客户数据平台
客户数据平台



文档指南

请输入


- 文档首页
 客户数据平台用户指南数据集成与整合数据连接常见数据源接入流式数据Kafka数据接入
客户数据平台用户指南数据集成与整合数据连接常见数据源接入流式数据Kafka数据接入

Kafka数据接入
1. 产品概述
Kafka Topic数据能够支持产品实时场景,以下将介绍如何将火山Kafka数据接入CDP。
2. 使用限制
用户需具备 项目编辑 或 权限-按内容管理-模块-数据连接-新建连接 权限,才能新建数据连接。
3. 操作步骤
1.点击 数据管理 > 数据连接 。
2.在数据连接目录左上角,点击 新建数据连接 按钮,在跳转的页面选择 Kafka 。
3. 填写所需的基本信息,并进行 测试连接 。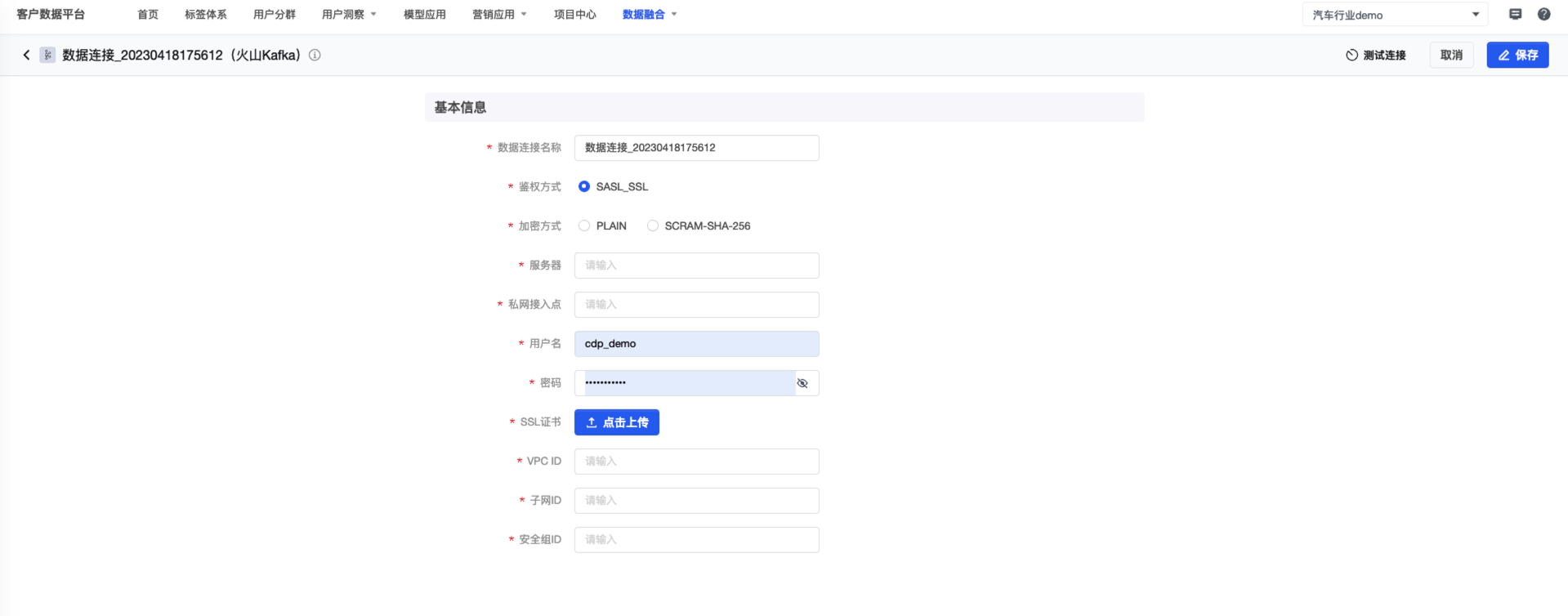
- 连接成功后点击 保存 即可。
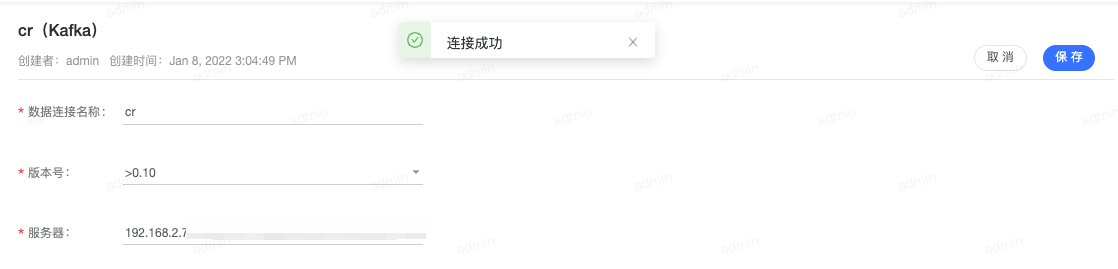
- 点击 数据融合>元数据管理 。
- 点击右上角 新建数据源 ,创建实时数据源时,选择对应用户的kafka连接及Topic;
- 选择所需Topic后,有两种方式设置Topic中msg到数据源类型(ClickHouse类型)的映射:
- 1)采用当前Topic内的msg
- 2)自定义msg的json结构
配置支持嵌套json,需使用jsonpath提取。 示例:outter.inner.cnt表示获取{"outter": {"inner": {"cnt": 0}}}中的0。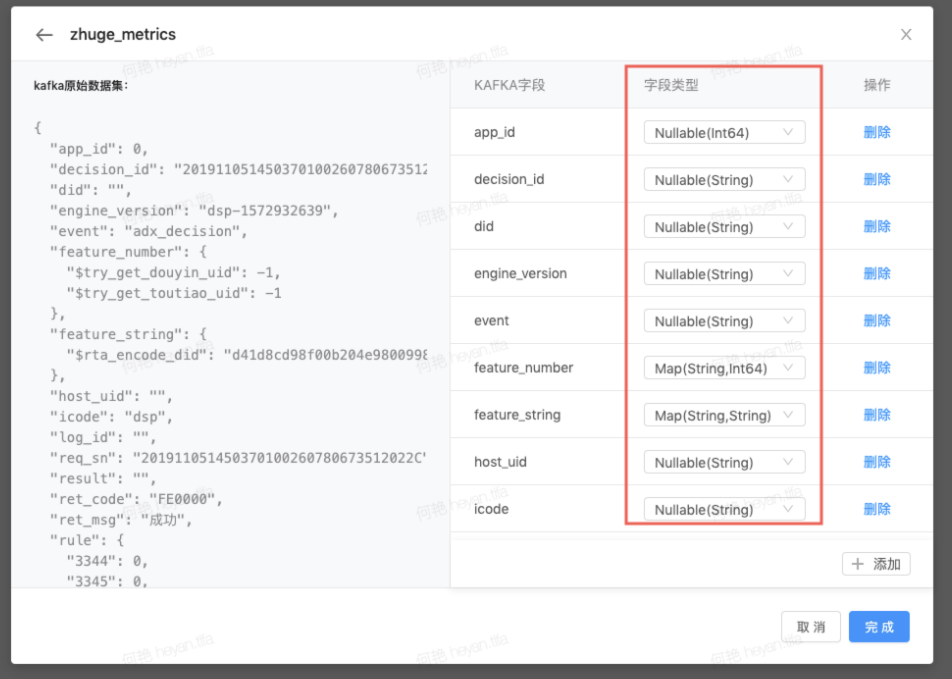
return (<Alertmessage="注意"description="不支持下划线开头的字段名称,不支持字段中包含`-`字符。"type="info"showIcon></Alert> ) js
分区键需要能被toDate/toDateTime。仅支持使用int类型的时间戳(支持秒/毫秒级),或者'2020-01-01'/'2020-01-01 00:00:00'格式的字符串。
推荐使用int类型时间戳。如果使用json建表,json中分区键的值也应遵守上面的规则。
