客户数据平台
客户数据平台






- 文档首页
 客户数据平台用户指南构建标签体系概述
客户数据平台用户指南构建标签体系概述

标签是客户数据平台的基础,用户分群,群体洞察以及营销应用都依托于标签,用户需从业务场景出发,构建适用于自身业务模式和逻辑的标签体系,为企业的精细化运营及精准营销服务,进而深入挖掘潜在的商业价值。
在本模块内用户可围绕标签,进行查询,新建,编辑,删除等操作,搭建层次分明的标签体系,让标签为业务目标服务。
- 需项目管理员在 项目中心-权限 中,给对应用户开启 标签体系 模块的权限,开启后,用户即可使用该功能。
- 用户需要完成 数据管理 模块的前置数据准备工作后,才可以在该模块构建标签。
- 标签构建需要在 资源总额度 范围内使用,资源额度由开关控制,可以联系你的客户经理增购计算资源。
*注意:仅例行更新的标签及分群会消耗资源额度,详细的消耗规则如下:
资源类型 | 资源构建方式 | 更新方式 | ||
|---|---|---|---|---|
手动更新 | 例行更新 | 实时更新 | ||
标签 | 规则标签 | 消耗 | 消耗 | 按实时资源限制,不在此处消耗统计 |
首末次标签 | 消耗 | 消耗 | ||
统计标签 | 消耗 | 消耗 | ||
偏好标签 | 消耗 | 消耗 | ||
排序标签 | 消耗 | 消耗 | ||
运算标签 | 消耗 | 消耗 | ||
生命周期标签 | 消耗 | 消耗 | ||
RFM标签 | 消耗 | 消耗 | / | |
SQL标签 | 消耗 | 消耗 | 按实时资源限制,不在此处消耗统计 | |
导入标签 | / | 消耗 | / | |
人工录入标签 | 消耗 | / | / | |
智能外呼标签(只有购买该产品的用户才可展示该标签) | / | 消耗 | / | |
智慧听鉴标签(只有购买该产品的用户才可展示该标签) | / | 消耗 | / | |
自定义模型标签 | 不消耗 | 不消耗 | / | |
分群 | 规则分群(私域) | 不消耗 | 消耗 | 按实时资源限制,不在此处消耗统计 |
上传人群包 | 不消耗 | / | ||
私域Lookalike创建人群 | 不消耗 | / | ||
聚类模型生成人群 | 不消耗 | / | ||
洞察报告导出人群 | 不消耗 | / | ||
主体转换人群 | 不消耗 | 消耗 | ||
多维特征分析导出人群 | 不消耗 | / | ||
联动产品同步人群(如ABI/Finder同步人群) | 不消耗 | / | ||
说明:分群子包不参与计算;/代表功能不支持,不消耗的逻辑说明。
概念 | 解释说明 |
|---|---|
标签 | 依据行为、属性等多维度数据,借助业务逻辑或者模型能力而创建的一种标识形式。它具备明确的业务指导意义,其标签值以可枚举的方式呈现,能够为业务活动提供清晰、可量化的参考依据 |
标签体系 | 由标签构成,以结构性的方式对标签内容,包括标签的数量、分类、层级关系等进行呈现和管理 |
全量标签(Mautag) | 该集团全部用户的总数统计标签,此数据会每日进行更新 |
文本型标签值 | 用于标签值为文本类型的标签,常见使用该类型的标签例如姓名、用户名、城市等 |
整数型标签值 | 用于标签值为整数类型的标签,常见使用该类型的标签例如年龄、点击次数、来店次数等 |
小数型标签值 | 用于标签值为小数类型的标签,常见使用该类型的标签例如费用、占比等 |
多值型标签值 | 当标签值存在多个值时使用,常见使用该类型的标签例如兴趣爱好、喜爱话题等 |
日期型标签值 | 用于标签值为日期类型的标签,具体到日期,常见使用该类型的标签例如出生日期等 |
日期时间型标签值 | 用于标签值为日期时间类型的标签,具体到时分秒,常见使用该类型的标签例如更新日期等 |
AIPL模型 | 一种将品牌人群资产定量化、链路化运营的手段,A(Awareness)代表品牌认知人群;I(Interest)代表品牌兴趣人群;P(Purchase)代表品牌购买人群;L(Loyalty)代表品牌忠诚人群 |
5A模型 | 菲利普科特勒在《营销革命4.0》里提出的营销模型,A1 了解(Aware)指顾客被动接受信息;A2 吸引(appeal)指品牌印象增加的顾客;A3 问询(Ask)指被好奇驱使主动搜索信息的顾客;A4 行动(Act)指采取行动的顾客;A5 拥护(Advocate)指对品牌有忠诚度并进行宣扬的客户 |
RFM模型 | 模型通过对每个用户R值、F值、M值高低的评估,将其对应到不同的区间中去,从而将用户划分为8种用户价值类型,分别为:重要价值客户、重要换回客户、重要深耕客户、重要挽留客户、潜力客户、新客户、一般维持客户、流失客户。 |
圈选条件“且” | 满足所有规则或组合规则条件则视为符合标签规则 |
圈选条件“或” | 满足任意规则或组合规则条件则视为符合标签规则 |
不包含 | 当前数据集的数据范围内不符合条件的用户 |
包含 | 当前数据集的数据范围内符合条件的用户 |
全局不包含 | 在全量用户(含未被打上该标签的用户)排除该标签值的用户(举例:如果全量用户100人,其中10人被打上“是否老年”标签:其中“是”4人、“否”5人、“其他”为1人。 那么选择该标签全局不包含 “是”,即选中96人。) |
按离散数值划分标签值 | 直接使用指标计算结果值作为标签值 |
按数值区间划分标签值 | 基于指标计算结果值的阈值区间范围设置用户分层标签 |
- 基于用户生命周期阶段分层运营
- 基于指标拆解象限图,划分用户价值等级,明确运营目标
- 基于活动特征,定向选择用户群体,提升活动ROI
Q1. 圈选组件中的聚合逻辑是否支持去重计数呢?
