E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南KafkaKafka 概述
E-MapReduce组件操作指南KafkaKafka 概述

1 Kafka 是什么
Kafka 最初由 LinkedIn 公司开发,是一个分布式、支持分区(partition)的、多副本(replica)的,基于 ZooKeeper 协调的分布式消息系统。按照最新的官方定义,Kafka 是分布式流平台。
关于 Kafka 的更多信息,可以参考官网:https://kafka.apache.org/
2 Kafka 的设计目标
| 设计目标 | 描述 |
|---|---|
| 高吞吐量、低延迟 | Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。 |
| 可扩展性 | Kafka 集群支持热扩展。 |
| 持久性、可靠性 | 消息被持久化到本地磁盘,并且支持数据备份,防止数据丢失。 |
| 高并发 | 支持数千个客户端同时读写。 |
| 容错性 | 允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)。 |
3 Kafka 的架构
3.1 Kafka 的专用术语
| 术语名称 | 说明 |
|---|---|
| Broker | Kafka 集群包含一个或多个服务器,负责消息的存储、服务等。这种服务器被称为 broker。 |
| Topic | 每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 topic。不同 topic 的消息分开存储。 |
| Partition | Partition 是物理上的概念。每个 topic 包含一个或多个 partition。 |
| Record | 生产和消费一条消息,或者记录。每条记录包含:一个 key,一个 value,以及一个 timestamp。 |
| Offset | 每个 record 发布到 broker 后,会分配一个 offset。Offset 在单一 partition 中是有序递增的。 |
| Producer | 负责发布消息到 Kafka Broker。 |
| Consumer | 消息消费者,向 Kafka Broker 读取消息的客户端。 |
| Consumer Group | 管理一组 consumer 实例,每个 consumer 属于一个特定的 consumer group。 |
3.2 Kafka 的架构拓扑
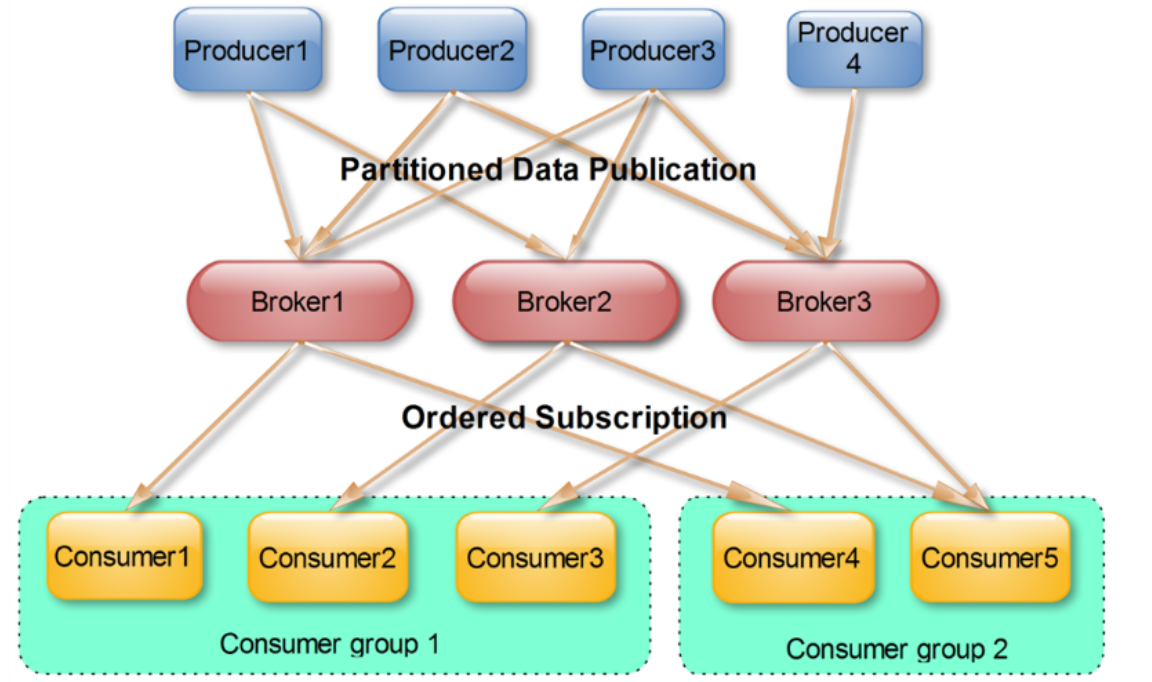
一个典型的 Kafka 集群中包含若干个 producer,若干个 broker,若干个 consumer group。
Kafka 有四种核心 API,最常用的两种为:
Producer API:发布消息到一个或者多个 Kafka 的 topic
Consumer API:订阅一个或者多个 Kafka topic,并对数据进行处理
3.3 Topic 和 Partition
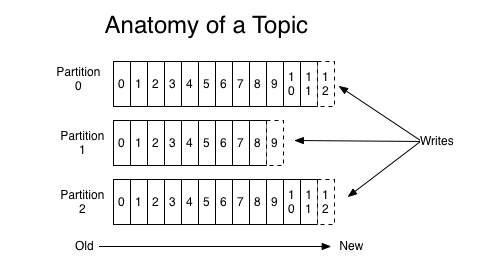
