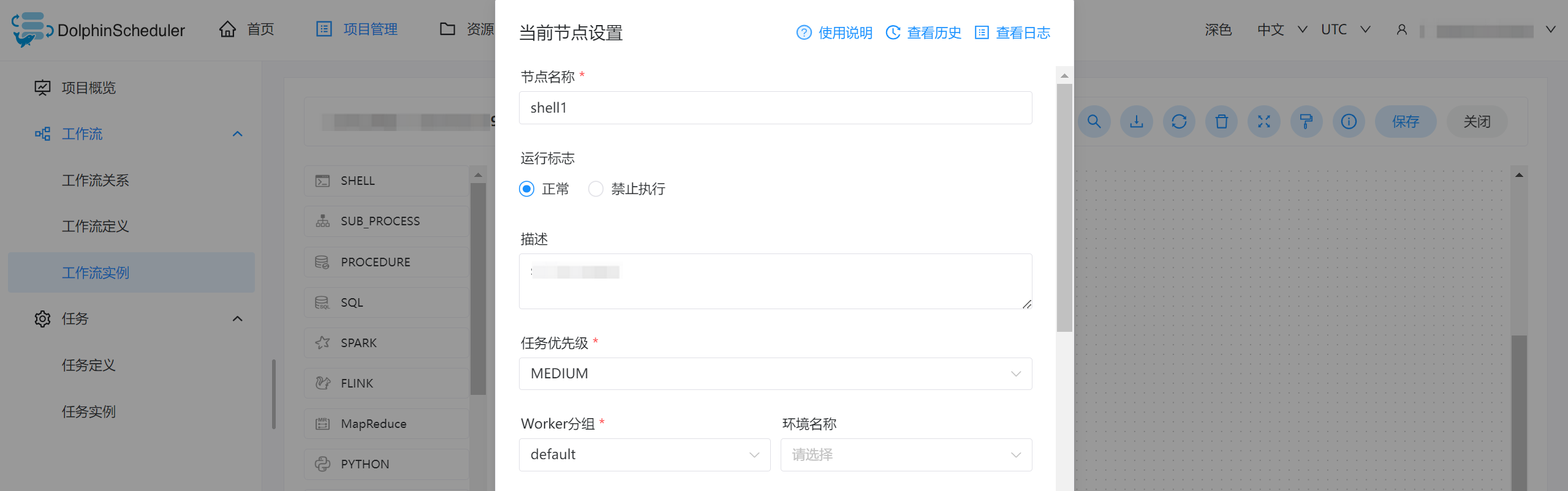
您可以用拖拽的方式,将对应的任务类型,拖拽到右侧编辑区,工作流节点设置如下(以 shell 节点配置为例):
参数 | 说明 |
|---|---|
节点名称 | 输入任务类型的节点名称信息。 |
运行标志 | 选择任务运行的状态,支持选择正常、禁止执行,若勾选“禁止执行”,运行工作流不会执行该任务。 |
描述 | 为当前节点填写任务描述信息,方便后续区分。 |
任务优先级 | 选择当前任务的优先级情况,从 HIGHEST 到 LOWSET 分为5个等级,您可根据实际情况进行选择,当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行。 |
Worker 分组 | 下拉选择已创建成功的 Worker 分组信息。 |
环境名称 | 配置任务执行的环境,下拉选择已创建成功的环境名称。 |
任务组名称 | 通过任务组来管理任务实例占用的资源,避免占用太多资源导致了集群其他组件受到资源上的影响。您可在资源中心 > 任务组管理中,创建任务组信息。详见任务组管理。 |
组内优先级 | 设置该任务,在当前任务组内的优先级,在同个任务组内优先获得资源。 |
失败重试次数 | 任务失败重新提交的次数,可进行手动填充。 |
失败重试间隔 | 任务失败重新提交任务的时间间隔,可以进行手动填充。 |
CPU 配额 | 为执行的任务分配指定的CPU时间配额,单位为百分比,默认-1代表不限制,例如1个核心的CPU满载是100%,16个核心的是1600%。 |
最大内存 | 为执行的任务分配指定的内存大小,超过会触发OOM被Kill同时不会进行自动重试,单位MB,默认-1代表不限制。 |
延时执行时间 | 任务延迟执行的时间,以分为单位。 |
超时告警 | 设置超时告警、超时失败。当任务超过"超时时长"后,会发送告警邮件并且任务执行失败。 |
脚本 | 编辑对应任务类型的代码信息。 |
资源 | 任务执行时所需资源文件。 |
自定义参数 | 填写任务脚本中所需的自定义参数信息。 |
前置任务 | 设置当前任务的前置(上游)任务,形成上下游依赖关系。 |
配置信息填写完成后,单击确定按钮,完成节点配置,并单击右上角保存按钮,设置工作流的信息和全局参数等。
10.3 运行工作流任务
- 上线工作流:
对于创建好的工作流定义需要在发布上线之后才允许被执行,单击操作栏中的上线按钮,便可以实现对具体工作流的发布上线操作:
- 运行工作流:
对于已完成发布上线的工作流,可以单击运行按钮,触发工作流立即执行,或单击定时按钮配置对应的周期性调度规则。
在工作流 > 工作流实例页面可以查看本次运行的工作流实例,并支持对该工作流进行编辑、重跑等一系列快速操作,如下图所示:
- 查看日志:
如果需要查看任务的执行历史或日志信息,可以单击具体工作流实例中的某个节点,进入节点编辑区域,双击任务类型,在弹窗的右上角我们可以看到对应的查看历史或查看日志入口。