A :支持去重计数功能。支持行为表对文本型的数据进行去重计数,计算逻辑即:对行为表的指定事件下的去重的事件属性值个数做统计。
应用场景
- APP访问(事件)城市(事件属性1)的去重个数和(事件属性2)省份的个数。
- 基于SQL逻辑即:Select count distinct event_x_key1(事件属性1)。
说明
应用模块:本次聚合逻辑生效范围包括:规则标签、规则分群、个体画像、群体画像(选分群)、统计标签。
操作步骤
以规则标签为例,点击标签体系-新建标签-规则标签,进入规则标签创建界面。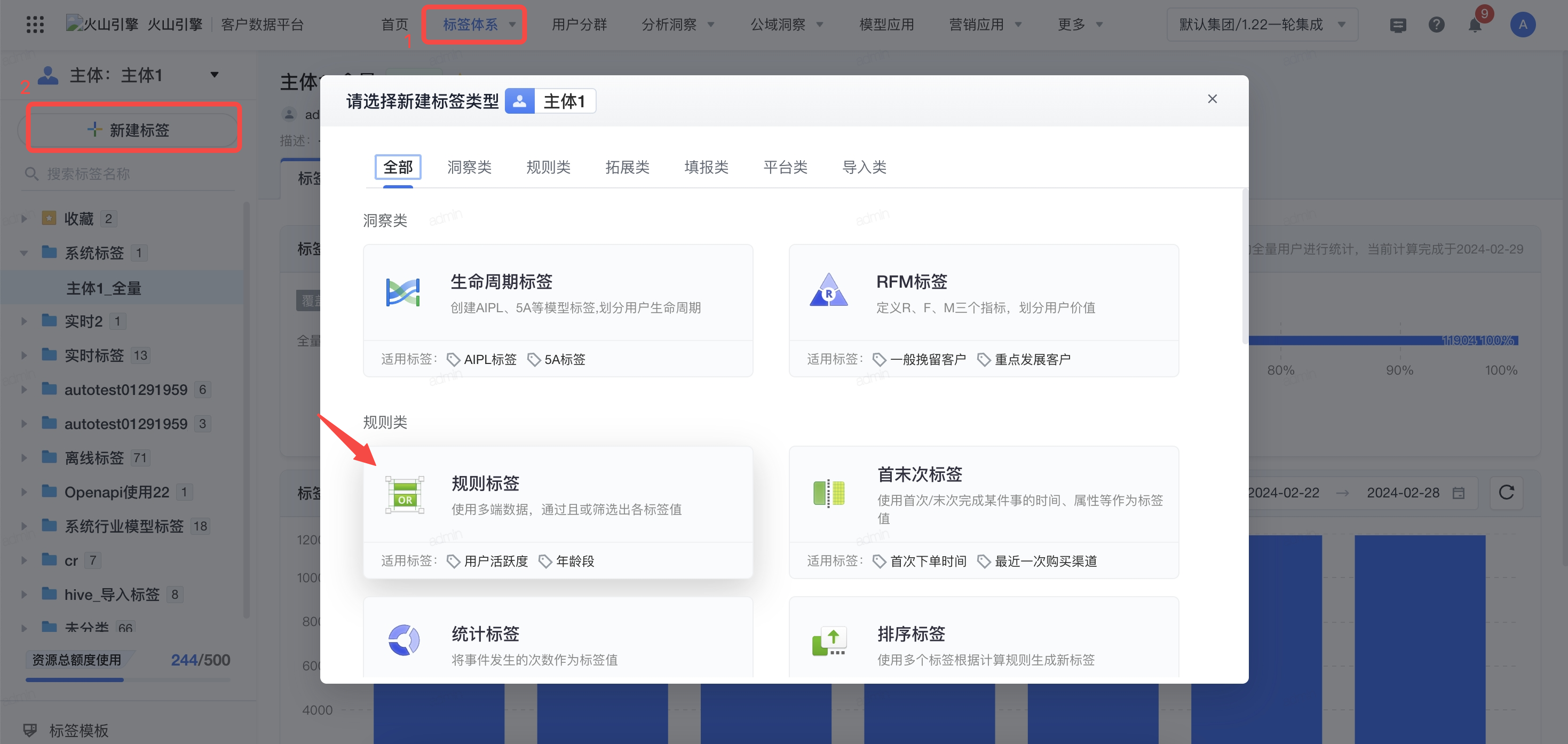
