客户数据平台
客户数据平台






- 文档首页
 客户数据平台用户指南数据集成与整合可视化建模数据输出输出到数据集
客户数据平台用户指南数据集成与整合可视化建模数据输出输出到数据集

数据输出,是指您在创建可视化建模任务的过程中的数据输出与保存的环节。在完成数据输入-数据处理之后,需要对任务结果以数据集的形式保存,以便后续进行可视化查询与展现等。
- 输出类算子共包含3类:输出、输出标签、分流输出、外部输出。
本文将为您介绍第一种常规输出算子,即将数据输出到数据集,支持输出到hive/clickhouse引擎。
用户需要完成 数据处理 才能输出数据集。
3.1 离线任务输出
在可视化建模的编辑界面,点击算子的添加按钮,在输出类型中,点击选择第一个“输出”。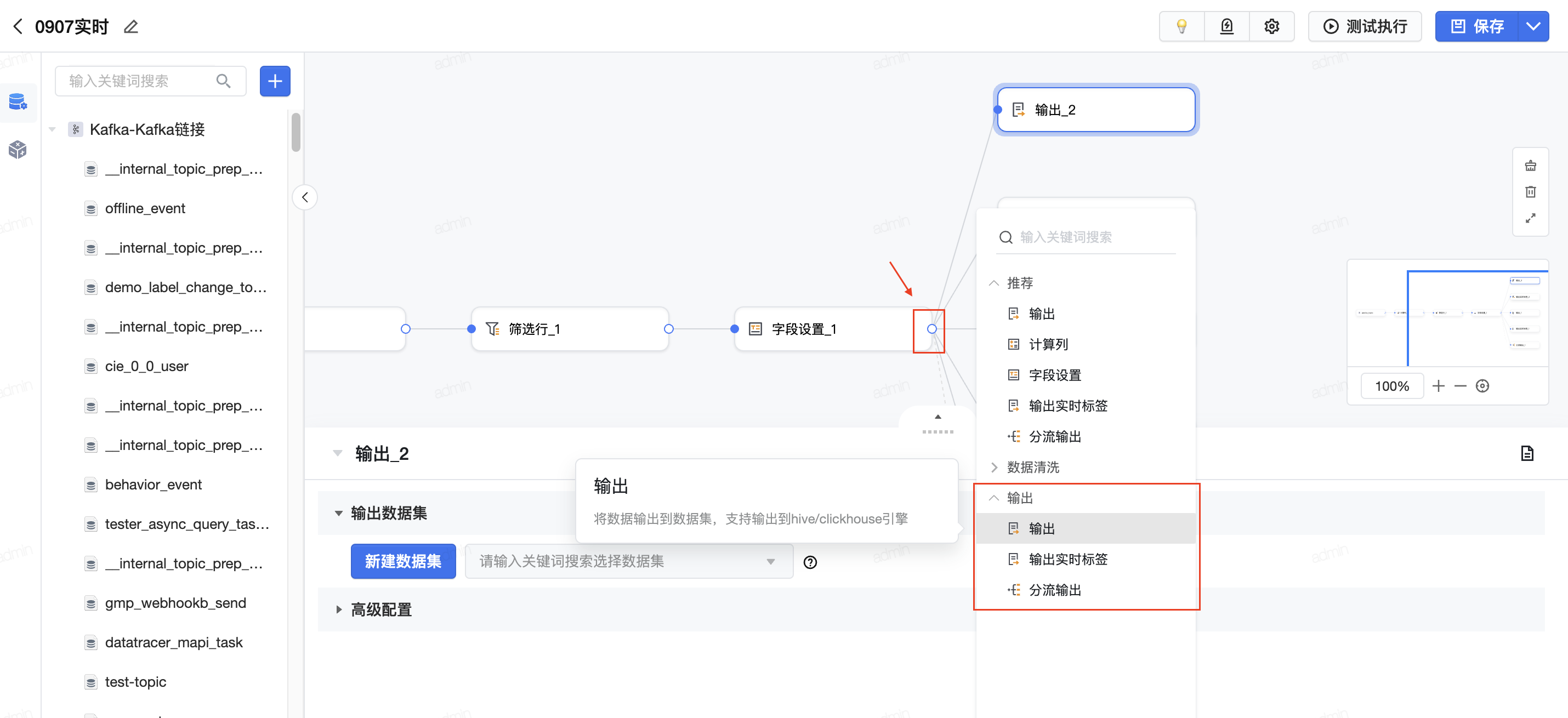
对于已经做好各个节点处理的建模任务,可以在任务界面下方的“输出数据集”板块,点击新建数据集或写入已有数据集内。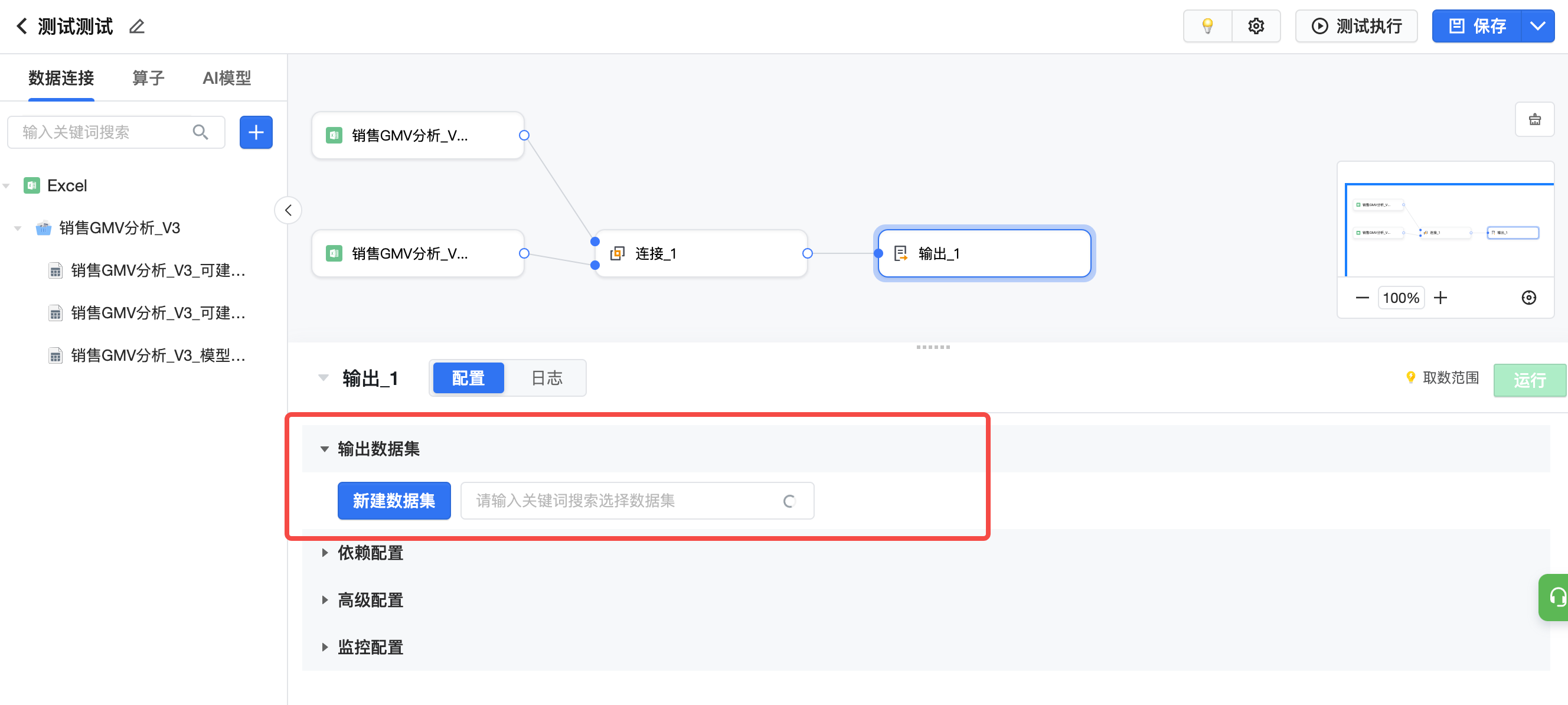
- 新建数据集需填写数据集名称、数据集描述。
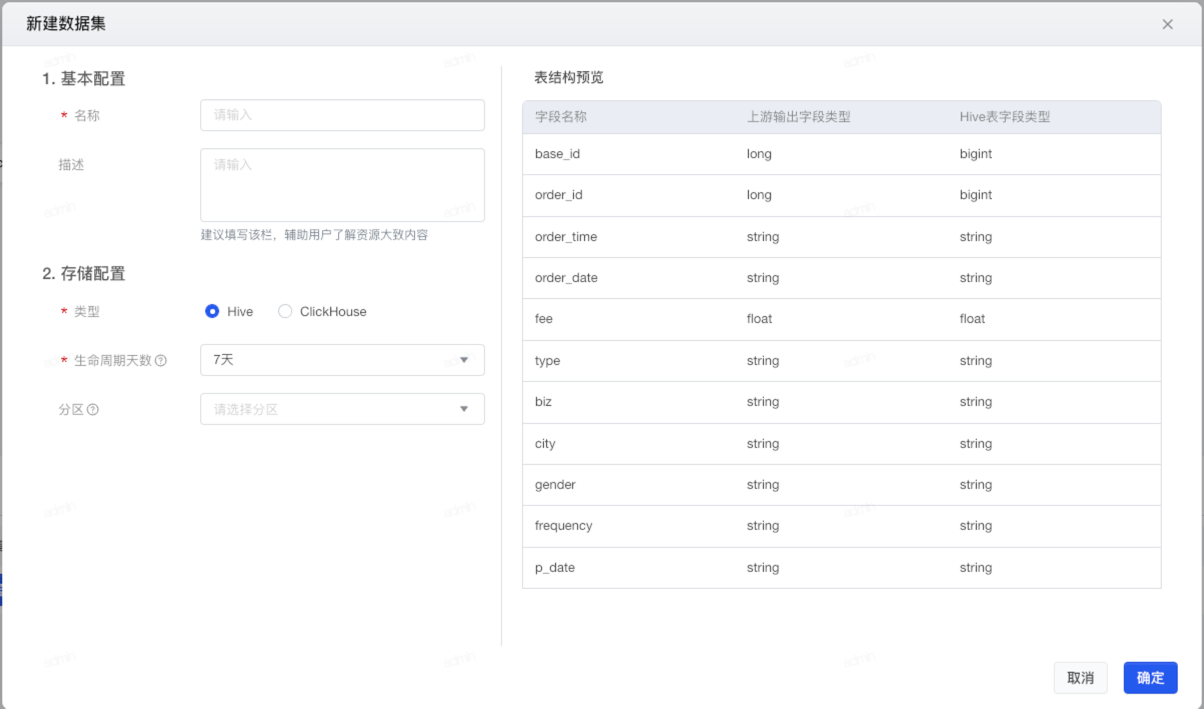
- 数据数据库选择:系统支持Hive、Clickhouse两类存储方式,用户可按需选择;
- Hive:需要选择 生命周期天数(必选) 与 分区(可选)
