E-MapReduce
E-MapReduce



EMR on ECS

请输入


- 文档首页
 E-MapReduceEMR on ECS 最佳实践火山引擎 EMR 迁移指南元数据迁移
E-MapReduceEMR on ECS 最佳实践火山引擎 EMR 迁移指南元数据迁移

元数据迁移
迁移和部署 Apache Hive 到火山引擎 EMR
Apache Hive 是一个开源的数据仓库和分析包,它运行在 Apache Hadoop 集群之上。Hive 元存储库包含对表的描述和构成其基础的基础数据,包括分区名称和数据类型。Hive 是可以在火山引擎 E-MapReduce(简称“EMR”)上运行的服务组件之一。
火山引擎 EMR 集群的 Hive 元数据可以选择内置数据库和外置数据库。
- 内置数据库作为 Hive 元数据建议只应用于开发和测试环境。
- 使用火山引擎 RDS 作为 Hive 元数据
外置数据库可以是火山引擎的 RDS 数据库或者客户在 ECS 上部署的数据库实例。
创建集群时,可以选择外置数据库作为 Hive 元数据。外置数据库可以是客户购买的火山引擎 RDS 实例。
Hive 元数据迁移
如果元数据更新不频繁,可以使用 beeline 或 Mysql dump 完成 hive metastore 的数据迁移
- 使用 beeline 进行元数据迁移
使用 beeline 获取源 Hadoop 集群建表语句,并在 EMR Hadoop 集群执行。
beeline -u "jdbc:hive2://emr-master-1:10000" -n hive -p <password> -e "show create table test;"- 使用 mysqldump 进行元数据迁移
使用 mysqldump 导出源端元数据,并在 EMR Hadoop 集群导入。
