E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce产品简介应用场景EMR on ECS 应用场景
E-MapReduce产品简介应用场景EMR on ECS 应用场景

应用场景
云原生数据湖仓
数据湖仓是一种结合了数据湖和数据仓库的新型数据架构,实现了更加灵活、高效和可扩展的数据管理,能够协助企业更好的理解和使用数据资产,提升业务价值。以互联网行业为例,企业需要搭建数据分析平台,聚合APP和日志数据分析客户行为支持精准营销,辅助分析决策。但自建开源大数据平台时,往往面临管理维护人力投入大,资源成本高且不灵活等问题。
火山引擎EMR提供丰富的主流开源大数据组件,100%开源兼容,支持平滑迁移和长期演进。提供企业级组件优化和管控能力,帮助企业开发运维降本增效。一个架构支撑完整能力的数据湖仓方案,支持EB级别的数据仓库、湖内建仓、湖仓一体等。配合火山引擎大数据研发治理套件DataLeap和全域数据集成DataSail等产品,可实现一站式数据集成研发治理方案。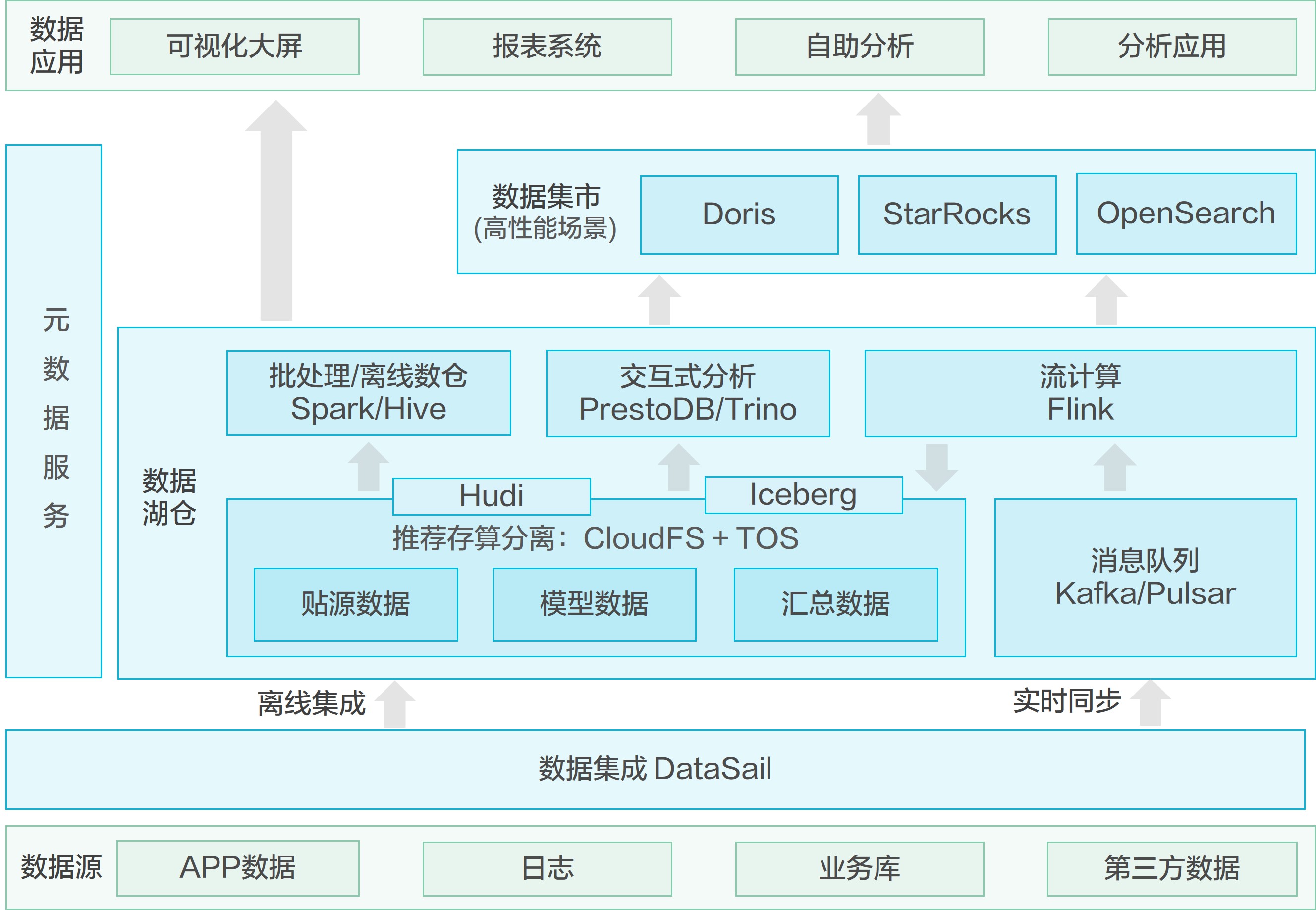
实时数仓
