E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduceEMR Serverless 实例操作指南(OLAP)数据导入Broker Load
E-MapReduceEMR Serverless 实例操作指南(OLAP)数据导入Broker Load

EMR StarRocks 提供基于 MySQL 协议的 Broker Load 导入方式,帮助您从 HDFS 或外部云存储系统(如TOS)导入大批量数据。
本文为您介绍Broker Load导入的使用示例以及常见问题,本文图片和内容来源于开源StarRocks社区从 HDFS 或外部云存储系统导入数据章节。
1 基本原理
Broker Load 是一种异步的导入方式。您提交导入作业以后,FE 会生成对应的查询计划,并根据目前可用 BE 的个数和源数据文件的大小,将查询计划分配给多个 BE 执行。每个 BE 负责执行一部分导入任务。BE 在执行过程中,会从 HDFS 或云存储系统拉取数据,并且会在对数据进行预处理之后将数据导入到 StarRocks 中。所有 BE 均完成导入后,由 FE 最终判断导入作业是否成功。
您需要通过 SHOW LOAD 语句或者 curl 命令来查看导入作业的结果。
支持CSV、ORCFile和Parquet等文件格式,建议单次导入数据量在几十GB到上百GB级别。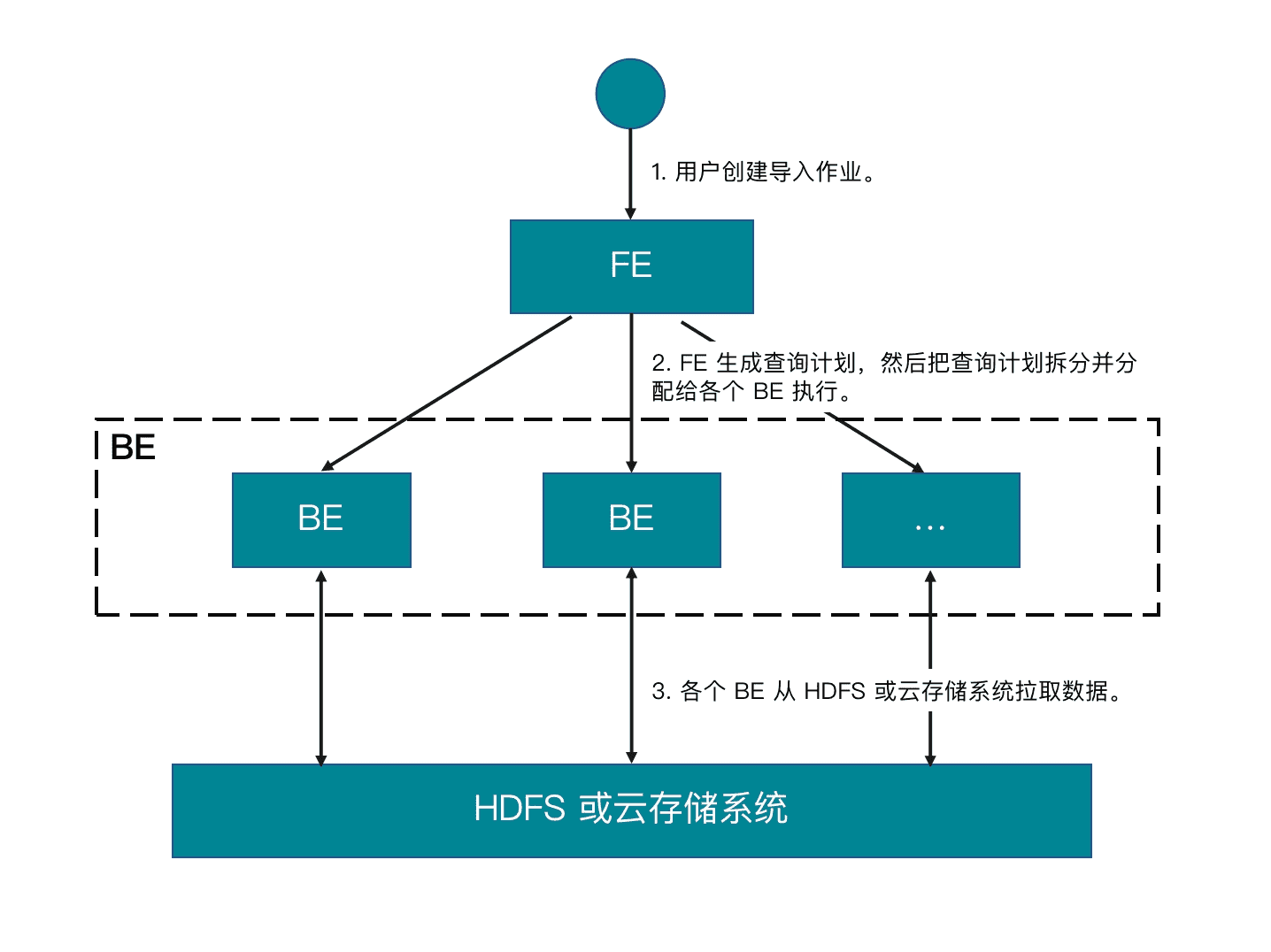
2 基本操作
2.1 查看Broker
EMR StarRocks集群在创建时已经自动搭建并启动Broker服务,Broker服务位于每个Core节点上。使用以下SQL命令可以查看Broker。
SHOW PROC "/brokers"\G
2.2 创建导入任务
2.2.1 语法
LOAD LABEL [<database_name>.]<label_name> ( data_desc[, data_desc ...] ) WITH BROKER (StorageCredentialParams) [PROPERTIES (opt_properties)]
参数说明如下:也参考StarRocks社区的BROKER LOAD。
参数 | 描述 |
|---|---|
database_name | 非必填,指定目标表所在的数据库。 |
label_name | 指定导入作业的标签。每个导入作业都对应唯一的一个标签。通过标签,可以查看导入作业的执行情况。导入作业的状态为 FINISHED 时,其标签不可再复用给其他导入作业。导入作业的状态为 CANCELLED 时,其标签可以复用给其他导入作业。有关标签的命名规范,请参见系统限制。 |
data_desc | 用于描述一批次待导入的数据,格式如下
参数说明请参数StarRocks社区官网data_desc的介绍。 |
StorageCredentialParams | StarRocks 访问存储系统的认证配置。请参考StarRocks社区storagecredentialparams。 |
2.2.2 查看导入作业
Broker Load 支持通过 SHOW LOAD 语句和 curl 命令两种方式来查看导入作业的执行情况。
- 使用 SHOW LOAD 语句
执行SHOW LOAD 查看数据库中指定导入作业的相关信息,语法如下:
SHOW LOAD [ FROM db_name ] [ WHERE [ LABEL { = "label_name" | LIKE "label_matcher" } ] [ [AND] STATE = { "PENDING" | "ETL" | "LOADING" | "FINISHED" | "CANCELLED" } ] ] [ ORDER BY field_name [ ASC | DESC ] ] [ LIMIT { [offset, ] limit | limit OFFSET offset } ]
示例,查看test_db数据库下的导入任务状态:
MySQL [test_db]> SHOW LOAD \G; *********************** 1. row *************************** JobId: 10244 Label: label1 State: FINISHED Progress: ETL:100%; LOAD:100% Type: BROKER Priority: NORMAL EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=5 TaskInfo: resource:N/A; timeout(s):3600; max_filter_ratio:0.0 ErrorMsg: NULL CreateTime: 2023-09-23 12:44:38 EtlStartTime: 