- 生命周期天数:数据的有效保存天数,如选择7天,则根据数据更新时间最多保存7天的数据,超出7天的数据将根据数据更新时间定时滑动清空。建议:如每天保存全部数据,建议保留7天以内数据以降低存储压力,如每天保存新增的数据或非分区表,建议根据常用数据范围自定义生命周期。可选1天/7天/30天/365天/永久。
- 生命周期天数:数据的有效保存天数,如选择7天,则根据数据更新时间最多保存7天的数据,超出7天的数据将根据数据更新时间定时滑动清空。建议:如每天保存全部数据,建议保留7天以内数据以降低存储压力,如每天保存新增的数据或非分区表,建议根据常用数据范围自定义生命周期。可选1天/7天/30天/365天/永久。
- Clickhouse:选择集群、排序键、分片字段、抽样字段、生命周期天数和分区。
- 集群: 选择数据集存储的集群。
- 排序键: 将最常用作过滤条件的字段设置为排序键,可以使查询会更快。可以设置多个字段为排序键,第1个字段作用最大,其余依次递减,建议不超过3个。不能使用分区字段作为排序键。
- 分片字段: 用于确保数据均分分布在各个存储节点上。若每天数据量不超过2000w行,请保留系统默认设置。只能设置一个字段为分片字段,可以选择最常用作维度的字段(该字段枚举值超过100个才需要设置),或者最常用作去重计数指标的字段(该字段枚举值超过1w个才需要设置,如user_id、device_id、item_id等)。
- 抽样字段: 在可视化查询模块中可按此字段抽样进行查询,只支持int,float,string类型的字段。