实时数仓对数据实时性,data serving,并发等都有较高的要求,离线分析系统无法满足该类需求。实时数仓场景具备如下特点:
- 支持流式入仓,数据秒级可见;
- 支持高并发数据服务,支持万级QPS;
- 秒级或亚秒级数据查询性能;
- 支持实时指标聚合,支持多维分析。
企业可基于EMR Doris/StarRocks构建实时数仓。数据入仓后,经过流式计算,明细数据进入Doris/StarRocks集群ODS层,数据聚合计算后进入DWS层,数据指标经计算后存入ADS层。数据支撑在线更新。由Doris/StarRocks对数据应用层提供服务,支持在线、离线查询分析,支持几十万级QPS。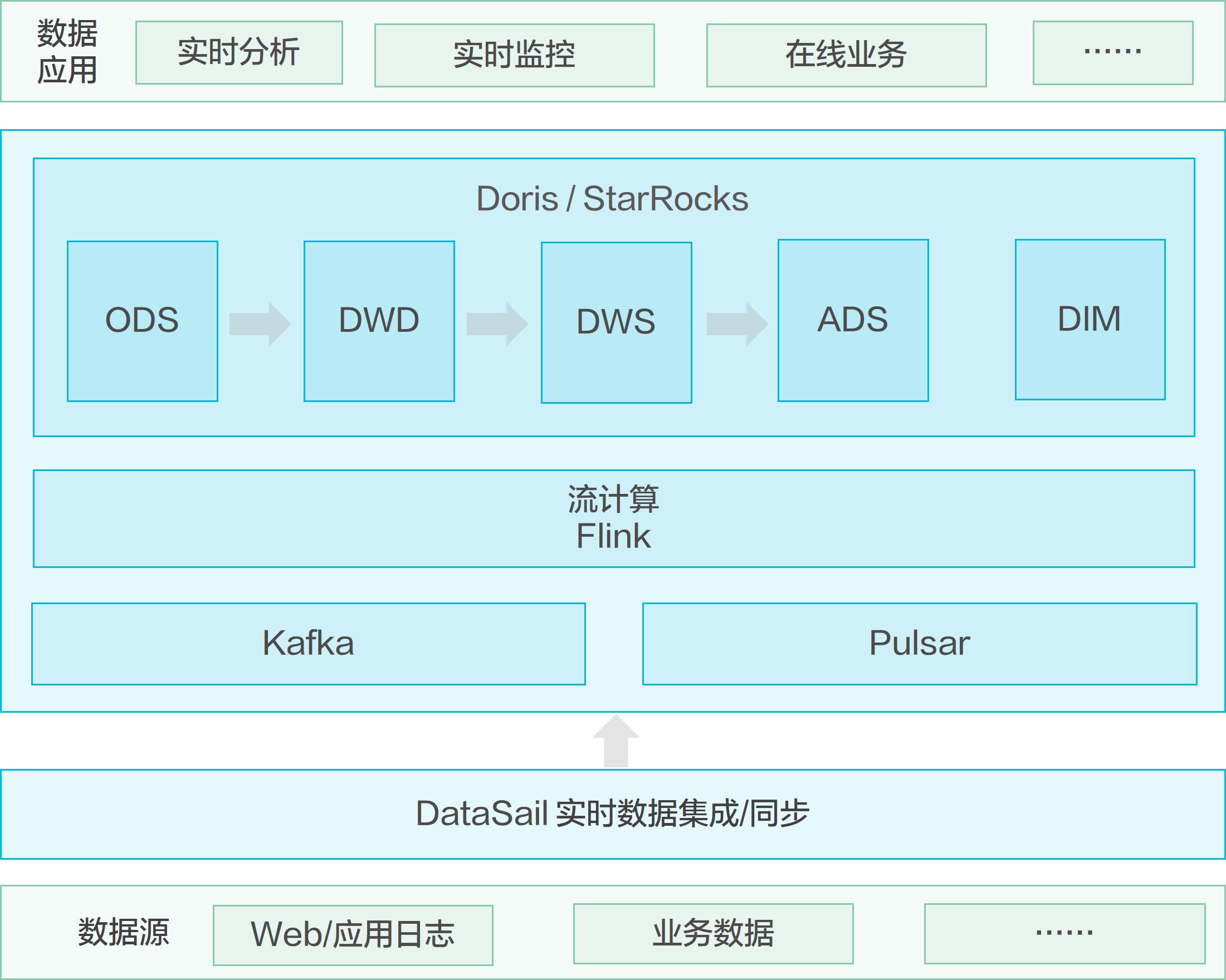
离线/批量数据分析
海量数据离线处理分析是大数据分析系统中的通用场景,企业将多种类型业务系统数据源的数据进行采集、导入、清洗转换,加工形成满足业务分析模型需要的数据组织,支撑企业各业务部门基于统一集中的数据进行分析决策。离线/批量数据分析场景具备如下特点:
- 数据量大,通常达到TB~PB级;
- 存在不同类型的数据源,如文件、日志、结构化数据等;
- 数据处理的时效要求在数十分钟或小时级或天级,实时性要求不高;