2023-09-23 12:44:43 EtlFinishTime: 2023-09-23 12:44:43 LoadStartTime: 2023-09-23 12:44:43 LoadFinishTime: 2023-09-23 12:44:45 URL: NULL JobDetails: {"All backends":{"467eaa1a-03c0-4012-a320-bd310bc32d8a":[10002],"5f6e6eae-ebc8-4577-afd2-8e5a742434d0":[10004]},"FileNumber":2,"FileSize":55,"InternalTableLoadBytes":181,"InternalTableLoadRows":5,"ScanBytes":55,"ScanRows":5,"TaskNumber":2,"Unfinished backends":{"467eaa1a-03c0-4012-a320-bd310bc32d8a":[],"5f6e6eae-ebc8-4577-afd2-8e5a742434d0":[]}} 1 row in set (0.004 sec)
返回参数的描述参考StarRocks社区官网SHOW LOAD 。其中Type: BROKER表明该Load属于BROKER Load。
说明
- 导入作业相关信息具有时效性,默认是作业完成时间后的3天。您可以通过FE 参数
label_keep_max_second修改默认有效时间(单位:秒)。 - 若导入作业的
LoadStartTime长时间为N/A,说明导入作业堆积严重,可降低作业创建的频率。 - 导入作业所消耗的总时长 =
LoadFinishTime-CreateTime。 LOAD阶段所消耗的时长 =LoadFinishTime-LoadStartTime。
- 使用 curl 命令
curl --location-trusted -u <username>:<password> \ 'http://<fe_host>:<fe_http_port>/api/<database_name>/_load_info?label=<label_name>'
2.2.3 取消导入任务
当Broker Load作业状态不为CANCELLED或FINISHED时,可以执行CANCEL LOAD命令进行手动取消。取消时需要指定待取消导入任务的Label。
语法:
CANCEL LOAD [FROM db_name] WHERE LABEL = "label_name"
2.3 相关配置项
一个 Broker Load 作业会拆分成一个或者多个子任务并行处理,一个作业的所有子任务作为一个事务整体成功或失败。作业的拆分通过 LOAD LABEL 语句中的 data_desc 参数来指定:
- 如果声明多个
data_desc参数对应导入多张不同的表,则每张表数据的导入会拆分成一个子任务。 - 如果声明多个
data_desc参数对应导入同一张表的不同分区,则每个分区数据的导入会拆分成一个子任务。
每个子任务还会拆分成一个或者多个实例,然后这些实例会均匀地被分配到 BE 上并行执行。实例的拆分由以下FE配置决定:
参数 | 描述 |
|---|---|
min_bytes_per_broker_scanner | 单个实例处理的最小数据量,默认为 64 MB |
load_parallel_instance_num | 单个 BE 上每个作业允许的并发实例数,默认为 1 个。 |
max_broker_load_job_concurrency | 指定了 StarRocks 集群中可以并行执行的 Broker Load 作业的最大数量。默认值是5。 |
通常情况下,一个作业只有一个DataDescription,只会拆分成一个任务。任务会拆成与BE数相等的实例,然后分配到所有BE上并行执行
3 导入示例
3.1 从 HDFS 导入
本示例以“创建多表导入 (Multi-Table Load) 作业”进行介绍,数据格式采用CSV,介绍如何导入多个数据文件至多张目标表。有关如何导入其他格式的数据、以及 Broker Load 的详细语法和参数说明,请参见 BROKER LOAD。
在HDFS集群中运行
创建一个名为
file1.csv的数据文件,测试数据如下:1,Lily,23 2,Rose,23 3,Alice,24 4,Julia,25创建一个名为
file2.csv的数据文件,测试数据如下200,'北京'在HDFS集群中将上述的CSV数据上传到HDFS中
hdfs dfs -mkdir -p /user/hive/data/ hdfs dfs -put file1.csv /user/hive/data/ hdfs dfs -put file2.csv /user/hive/data/
在EMR StarRocks集群创建 StarRocks目标数据库和表