配置完成基础信息后,进入标签规则界面。可对明细数据类型进行去重计数统计。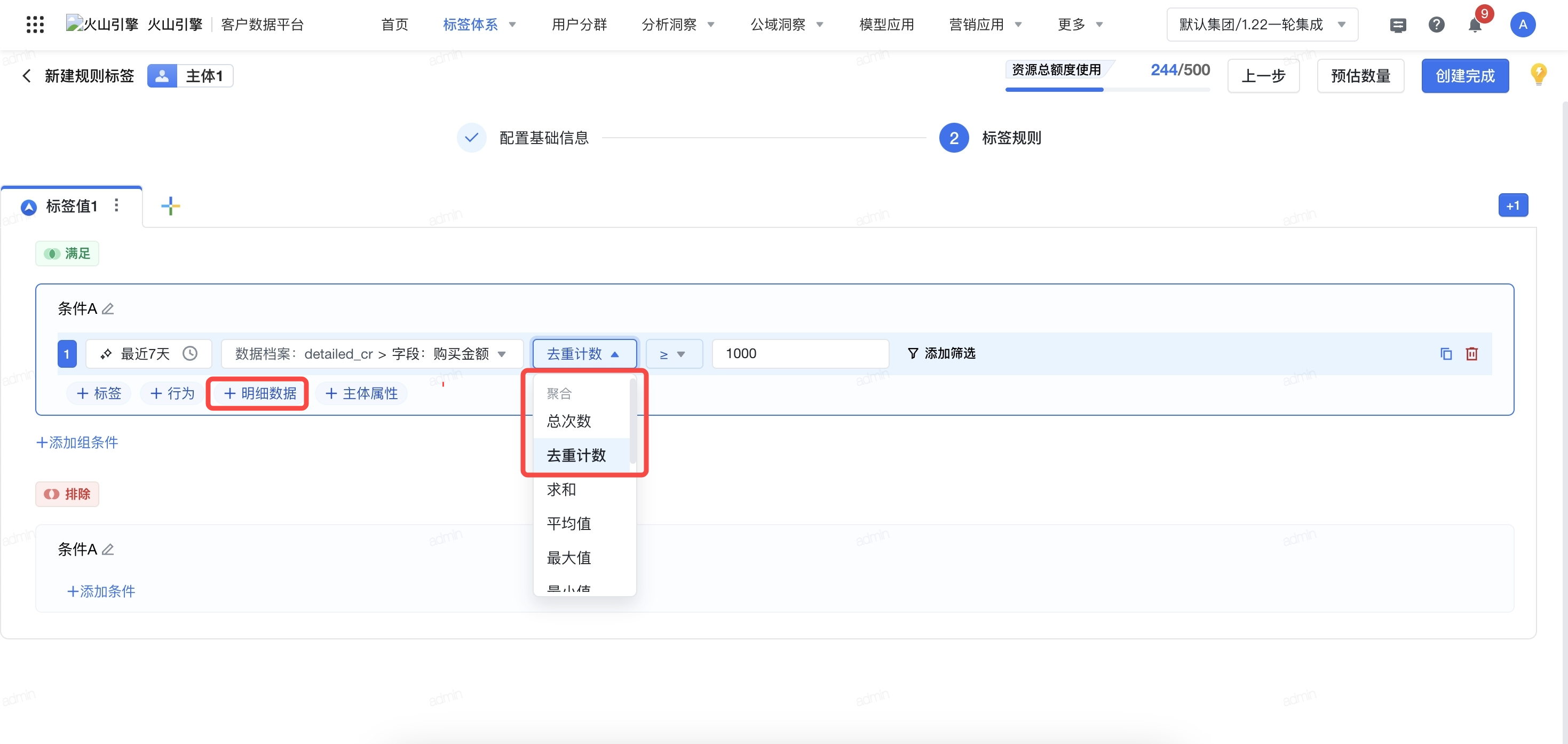
图片示例解释:若同一个用户id在七天内进行了>1次且购买金额>1000的购买,计算时候只计数该用户1次。
Q2. 全量标签更新取值逻辑支持哪几种呢?
A :支持历史数据合并:更新标签时可选择保留历史数据,保持数据连续性。
B :支持全量数据更新:或选择基于最新规则重新计算,确保标签准确性。
Q3. 日期类标签/属性可以用于“距今多少天”的计算吗?
日期类标签/属性支持配置1970年型日期型标签,配置后可以在分析等模块展示。
例如:日期类标签/属性,可以使用(如注册会员时间,生日,媒资发行年份等)用于“距今多少天”、“偏好”等计算。