Topic:在逻辑上可以被认为是一个 queue。每条消息都必须指定它的 topic。可以简单理解为必须指明把这条消息放进哪个 queue 里。
Partition:一个 topic 物理上分成一个或多个 partition,每个 partition 在物理机上对应一个文件夹,该文件夹下存储这个 partition 的所有消息和索引文件;如果一个 topic 对应一个文件,那这个文件所在的机器 I/O 将会成为这个 topic 的性能瓶颈。而有了 partition 后,不同的消息可以并行写入不同 broker 的不同 partition 里,极大的提高了并发度和吞吐率。
Offset:每条消息都有一个当前 partition 下唯一的 64 位的 offset。它指明了这条消息的位置。
Partition 数量选择:Partition 数量由两个因素决定:吞吐和并发度,数量过多或过少均会导致相应的问题:
如果 partition 太多:
集群元数据量大,元数据同步慢。在机器重启或者机器故障替换时,切换时间长,影响集群稳定性。数据存储碎片化,随机读写增加。
如果 partition 太少:
并发度小,吞吐小。单 parition 量太大,造成单盘压力大,影响其他 partition,进而影响整个集群的吞吐和延迟。
Patition 数量建议值:
单 partition 高峰期不超过 5M。可以参考使用的管理策略:申请 topic 预留少量 buffer,parition 数量不够了申请扩容,不支持缩容。集群支持 per partition 限速,单 partition 量大会被限速。
3.4 可靠性
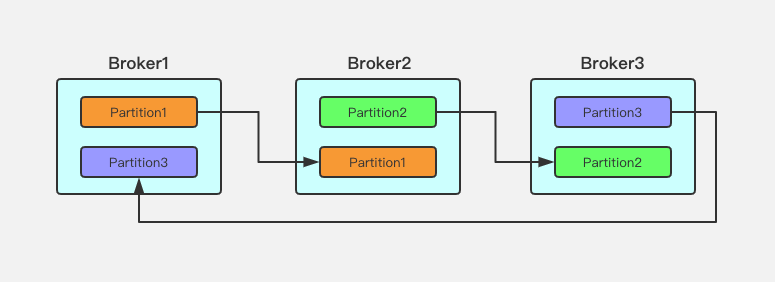
Replication:为了保证数据可靠性,避免单机故障导致数据丢失,每个 parition 可以有多个 replication,分布在不同 broker 上,如上图。例如可以配置 2 副本或 3 副本。
Leader 选举:每个 partition 会在多个 replication 之间选择一个 leader。Client 读写数据都通过 leader partition。其他 replication 为 follower,负责从 leader 同步数据。
数据同步:Kafka 数据同步介于强同步和弱同步之间,通过两个参数控制:min.insync.replica + 发送确认 acks,即 broker 要保持最少 replica 同步,并且保证写入 0 - 1 个或者所有同步 replica 才成功。
举例:
replica = 2,min.insync.replica = 1,acks = 1:至少一个 replica 保持同步,一副本(leader)写入成功,写入确认成功,否则写入失败。
replica = 3,min.insync.replica = 2,acks = all:至少两个 replica 保持同步, 所有 insync.replica 写入成功,写入确认成功,否则写入失败。对于可靠性要求比较高的业务可以考虑使用。需要考虑其中的权衡:高可靠 = 低可用 + 高延迟 + 低吞吐。