- 创建一张名为
table1的主键模型表。表包含id、name和score三列
CREATE DATABASE IF NOT EXISTS test_db; USE test_db; CREATE TABLE `table1` ( `id` int(11) NOT NULL COMMENT "用户 ID", `name` varchar(65533) NULL DEFAULT "" COMMENT "用户姓名", `score` int(11) NOT NULL DEFAULT "0" COMMENT "用户得分" ) ENGINE=OLAP PRIMARY KEY(`id`) DISTRIBUTED BY HASH(`id`);- 创建一张名为
table2的主键模型表。表包含id和city两列
CREATE TABLE `table2` ( `id` int(11) NOT NULL COMMENT "城市 ID", `city` varchar(65533) NULL DEFAULT "" COMMENT "城市名称" ) ENGINE=OLAP PRIMARY KEY(`id`) DISTRIBUTED BY HASH(`id`);- 创建一张名为
在StarRocks集群执行导入作业SQL操作
LOAD LABEL test_db.label1 ( DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/hive/data/file1.csv") INTO TABLE table1 COLUMNS TERMINATED BY "," (id, name, score) , DATA INFILE("hdfs://<hdfs_host>:<hdfs_port>/user/hive/data/file2.csv") INTO TABLE table2 COLUMNS TERMINATED BY "," (id, city) ) WITH BROKER ( StorageCredentialParams ) PROPERTIES ( "timeout" = "3600" );
说明
StorageCredentialParams 代表一组认证参数,需要根据您所使用的认证方式来确定参赛内容,详情请参见 BROKER LOAD。
- 查看导入任务
SHOW LOAD \G;
或采用Curl命令:
curl --location-trusted -u <username>:<password> \ 'http://<fe_host>:8030/api/test_db/_load_info?label=label1'
返回信息如下:
{"jobInfo":{"dbName":"test_db","tblNames":["table2","table1"],"label":"label1","state":"FINISHED","failMsg":"","trackingUrl":"\\N"},"status":"OK","msg":"Success"}
- 查看表中的数据
SELECT * FROM table1; SELECT * FROM table2;
3.2 从 火山云TOS中 导入
您还可以指定导入一个数据文件或者一个路径下所有数据文件到一张目标表。这里假设您的 TOS 存储空间 bucket_s3 里 input 文件夹下包含多个数据文件,其中一个数据文件名为 file1.csv。这些数据文件与目标表 table1 包含的列数相同、并且这些列能按顺序一一对应到目标表 table1 中的列。
- 将上述中的
file1.csv上传到TOS中 - 将TOS文件
file1.csv导入到table1表中
TRUNCATE TABLE test_db.table1; LOAD LABEL tos.table1 ( DATA INFILE("s3a://emr-autotest/doris/s3_load.csv") INTO TABLE table1 COLUMNS TERMINATED BY "," (id, name, score) ) WITH BROKER ( "aws.s3.enable_ssl" = "false", "aws.s3.endpoint" = "{S3 Endpoint}.ivolces.com" "aws.s3.secret_key" = "{secret key}" "aws.s3.access_key" = "{access key}" ) PROPERTIES ( "timeout" = "36000" );
- 查看导入作业状态
curl --location-trusted -u <username>:<password> \ 'http://<fe_host>:8030/api/test_db/_load_info?label=lable_3'