大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据集成数据源列表配置 OceanBase 数据源
大数据研发治理套件用户指南数据集成数据源列表配置 OceanBase 数据源

OceanBase 数据源为您提供读取 OceanBase 数据的单向通道能力,实现将读取出来的数据,写入到不同的目标数据源中。
本文为您介绍 DataSail 的 OceanBase 数据同步的能力支持情况。
1 支持的 OceanBase 版本
- 离线读:
支持自建 OceanBase Mysql & Oracle 模式,支持 3.x 版本和 4.x 版本。
2 使用限制
- 当前仅支持离线读 OceanBase 数据,后续敬请期待离线写 OceanBase 能力。
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员
3 通用要求
为确保同步任务使用的独享集成资源组具有 OceanBase 数据库节点的网络访问能力,您需将独享集成资源组和 OceanBase 数据库节点网络打通,详见网络连通解决方案。
- 若通过 VPC 网络访问,则独享集成资源组所在 VPC 中的 IPv4 CIDR 地址,需加入到 OceanBase 访问白名单中:
- 确认集成资源组所在的 VPC:
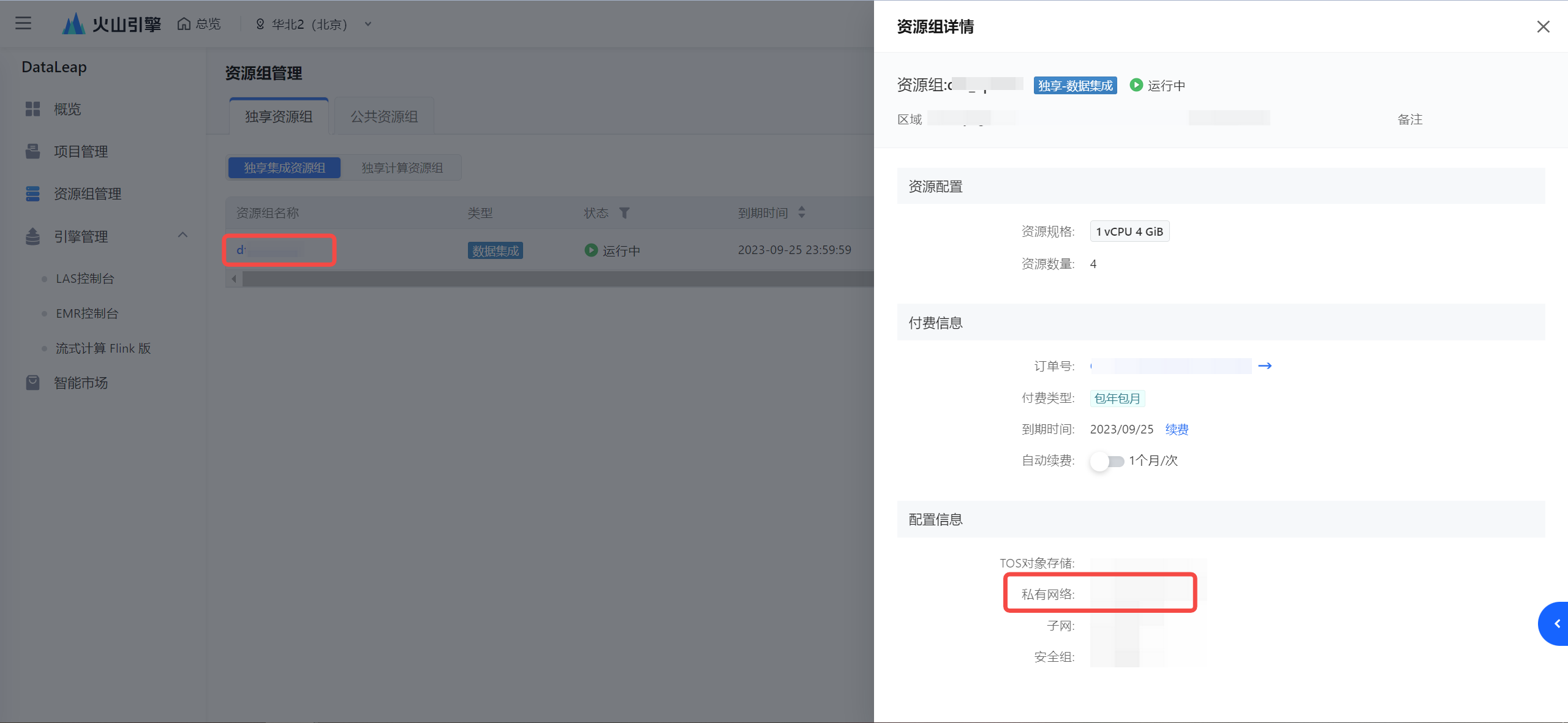
