E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南Livy使用说明
E-MapReduce组件操作指南Livy使用说明

1 Livy 介绍
Apache Livy 是一个 Rest 服务,允许用户通过 Rest API 向 Spark cluster 提交作业。它的架构如下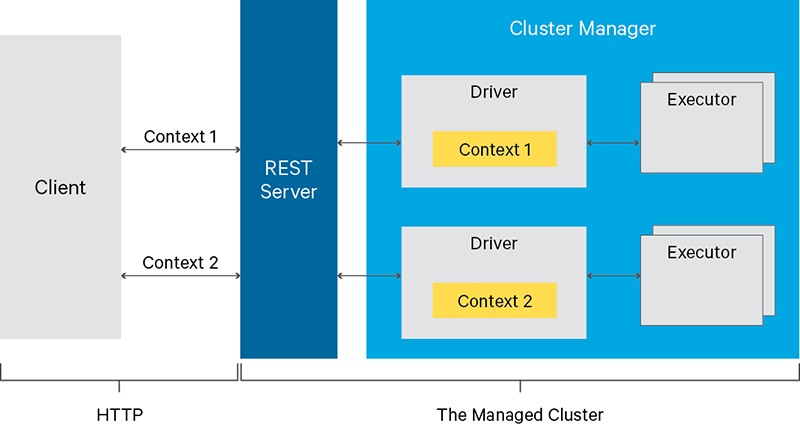
用户通过 Rest API 向 livy server 提交作业请求,之后 server 会向 cluster manager(通常是 yarn)提交 spark 作业。Spark 作业以 cluster 模式运行,即 spark context 运行在 cluster 内,而非 livy server 中,之后 Livy 以 session 来管理这些 spark 作业。
2 Livy 入门
2.1 Rest API
Session 是 Livy 中一个非常重要的概念,几乎所有的操作都围绕它展开。
下面是一个例子:
import json, pprint, requests, textwrap # 1. open 一个 session host = 'http://localhost:8899' data = {'kind': 'spark'} headers = {'Content-Type': 'application/json'} r = requests.post(host + '/sessions', data=json.dumps(data), headers=headers) r.json() {u'state': u'starting', u'id': 0, u'kind': u'spark'} # 2. 查询一下 session 状态,新建好的 session 处于 idle 状态 session_url = host + r.headers['location'] r = requests.get(session_url, headers=headers) r.json() {u'state': u'idle', u'id': 0, u'kind': u'spark'} # 3. 发送一段代码,这段代码就是 spark 计算 Pi 的代码。这个时候 session 处于 running 状态,cluster 上的 spark 作业也运行起来了 data = { 'code': textwrap.dedent(""" val NUM_SAMPLES = 100000; val count = sc.parallelize(1 to NUM_SAMPLES).map { i => val x = Math.random(); val y = Math.random(); if (x*x + y*y < 1) 1 else 0 }.reduce(_ + _); println(\"Pi is roughly \" + 4.0 * count / NUM_SAMPLES) """) } r = requests.post(statements_url, data=json.dumps(data), headers=headers) pprint.pprint(r.json()) # 4. 获取计算结果 statement_url = host + r.headers['location'] r = requests.get(statement_url, headers=headers) pprint.pprint(r.json()) {u'id': 1, u'output': {u'data': {u'text/plain': u'Pi is roughly 3.14004\nNUM_SAMPLES: Int = 100000\ncount: Int = 78501'}, u'execution_count': 1, u'status': u'ok'}, u'state': u'available'} # 5. 关闭 session,spark context 随即退出 session_url = 'http://localhost:8998/sessions/0' requests.delete(session_url, headers=headers)
上面的作业提交的是一段 scala 代码。用户还可以提交 PySpark 作业,SparkR 作业等。不同的作业类型通过提交作业时的字段 kind 来标识,支持的 kind 有:
- spark
- pyspark
- sparkr
- sql
除了 kind 字段,Session 还有其他字段,比如 Session 状态,提交作业时指定 jar,spark 的作业参数等等。详情可参考官方文档。
2.2 Java API
Livy 还基于 rest api 封装了 Java 的客户端。下面是spark3.2.1及以上版本使用例子。
首先导入 livy 的 jar:
<dependency> <groupId>org.apache.livy</groupId> <artifactId>livy-client-http</artifactId> <version>0.8.0-incubating</version> </dependency>在具体使用时,用户需要事先 Livy 定义的 Job 抽象。下面是一个计算 Pi 的例子:
import java.util.*; import org.apache.spark.api.java.*; import org.apache.spark.api.java.function.*; import org.apache.livy.*; public class PiJob implements Job<Double>, Function<Integer, Integer>, Function2<Integer, Integer, Integer> { private final int samples; public PiJob(int samples) { this.samples = samples; } @Override public Double call(JobContext ctx) throws Exception { List<Integer> sampleList = new ArrayList<Integer>(); for (int i = 0; i < samples; i++) { sampleList.add(i + 1); } return 4.0d * ctx.sc().parallelize(sampleList).map(this).reduce(this) / samples; } @Override public Integer call(Integer v1) { double x = Math.random(); double y = Math.random(); return (x*x + y*y < 1) ? 1 : 0; } @Override public Integer call(Integer v1, Integer v2) { return v1 + v2; } }然后提交用 Livy 的 API 提交此作业:
LivyClient client = new LivyClientBuilder() .setURI(new URI(livyUrl)) .build(); try { System.err.printf("Uploading %s to the Spark context...\n", piJar); client.uploadJar(new File(piJar)).get(); System.err.printf("Running PiJob with %d samples...\n", samples); double pi = client.submit(new PiJob(samples)).get(); System.out.println("Pi is roughly: " + pi); } finally { client.stop(true); }
3 重要参数
Livy 中有几个重要参数,如果对其不了解可能会导致不符合预期的行为。
配置名称 | 默认值 | 说明 |
|---|---|---|
livy.server.host | 0.0.0.0 | Livy server 绑定的 IP 地址,默认值为绑定所有网卡 |
livy.server.port | 8998 | Livy server 绑定的 port |
livy.spark.master | local | Spark --master 参数,yarn 环境建议改为 yarn |
livy.spark.deploy-mode | Spark --deploy-mode 参数,yarn 环境建议设置为 cluster | |
livy.server.session.timeout-check | true | 是否对 session 进行过期检查,建议打开 |
livy.server.session.timeout-check.skip-busy | false | 是否跳过对 busy session(也就是有任务运行的 session)的检查。默认值 false,建议设置为 true,否则容易导致正在运行的作业因 timeout 被杀。 |
livy.server.session.timeout | 1h | Session timeout 时间,如果设置过小,那么 session timeout 可能比较频繁。如果设置过大,那么 idle session 可能很多,集群资源白白浪费 |
livy.cache-log.size | 200 | 缓存的 log 大小,单位为 mb |
此外 Livy 还有几个方面的重要参数,包括
- Access control
- Yarn app leakage check
- State recovery
等等,可以参考 livy 的 conf 模板。