- 生命周期天数: 数据的有效保存天数,如选择7天,则根据数据更新时间最多保存7天的数据,超出7天的数据将根据数据更新时间定时滑动清空。建议:如每天保存全部数据,建议保留7天以内数据以降低存储压力,如每天保存新增的数据或非分区表,建议根据常用数据范围自定义生命周期。可选1天/7天/30天/365天。
数据生命周期支持生命周期的高级配置。允许用户自定义数据保留规则,如"保留最近XX天"和"XX天至XX天,保留每${周期}的${特定日子}"。
*示例:40至50天内,每月最后一天的数据保留。
该功能由产品开关控制,默认关闭,如有需要可联系您的客户经理。
- Hive:需要选择 生命周期天数(必选) 与 分区(可选)
* *注意:添加条件上限为两层* * **分区:** 可选日期或其他取值可枚举的字段作为分区,一级分区必须为date类型,若无合适字段,可以选择“系统默认分区”(对天、周、 月级别例行同步任务的取值为任务例行执行的前一天,对小时、分钟级别例行同步任务取值为任务例行执行当天, 对手动运行的任务的取值为运行时选择的业务时间)
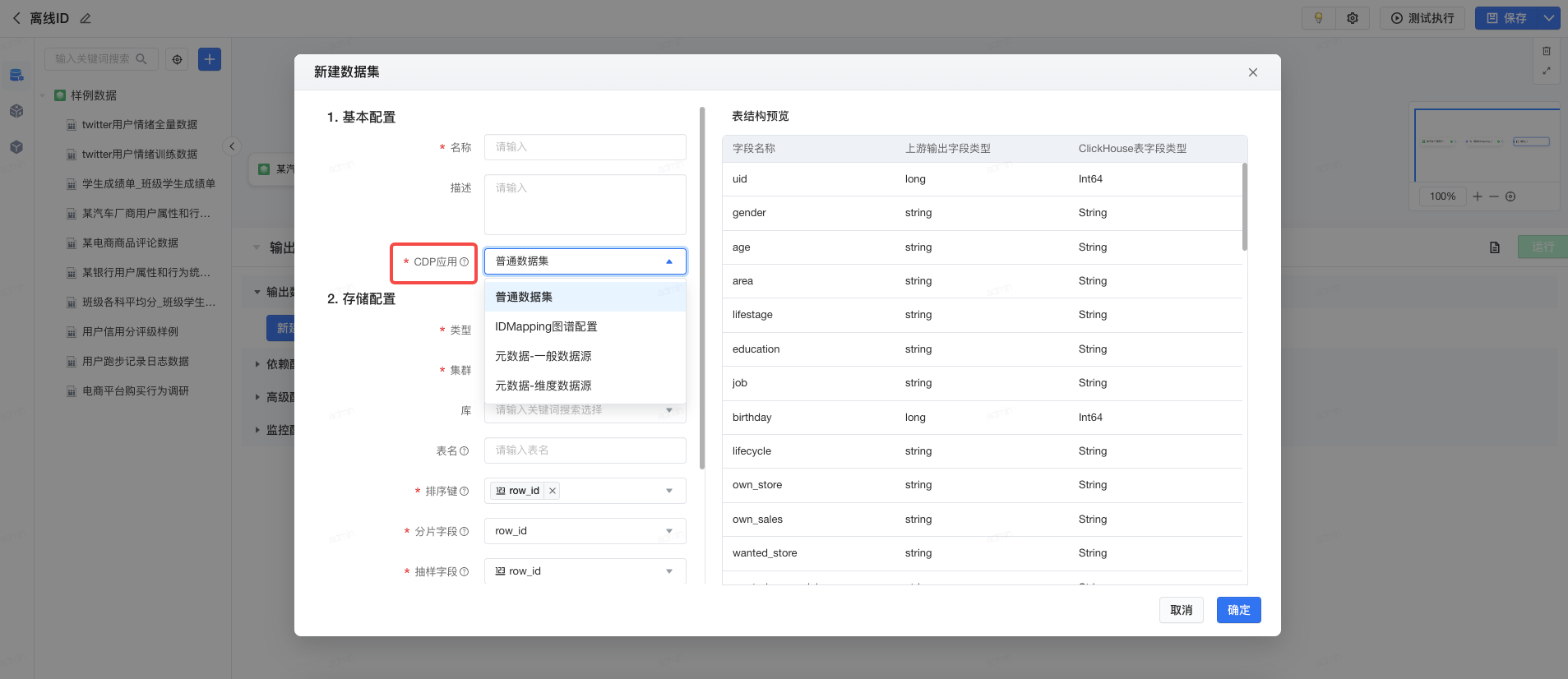
支持CDP应用打标,在输出数据集的同时定义数据集的应用场景,基于不同场景可以自动匹配不同的存储逻辑,自动约束格式,避免重复抽取数据。
说明
由于CDP下游部分应用存在特殊查询逻辑,需要选择合适的应用场景:
- 普通数据集:不做特殊限定,可作为数据源在可视化建模内重复参与生产加工,但是无法注册数据档案或配置IDM。
- IDMapping图谱配置:用于配置IDMapping图谱,仅支持输出Hive数据集,且一般要求每天分区存储全量数据。