- 海量数据处理采取分布式并行处理,计算和存储资源可以基于数据规模进行灵活扩展。
例如互联网行业,采集网银日志、营销系统、交易系统等多源数据,分析和统计客户行为,支持精准营销应用。企业将所需数据抽取到大数据平台后,存储到Hive/HDFS中,或者采用存算分离架构存储在对象存储TOS中。每天在固定时段通过Hive/Spark计算引擎对数据进行加工处理,生成相关数据应用指标统计数据,T+1日提供给数据应用访问。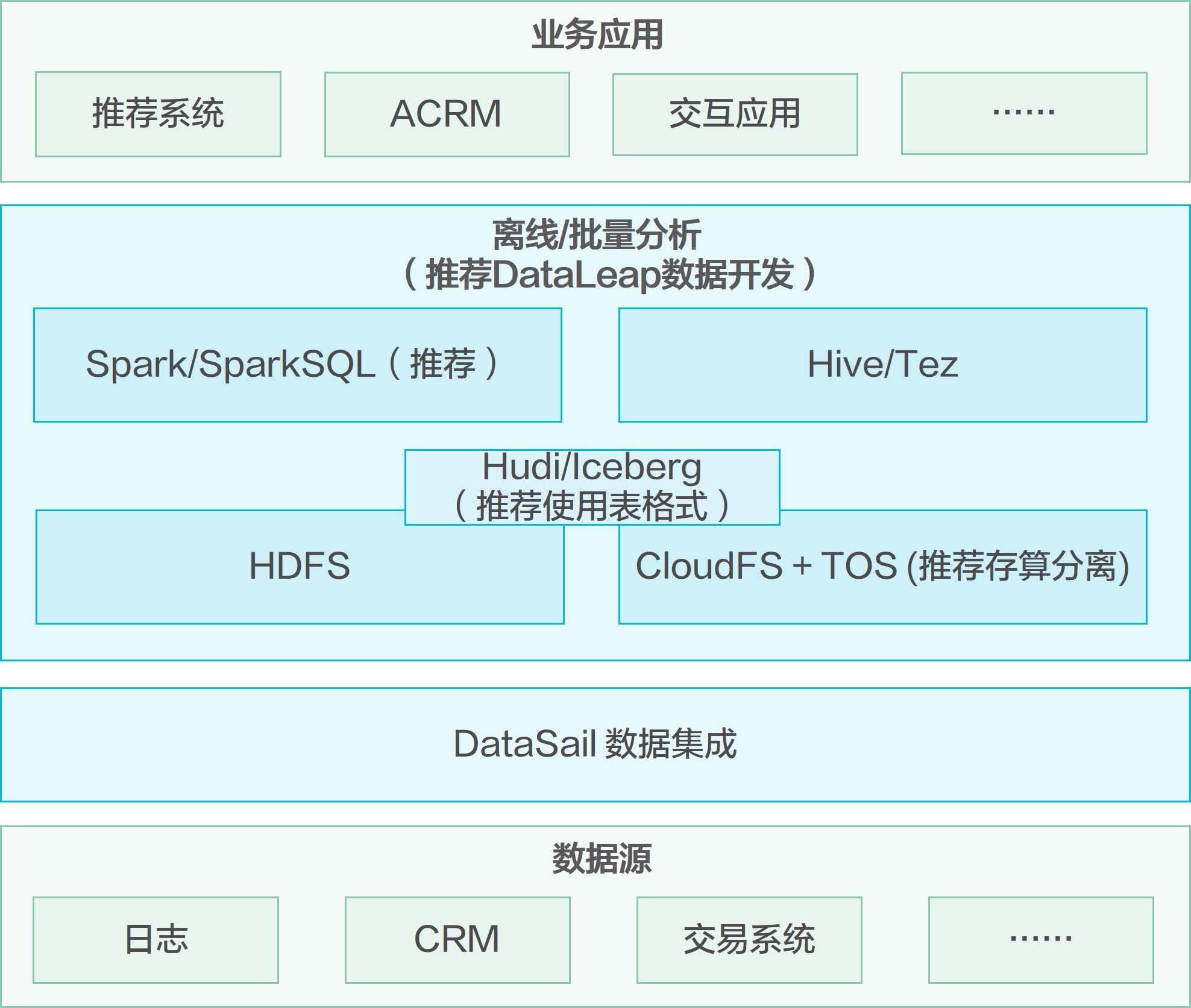
实时/流式计算
随着IoT、实时风控、实时监控等业务需求增长,实时数据处理分析在大数据分析场景中越来越重要,数据流需要实时采集接入,并进行实时处理分析和触发动作。实时/流式计算场景具备如下特点:
- 处理时间要求极高,毫秒~秒级;
- 处理数据量每秒达到数百兆;
- 数据格式以各种网络协议格式为主;
- 占用计算资源多。
以某车联网行业为例,企业实时采集运营数百辆新能源汽车行驶和电池数据,进行实时分析和告警,数据采集为分钟级粒度,日增量在数十GB规模。数据通过消息队列Kafka或Pulsar汇聚到大数据平台,使用Flink流计算引擎进行毫秒级实时指标计算,计算结果存储到OLAP引擎或RDS中供平台进行实时数据展示。