E-MapReduce
E-MapReduce






- 文档首页
 E-MapReduce组件操作指南StarRocks概述
E-MapReduce组件操作指南StarRocks概述

StarRocks 是新一代极速全场景的 MPP (Massively Parallel Processing) 数据库,其愿景是能够让用户的数据分析变得更加简单和敏捷。借助 StarRocks,您可以不用对数据进行任何复杂的预处理操作,即可通过 MySQL 协议连接操作 StarRocks 集群,实现对数据的多场景极速分析,典型的分析场景包括在线业务实时报表与分析、用户画像与行为分析、数据湖查询分析,以及日志管理与分析等。
说明
本章节部分内容和图片引用自 StarRocks 官网。
产品特性
MPP 分布式执行框架
StarRocks 采用 MPP (Massively Parallel Processing) 分布式执行框架。在 MPP 执行框架中,一条查询请求会被拆分成多个物理计算单元在多机上并行执行。每个执行节点拥有独享的资源(CPU、内存)。MPP 执行框架能够使得单个查询请求可以充分利用所有执行节点的资源,所以单个查询的性能可以随着集群的水平扩展而不断提升。
全面向量化执行引擎
StarRocks 通过实现全面向量化引擎,充分发挥了 CPU 的处理能力。全面向量化引擎按照列式的方式组织和处理数据。StarRocks 的数据存储、内存中数据的组织方式,以及 SQL 算子的计算方式都是列式实现的。按列的数据组织也可以更加充分的利用 CPU 的 Cache 特性,按列计算会有更少的虚函数调用,以及更少的分支判断,从而获得更加充分的 CPU 指令流水。
另一方面,StarRocks 的全面向量化引擎通过向量化算法充分的利用 CPU 提供的 SIMD(Single Instruction Multiple Data)指令。这样 StarRocks 可以用更少的指令数目,完成更多的数据操作。经过标准测试集的验证,StarRocks 的全面向量化引擎可以将执行算子的性能,整体提升 3~10 倍。
存储计算分离
StarRocks 存算分离技术在现有存算一体架构的基础上,将计算和存储进行解耦。在存算分离新架构中,数据持久化存储在更为可靠和廉价的远程对象存储(比如 S3)或 HDFS 上,计算节点本地磁盘只用于缓存热数据来加速查询。在本地缓存命中的情况下,存算分离可以获得与存算一体架构相同的查询性能。存算分离架构下,用户可以动态增删计算节点,实现秒级的扩缩容。存算分离大大降低了数据存储成本和扩容成本,有助于实现资源隔离和计算资源的弹性伸缩。
CBO 优化器
StarRocks 从零设计并实现了一款全新的、Cascades Like、基于代价的优化器 CBO(Cost Based Optimizer)。在设计时,该优化器针对 StarRocks 的全面向量化执行引擎进行了深度定制,并进行了多项优化和创新。该优化器内部实现了公共表达式复用、相关子查询重写、Lateral Join、Join Reorder、Join 分布式执行策略选择,以及低基数字典优化等多项重要功能和优化。目前,该优化器已可以完整支持 TPC-DS 99 条 SQL 语句。
可实时更新的列式存储引擎