- 数据档案-主体属性档案:用于注册主体属性的数据档案,该类数据集需必填主体基准OneID字段,且系统会自动根据OneID字段进行去重,保证属性值唯一,可提前在画布流程中添加IDM算子转换生成基准ID(OneID)字段,一般要求每天存储全量数据。
- 数据档案-业务明细/行为事件档案:用于注册明细/行为数据档案,该类数据集需必填主体基准OneID字段,且系统会自动将OneID字段作为分片键存储且不可变更,可提前在画布流程中添加IDM算子转换生成基准ID(OneID)字段,一般要求每天分区存储增量数据。
- 数据档案-业务维度档案:用于注册业务维度数据档案,该类数据集需必填维度主键字段,且系统会将每个分片节点(服务器)存储全量数据并对主键字段进行去重,不可直接用于CDP其他任何模块,一般要求每天分区存储全量数据。
在离线可视化建模任务中,当上游表结构发生改动时,支持用户更新实时数据集表结构。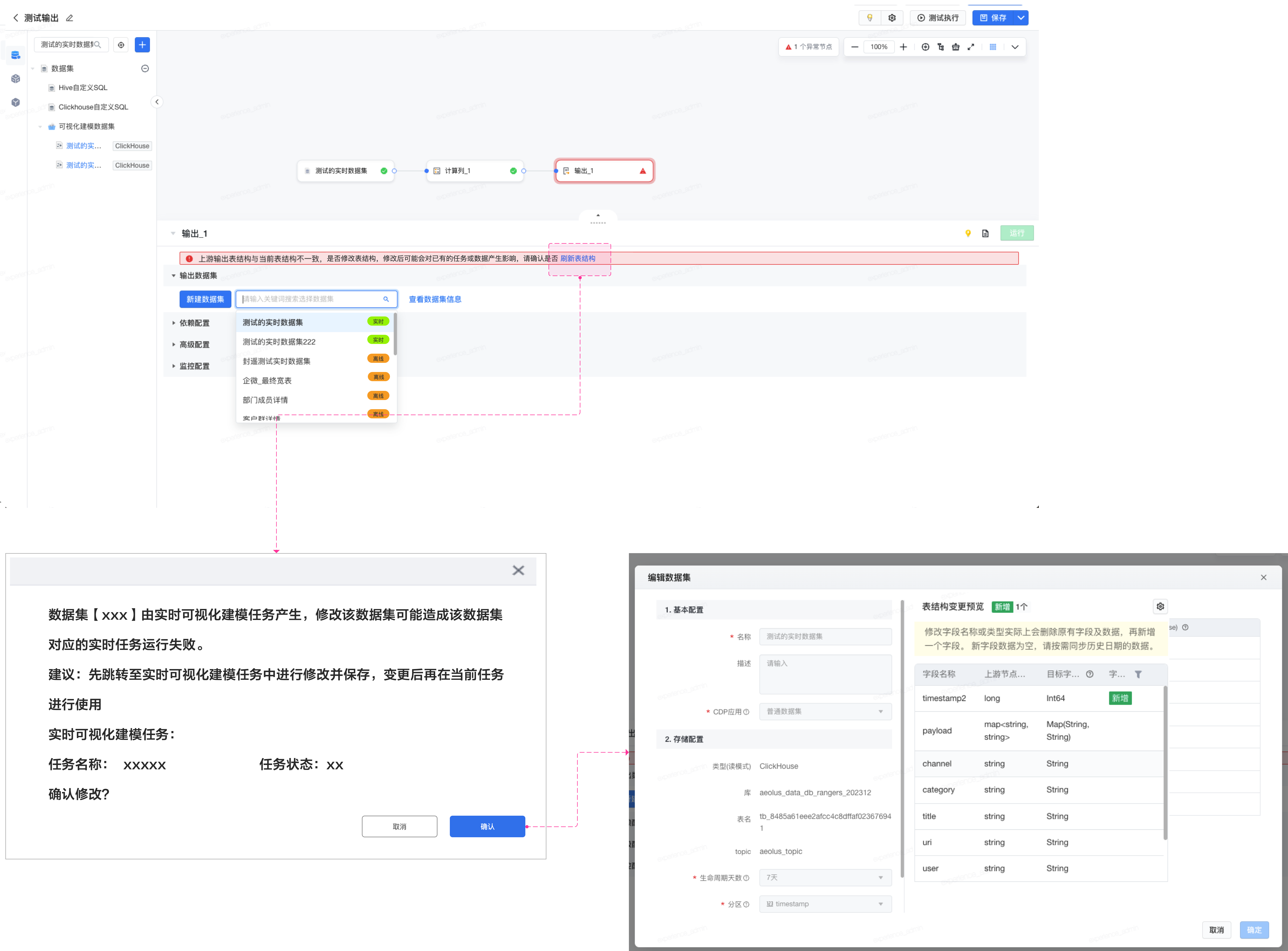
3.1.1 依赖配置
数据源依赖 通过依赖配置,可结合上游数据的就绪状态,判断并开启定时同步任务。在【依赖配置】中,对于Hive和Clickhouse数据源,系统可自动获取上游配置的依赖信息,进行展示。如需修改或自定义配置依赖关系,可选择自定义配置。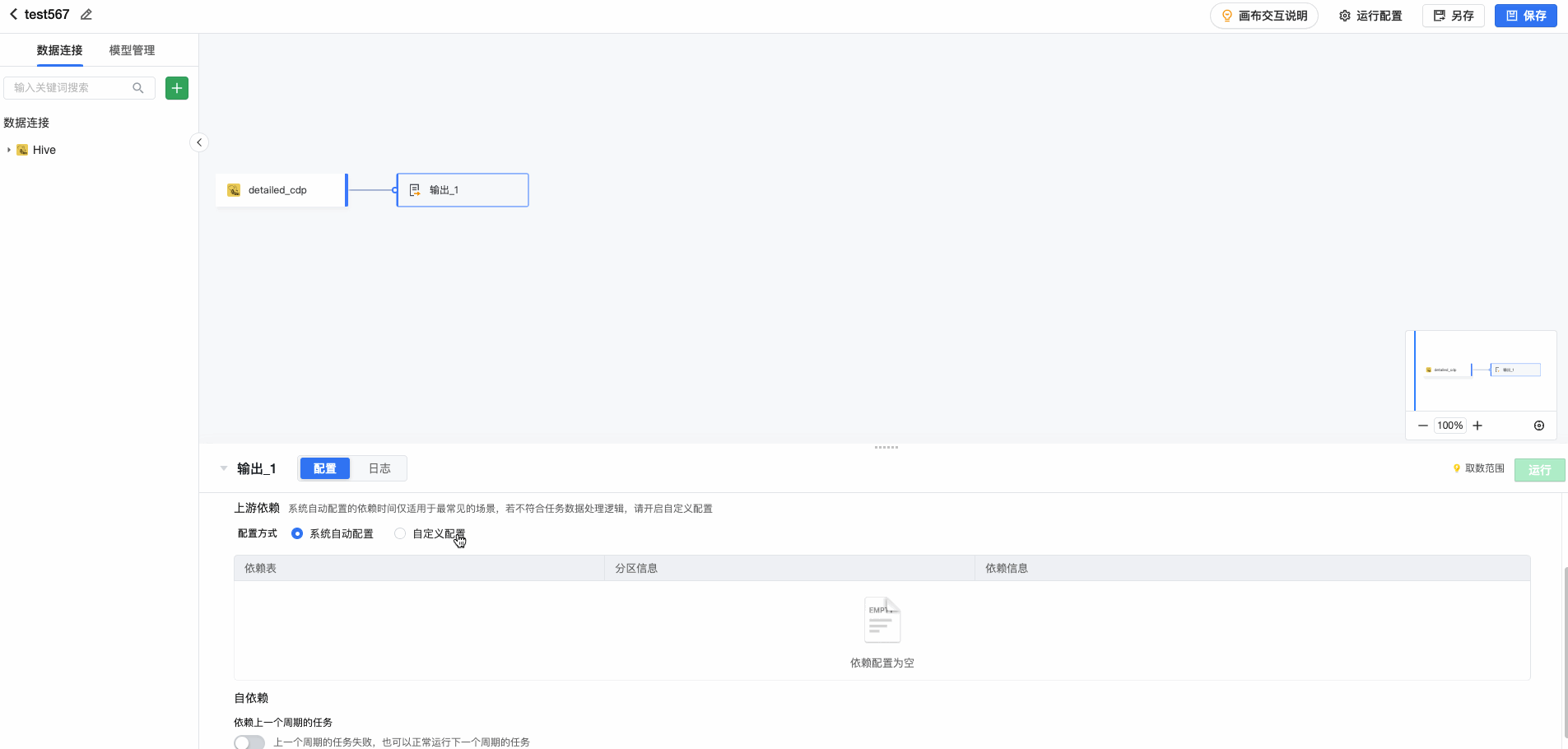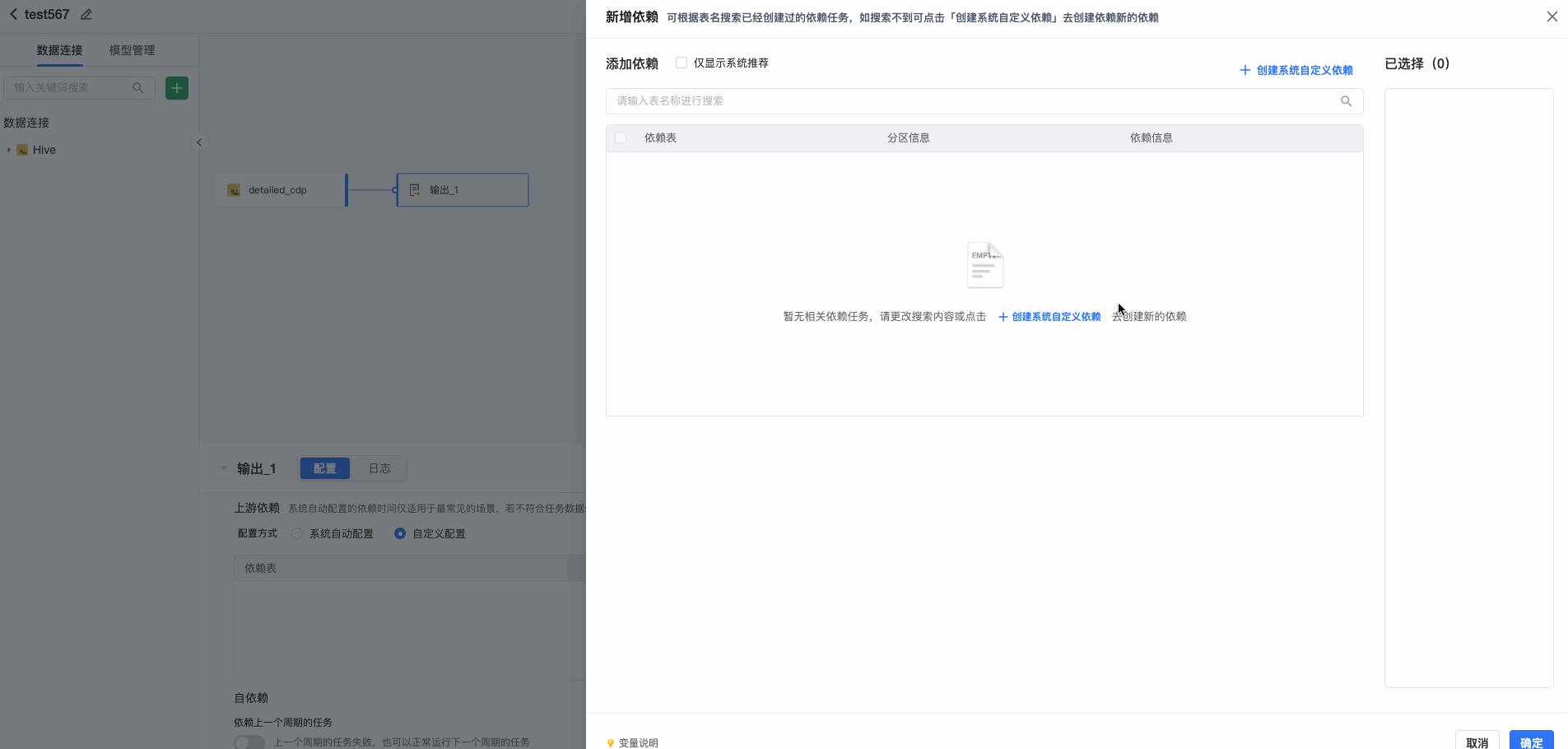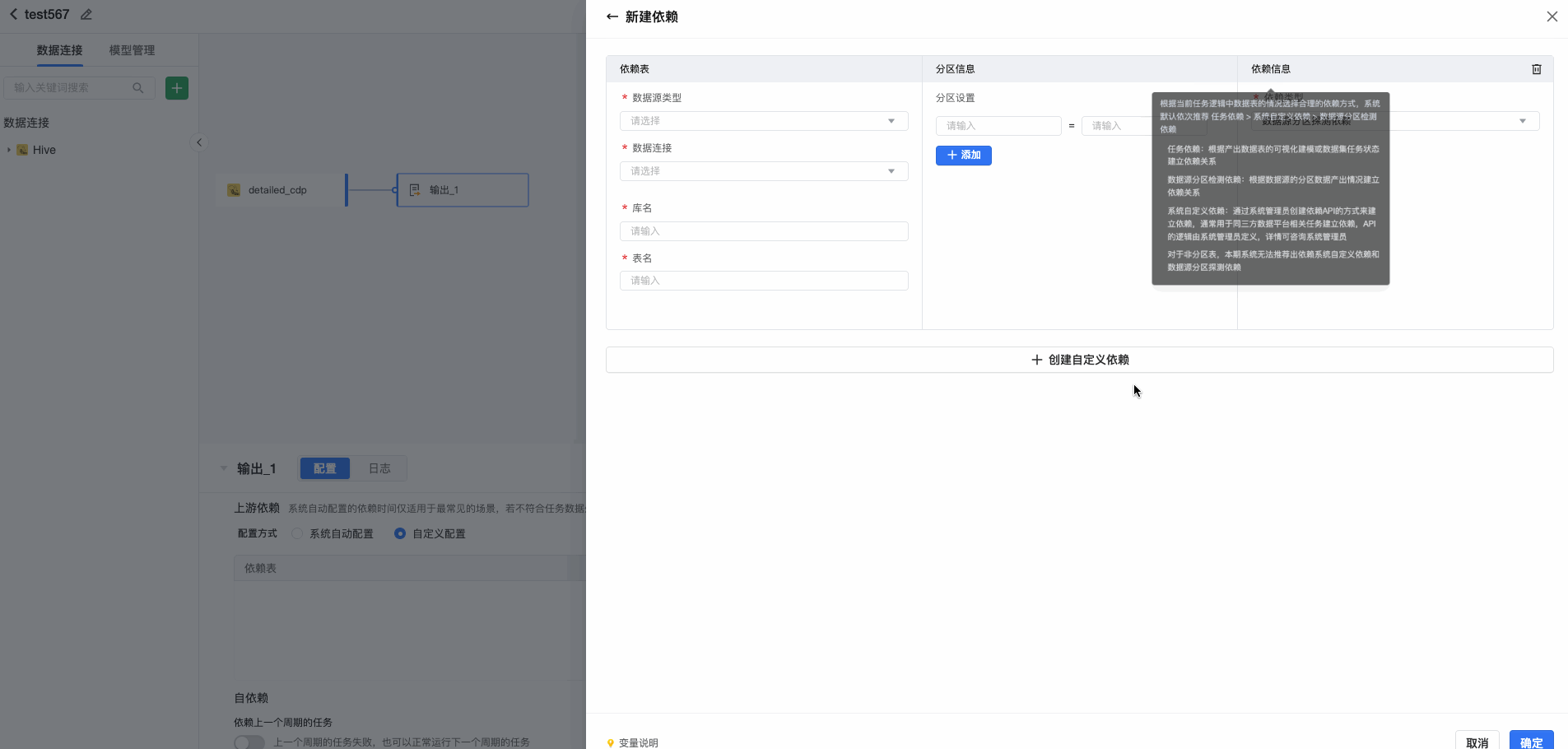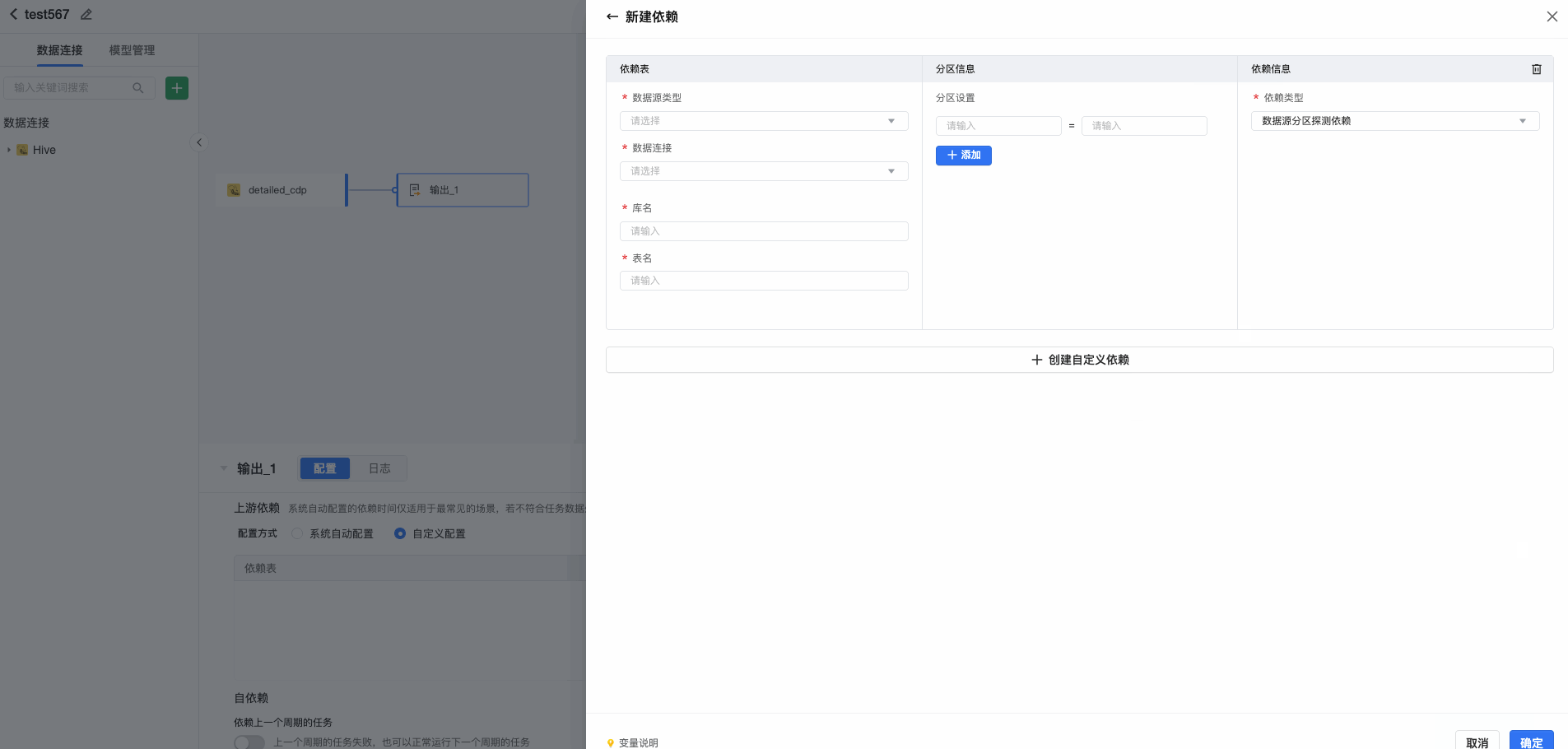