#源端 Hadoop 集群导出数据 mysqldump -uhive -ppassword --no-create-info --databases hive >/tmp/hive-meta.sql #目标 EMR 集群导入数据 mysql -uhive -ppassword -Dhive < hive-meta.sql- 使用 beeline 进行元数据迁移
如果元数据更新频繁,可以使用数据库传输服务搭建数据复制链路。
火山引擎数据库传输服务(DTS)支持不同数据库实例之间的数据同步,对于频繁更新的元数据,源端的修改会实时的同步到目标端。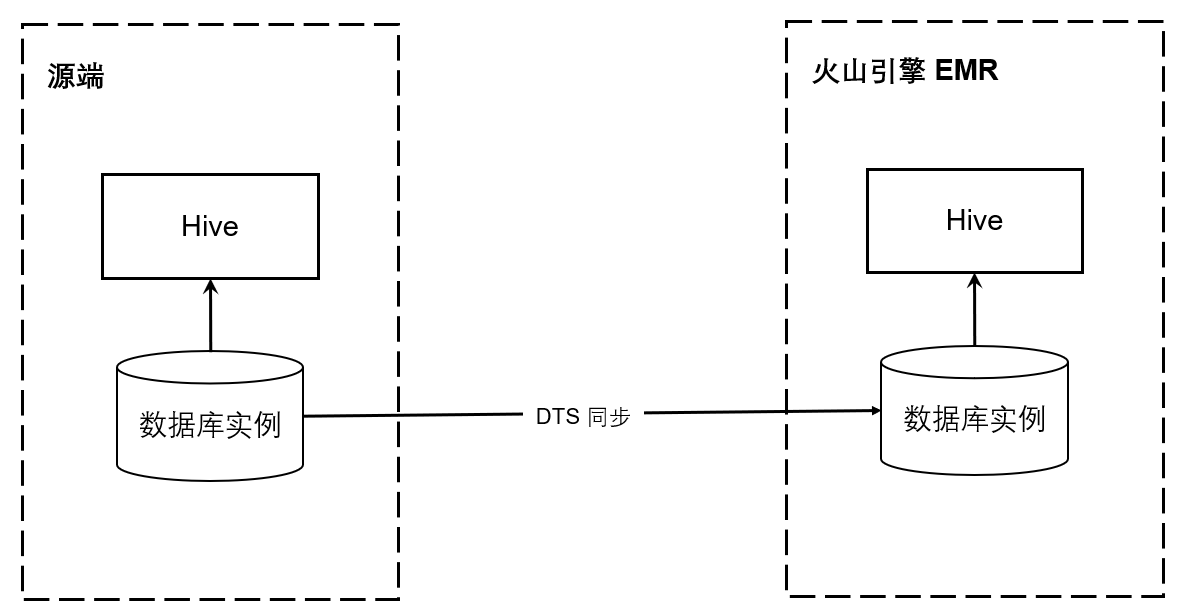
Hive 2.x 迁移至 Hive 3.x
Hive 3 和 Hive 2 相比,增加了许多新特性(Hive 3.0 Release)。您如果想要使用 Hive 3.x 或者 Spark 3.x、 Hadoop 3.x 需要先将Hive 2.x 升级至 Hive 3.x。您可以使用 Hive SchemaTool 将 Hive 2.x 迁移至 Hive 3.x 版本。 SchemaTool的使用参考。
迁移前需要做好 Hive 元数据的备份,确认 Database、Table 数量,用于迁移后的校验。hive --service schemaTool -upgradeSchema操作期间要求停止 Hive 服务,执行后通过hive —service metatool -updateLocation <new-loc> <old-loc> 更新 Hive 表的 Location 地址。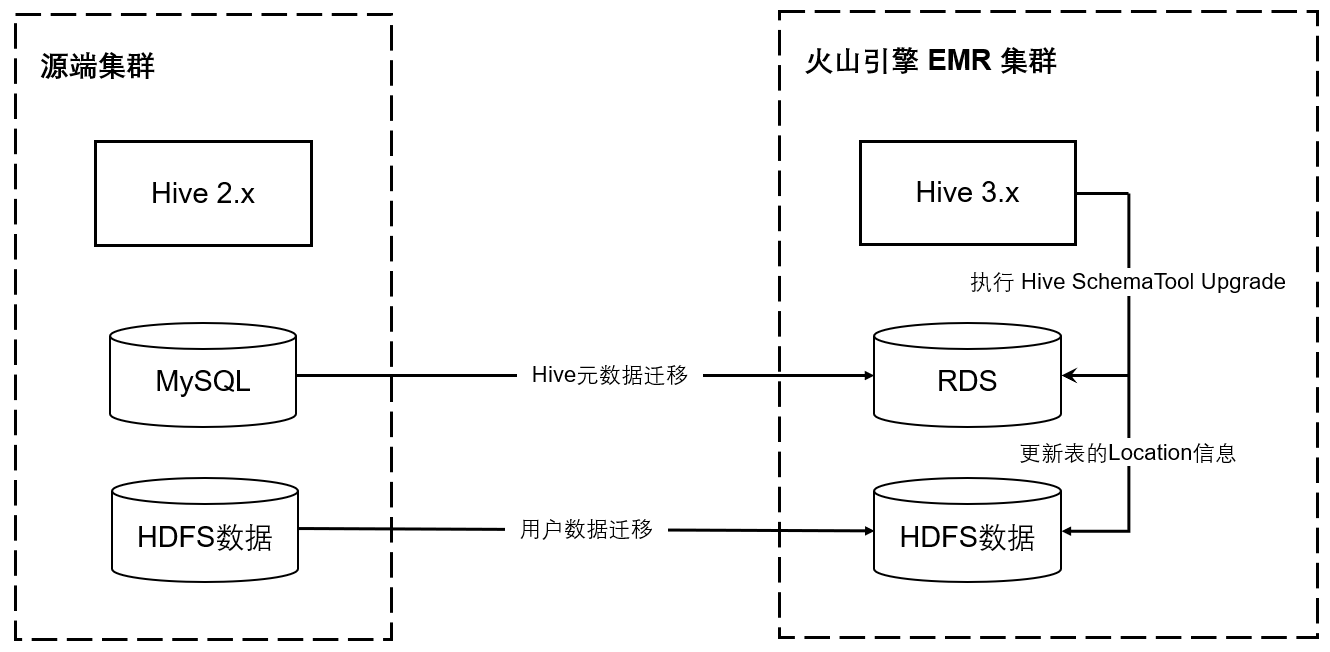
最近更新时间:2025.01.07 16:19:44
这个页面对您有帮助吗?
有用
有用
无用
无用