StarRocks 实现了列式存储引擎,数据以按列的方式进行存储,实现相同类型的数据连续存放。一方面,数据可以使用更加高效的编码方式,获得更高的压缩比,降低存储成本。另一方面,也降低了系统读取数据的 I/O 总量,提升了查询性能。此外,在大部分 OLAP 场景中,查询只会涉及部分列。相对于行存,列存只需要读取部分列的数据,能够极大地降低磁盘 I/O 吞吐。
智能的物化视图
StarRocks 支持用户使用物化视图(Materialized View)进行查询加速和数仓分层。不同于一些同类产品的物化视图需要手动和原表做数据同步,StarRocks 的物化视图可以自动根据原始表更新数据。只要原始表数据发生变更,物化视图的更新也同步完成,不需要额外的维护操作就可以保证物化视图能够维持与基表一致。不仅如此,物化视图的选择也是自动进行的。StarRocks 在进行查询规划时,如果有合适的物化视图能够加速查询,StarRocks 自动进行查询改写(Query Rewrite),将查询自动定位到最适合的物化视图上进行查询加速。
数据湖分析
StarRocks 不仅能高效的分析本地存储的数据,也可以作为计算引擎直接分析数据湖中的数据。用户可以通过 StarRocks 提供的 External Catalog,轻松查询存储在 Hive、Iceberg、Hudi、Delta Lake 等数据湖上的数据,无需进行数据迁移。
系统架构
StarRocks 支持存算一体(shared-nothing)和存算分离(shared-data)两种部署模式。
存算一体
在存算一体模式下,StarRocks 集群由 FE 和 BE 两类节点组成,整体架构如下图所示:
说明
- FE:即 Frontend,是 StarRocks 的前端接入节点,负责管理元数据、管理客户端连接、进行查询规划,以及查询调度等工作。每个 FE 节点都会在内存保留一份完整的元数据,从而提供无差别的服务。
- BE:即 Backend,是 StarRocks 的数据存储和计算节点,负责数据存储和 SQL 计算等工作。在功能上,BE 节点是对等的,并且支持横向的扩缩容以灵活调整集群的存储和计算能力。
存算分离
在存算分离模式下,StarRocks 集群由 FE 和 CN 两类节点组成,整体架构如下图所示: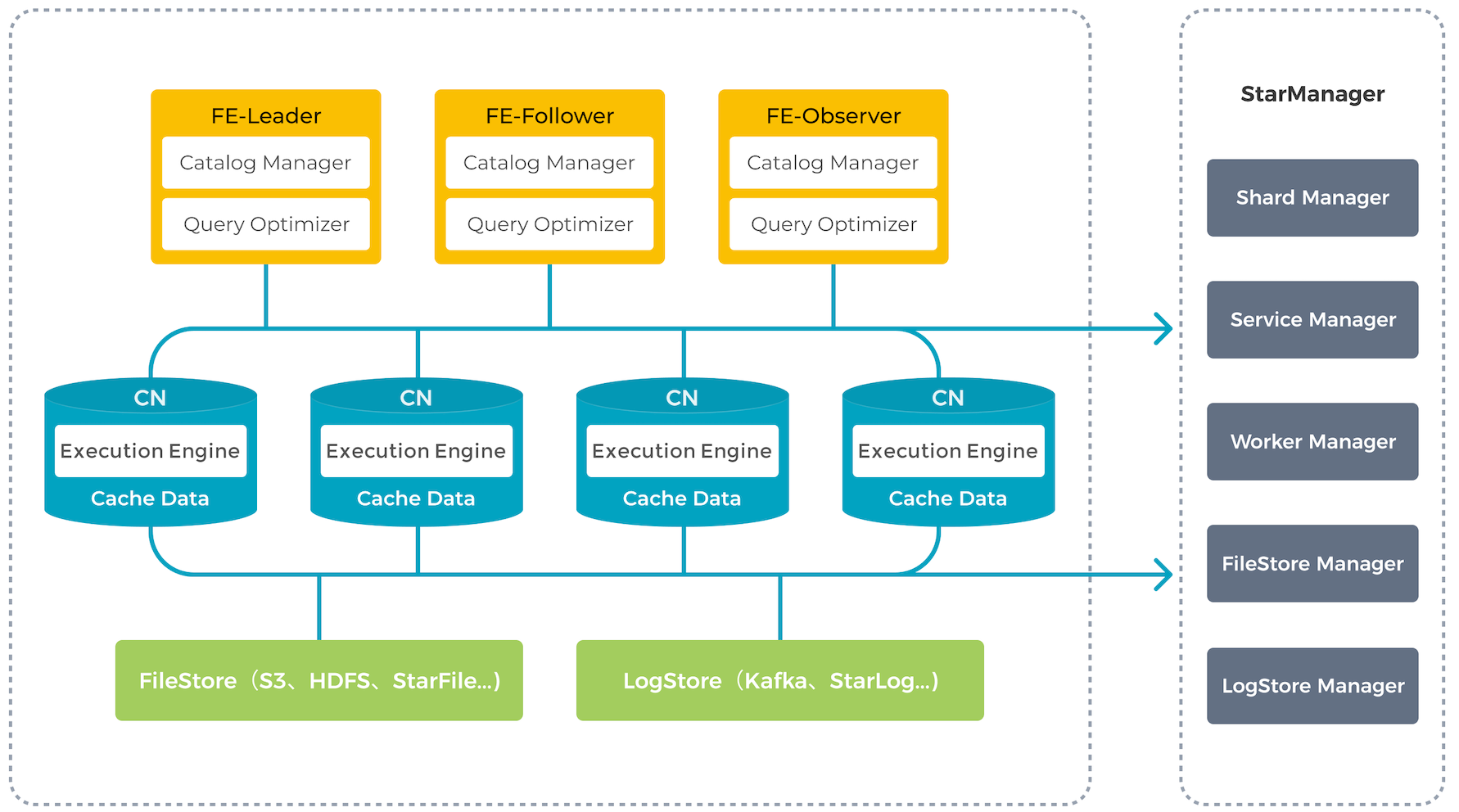
说明
- FE:即 Frontend,是 StarRocks 的前端接入节点,在功能上与存算一体架构保持一致,同样负责管理元数据、管理客户端连接、进行查询规划,以及查询调度等工作。
- CN:即 Compute Node,是 StarRocks 的计算节点。在存算分离模式下,数据存储从本地存储升级为共享存储,因此 BE 节点的存储功能被抽离,蜕化成为无状态的 CN 节点,负责执行数据导入、查询计算、缓存数据管理等任务。
使用指导文档
- 如果您使用的是全托管的 EMR 形态,您可以参考 EMR Serverless 实例最佳实践文档进行 Starrocks 的深度使用,详情请参见:EMR Serverless 实例-Starrocks 最佳实践文档。
说明
推荐您使用 EMR Serverless 实例来使用 Starrocks,免运维、更省心。
- 如果您使用的是半托管的 EMR 形态,您可以参考本目录下的文档,继续深入访问以下 StarRocks 相关章节:
- 如果您希望了解关于 StarRocks 更多详细信息,可以参考 StarRocks 官方文档。