支持对常见数据源(Hive JDBC、Maxcompute)进行检测依赖。填写依赖表、分区信息及依赖类型。可以根据当前任务逻辑中数据表的情况选择合理的依赖方式,系统默认依次推荐【任务依赖 > 系统自定义依赖 > 数据源分区检测依赖】:
- 任务依赖:根据产出数据表的可视化建模或数据集任务状态建立依赖关系
- 数据源分区检测依赖:根据数据源的分区数据产出情况建立依赖关系
- 系统自定义依赖:通过系统管理员创建依赖API的方式来建立依赖,通常用于同三方数据平台相关任务建立依赖,API的逻辑由系统管理员定义,详情可咨询系统管理员
注意
对于非分区表,系统暂时无法推荐出依赖系统自定义依赖和数据源分区探测依赖。
三方平台数据同步任务依赖
支持通过建立HTTP API的方式实现对三方平台任务执行状态的依赖关系。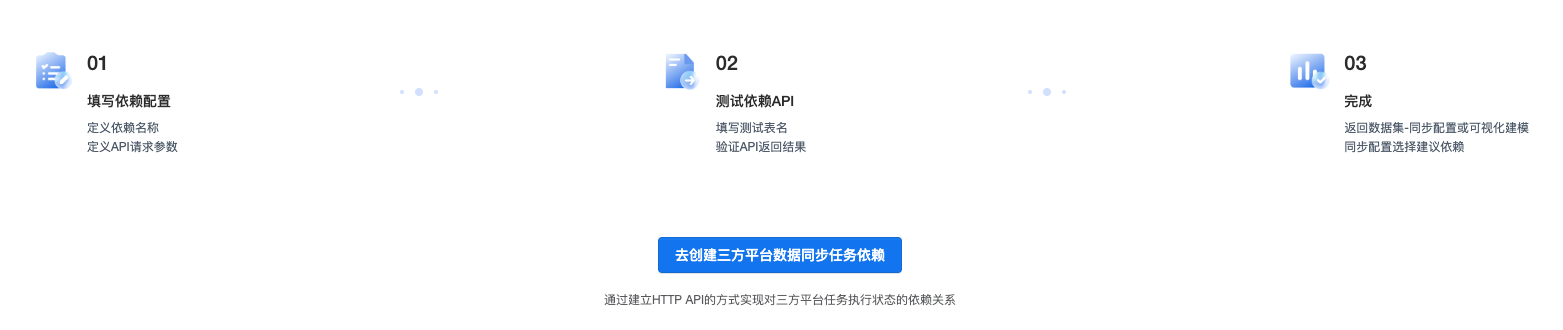
1)API配置
- 请求方法:GET
- 样例URL:https://restapi.amap.com/v3/weather/weatherInfo
- Params中的参数会自动拼接到自定义URL中
2)请求参数说明: Params中的Key和Value会自动拼接到自定义URL中,其中Key的名称可以自定义,Value参数格式不变,系统根据参数内容自动传入特定任务参数,可根据需要选择使用
3)系统参数Params