分区键设置示例:
①int类型时间戳,字段类型选择Int64。
②string类型日期'2020-01-01',字段类型选择Date。
③string类型日期'2020-01-01 00:00:00',字段类型选择DateTime。
return (<Alertmessage="注意"description="不支持聚合后落表,不支持覆盖历史数据。"type="info"showIcon></Alert> ) js
嵌套字段提取:
当存在多层嵌套时,可输入json path提取字段。
示例:
{ "body": { "cost": { "city": "Shanghai", "country": "China" } } }
若需要提取字段city,则json.path为body.cost.city
return (<Alertmessage="注意"description="json.path不支持修改,也不支持原本没有定义json.path的字段改为有定义json.path。如果需要修改此类字段,需要先删除,然后保存数据集,待修改完成后再次编辑,添加所需同名字段。如果添加字段与原来定义字段名称不同,则可以在一次编辑内完成操作。"type="info"showIcon></Alert> ) js
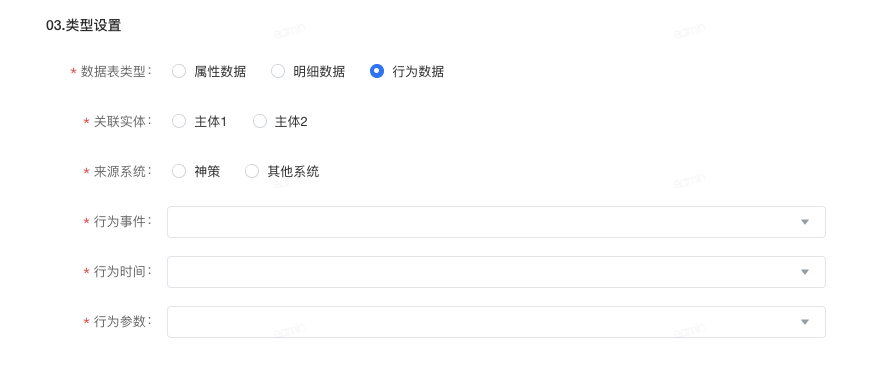
- 点击 应用此表 ,进行类型设置。
说明
若该数据集有baseid,可以选择baseid(基准ID)的类型,则直接使用该表(即用户的数据本身就是标准的baseid);若无,则可以选择对应的类型,系统自动创建对应的idmapping映射可视化建模任务,进行ID-Mapping。
注意
- 当前实时类型仅支持明细/行为类型数据源,属性类型不支持实时。
- 无下游使用的Kafka数据连接支持修改或删除,修改或删除后会影响相关标签/群体/可视化建模等任务;有下游使用时,不支持kafka数据连接的修改及删除。
- 完成配置后,点击 保存 即可。
最近更新时间:2024.11.28 10:41:12
这个页面对您有帮助吗?
有用
有用
无用
无用