E-MapReduce
E-MapReduce



组件与 API 参考

请输入


- 文档首页
 E-MapReduce组件操作指南Spark最佳实践使用 kubectl管理作业
E-MapReduce组件操作指南Spark最佳实践使用 kubectl管理作业

使用 kubectl管理作业
本章节介绍 VKE 场景下,通过 kubectl 来管理 Spark 作业,更多内容请参考:开源官网。
说明
下文中:
app_name:指SparkApplication CR Metadata中的name
app_namespace:指集群namespace,与EMR集群ID相同
app_driver_pod:指Spark 的Driver Pod名称
kubectl
创建 SparkApplication
编写 spark-pi-py.yaml 文件,例如:
apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-pi spec: type: Scala sparkVersion: 3.5.1 mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: "tos://xx/xx/spark-examples_2.12-3.5.1.jar" arguments: - "1000" driver: cores: 1 coreLimit: 1000m memory: 4g executor: cores: 1 coreLimit: 1000m memory: 8g memoryOverhead: 1g instances: 3
通过下述命令创建作业。
kubectl apply -f spark-pi-py.yaml -n ${app_namespace}
查看所有 SparkApplication
kubectl get sparkapp -A

查看指定 SparkApplication 详细信息
kubectl describe sparkapp ${app_name} -n ${app_namespace}
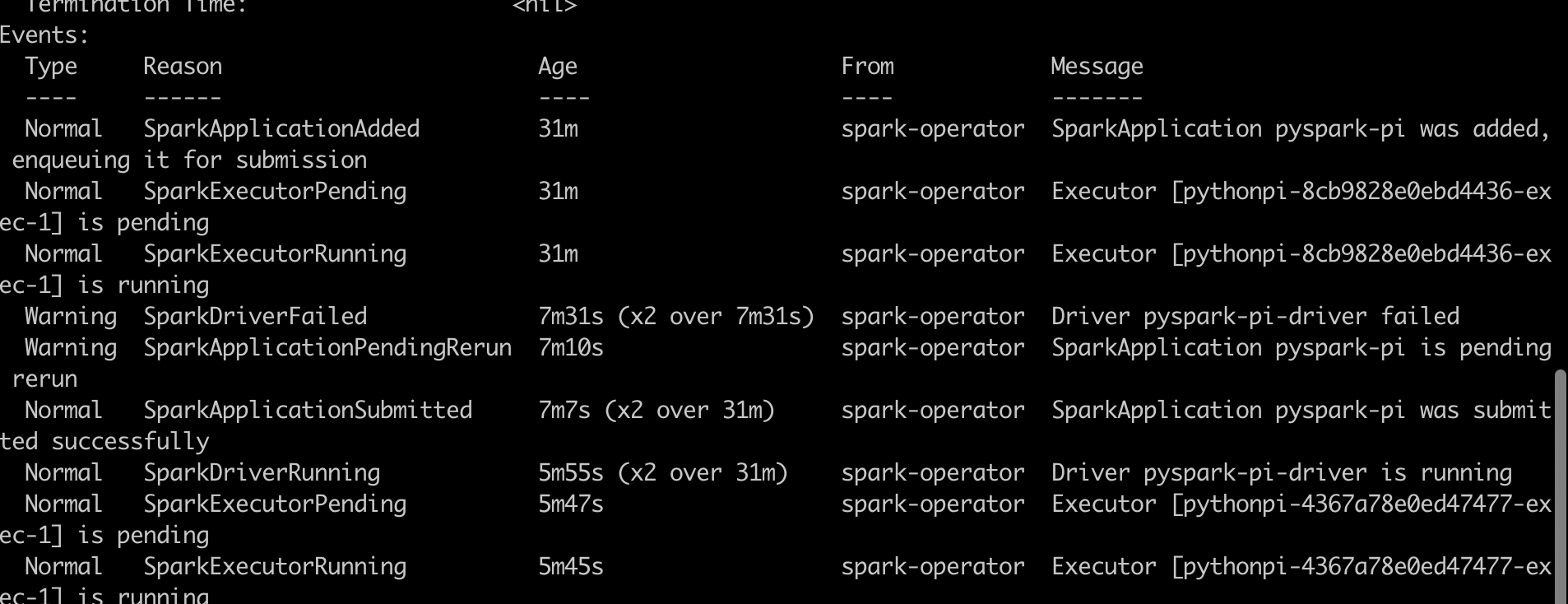
修改 SparkApp 信息
kubectl edit sparkapp ${app_name} -n ${app_namespace}
输入命令后,会进入 vim 编辑模式,修改相应信息后,spark-operator 会根据修改内容,重新提交当前任务。
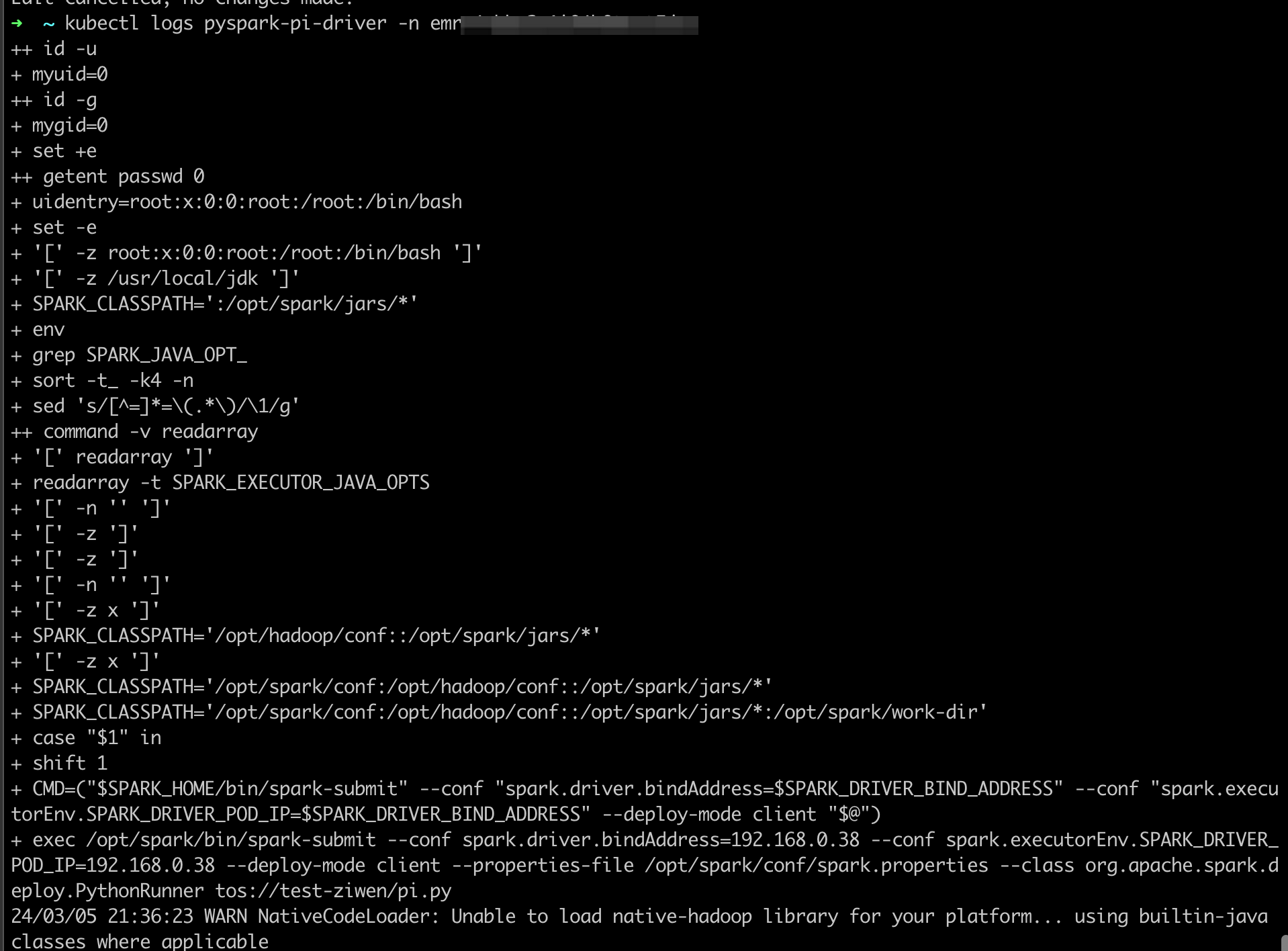
查看日志
kubectl logs ${app_driver_pod} -n ${app_namespace}
删除作业
kubectl delete sparkapp ${app_name} -n ${app_namespace}

最近更新时间:2025.05.14 15:58:56
这个页面对您有帮助吗?
有用
有用
无用
无用