${dataSourceType} 数据源类型,如hive-jdbc、maxcomputer ${dbName} 任务中数据源的库名称 ${tableName} 任务中数据源的表名称 ${taskTime} 业务日期,即具体任务执行的日期,通常情况业务业务日期与分区日期保持一致 ${partition} 任务中数据源的分区值
4)自定义参数
如上述系统参数无法定位到具体的调度信息,可定义一个可被第三方平台识别的参数信息。新增的自定义参数信息将在任务配置里新增一个必填参数组件,请合理定义名称便于理解。
5)接口成功返回结构
API接口调用成功,请定义成功返回的结构:JSON结构返回{"status":"success"}或{'status":0}
3.1.2 高级配置
HIVE数据源的数据集需选择运行队列和队列中的运行优先级。选择队列,对应的HIVE查询将在指定队列上执行后再导入数据集。队列选择会影响数据集同步时长,但不影响可视化查询效果。
运行参数: 支持根据需求设置数据集同步的运行参数,以保障同步成功或同步性能等。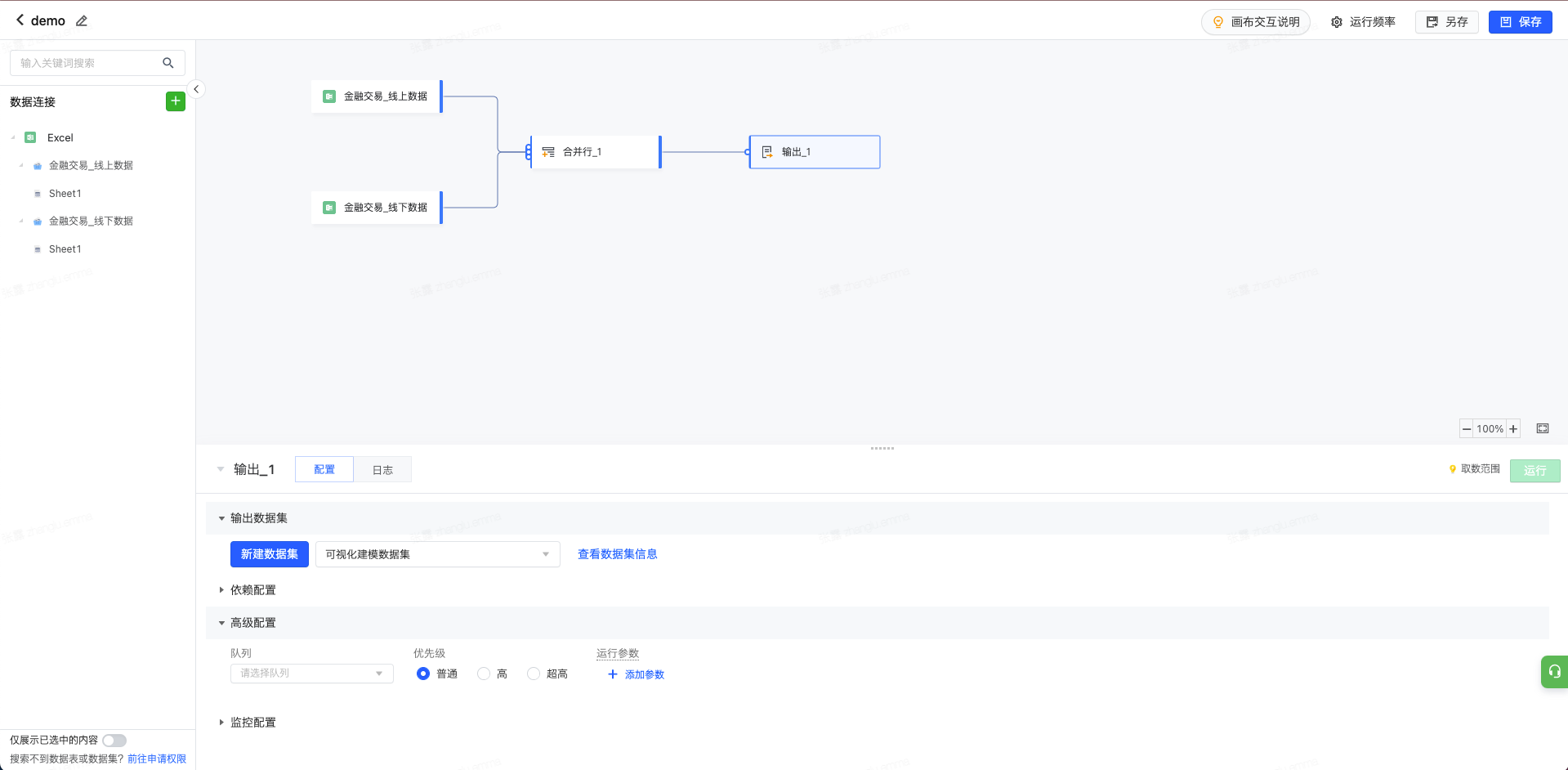
3.1.3 监控配置
前置要求: 通知方式需要先完成 办公软件集成 进行前置配置,之后才可设置。
报警条件: 支持添加监控报警,在数据集同步异常时及时通知相应用户,可配置多条报警规则。系统提供三类报警条件
- 失败报警:数据集同步失败则会触发消息通知
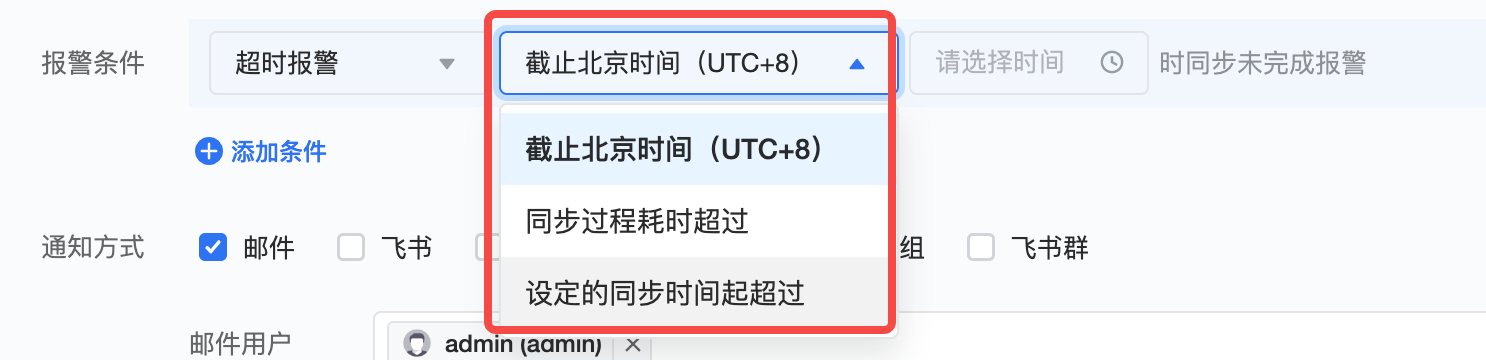
- 超时报警:支持选择三类超时定义
- 截止北京时间告警:指系统在指定的北京时间(UTC+8)到达某个预设时间点时触发告警。
- 同步过程耗时告警:指从任务启动开始计算,如果任务执行时间超过预设的时长阈值,则触发告警。
- 设定的同步时间起超过告警:指从任务预定的执行时间开始计算,如果实际执行时间比预定时间晚,且超出了设定的时间阈值,则触发告警。
- 结果异常报警:监控数据行数,当行数异常时报警。常用于以下场景:
- 防止同步异常或上游数据异常,导致同步无数据:可设置数据行数=0时报警
- 上游数据会多次更新,防止同步数据不全:可设置数据行数<预期行数时报警;如预期数据集每天同步 10w 行数据,若<80000 就可能数据不全,则可设置数据行数<80000 行时报警
通知方式:支持邮件、飞书、WebEx、钉钉、企业微信、邮件组、飞书群报警。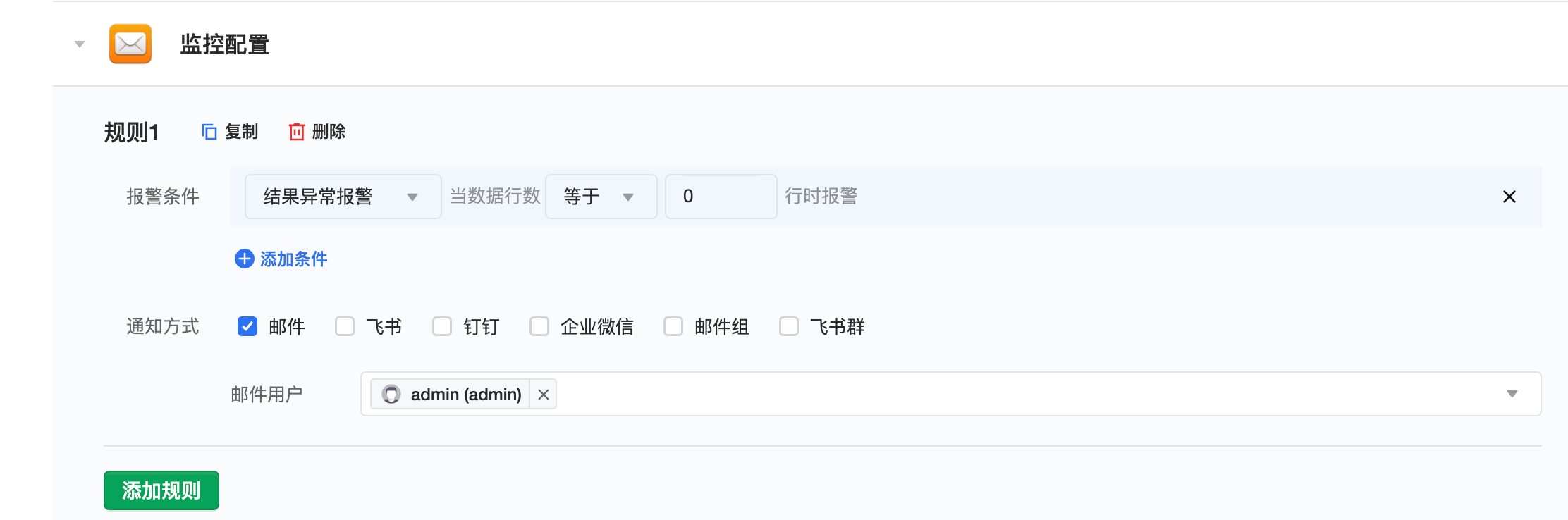
3.2 实时任务输出
实时任务仅支持输出为clickhouse类型。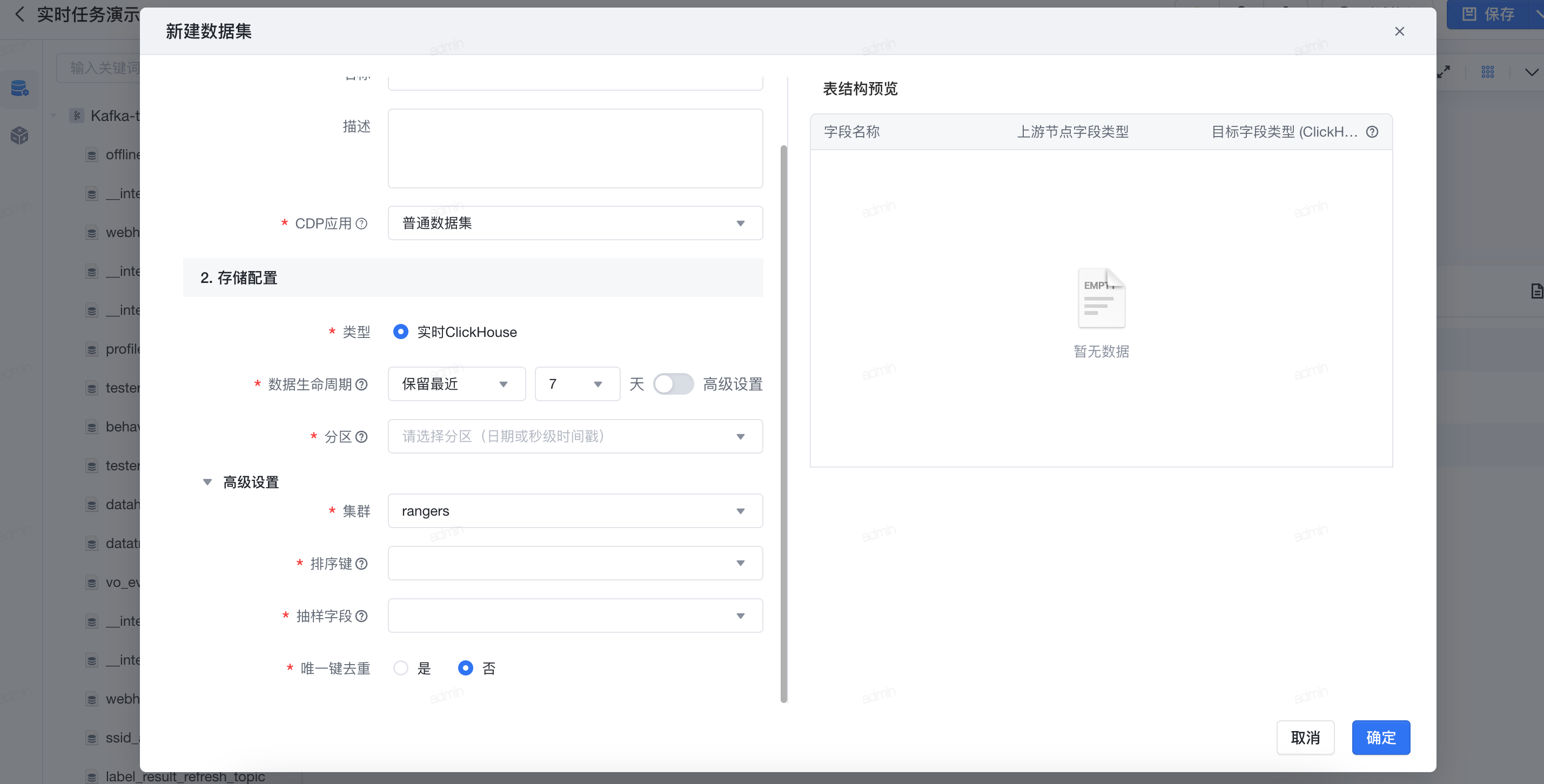
支持配置数据生命周期, 即抽取至系统存储中数据的有效保留天数,非分区表根据数据更新时间保留数据,日期分区则根据分区日期保留数据,生命周期外的数据每天0点会自动清除。
数据生命周期的高级设置: 即在保留天数的基础上,可以对历史数据选择性的保留。
- 示例1:如选择最近7天,则保留最近7天的数据,超出7天的数据将根据数据更新时间定时滑动清空
- 示例2:(高级功能):如选择最近7天 + 超出时保留每月最后一天的数据,则除了最近7天数据外,历史数据里每月的最后一天数据也会保留下来
注意
季度为自然季度(如1-3月为一季度)
建议:
保留周期越久占用的系统存储资源越多,请根据需要选择合理的生命周期范围
- 排序键: 将最常用作过滤条件的字段设置为排序键,可以使查询会更快。可以设置多个字段为排序键,第1个字段作用最大,其余依次递减,建议不超过3个。
- 抽样字段: 将最常用作过滤条件的字段设置为排序键,可以使查询会更快。可以设置多个字段为排序键,第1个字段作用最大,其余依次递减,建议不超过3个。
3.2.1 高级配置
支持配置高级参数以保证实时任务的稳定输出。
目前支持的参数及说明如下:
参数名称 | 说明 |
|---|---|
parallelism.default | 默认并行度 |
taskmanager.memory.process.size | taskmanager的总进程内存大小 |
yarn.containers.vcores | 每个yarn容器的虚拟核数 |
taskmanager.numberOfTaskSlots | taskmanager提供的插槽数 |
jobmanager.memory.process.size | jobmanager的总进程内存大小 |
yarn.appmaster.vcores | yarn中appmaster的虚拟核数 |
注意
仅在前置节点存在「数据清洗」算子或输出数据集配置「CDP基准ID字段」时高级参数有效。