- 查看 VPC 的 IPv4 CIDR 地址:
注意
若考虑安全因素,减少 IP CIDR 的访问范围,您至少需要将集成资源组绑定的子网下的 IPv4 CIDR 地址加入到数据库白名单中。
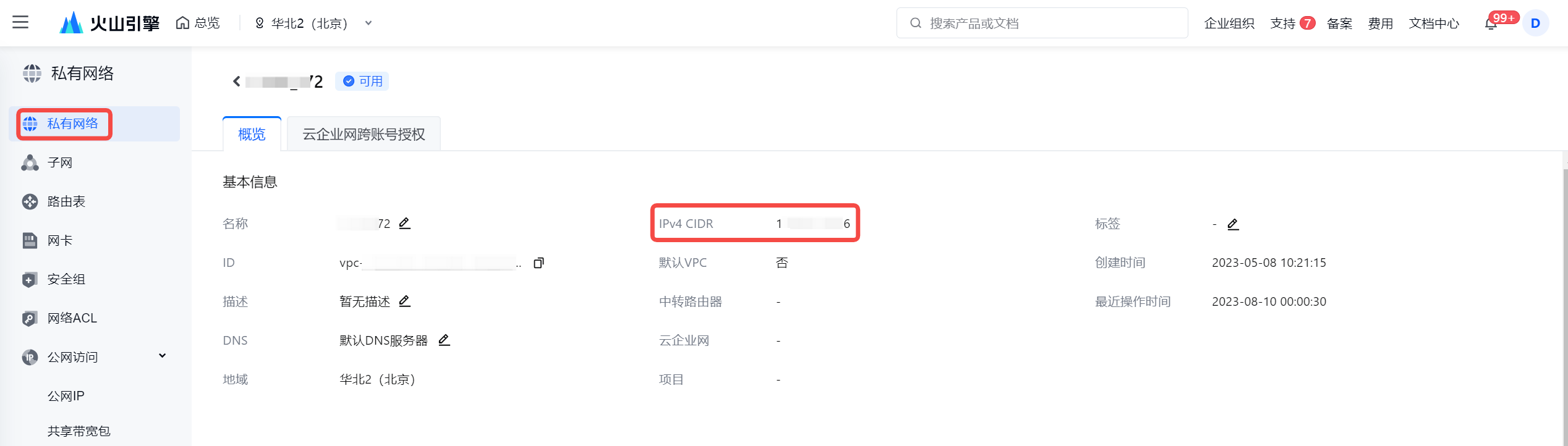
- 将获取到的 IPv4 CIDR 地址添加进 OceanBase 数据库白名单中。
- 确认集成资源组所在的 VPC:
- 若是通过公网形式访问 OceanBase 数据库,则您需进行以下操作:
- 独享集成资源组开通公网访问能力,操作详见开通公网。
- 并将公网 IP 地址,添加进 OceanBase 数据库白名单中。
4 支持的字段类型
当前不同模式主要字段支持情况如下:
MySQL 模式
字段类型
离线读(OceanBase Reader)
BIT
支持
BOOL
支持
BOOLEAN
支持
TINYINT
支持
SMALLINT
支持
MEDIUMINT
支持
INT
支持
INTEGER
支持
BIGINT
支持
DECIMAL
支持
NUMERIC
支持
FLOAT
支持
DEC
支持
DOUBLE
支持
REAL
支持
CHAR
支持
VARCHAR
支持
TINYTEXT
支持
TEXT
支持
MEDIUMTEXT
支持
LONGTEXT
支持
ENUM
支持
JSON
支持
SET
支持
BINARY
支持
VARBINARY
支持
TINYBLOB
支持
BLOB
支持
MEDIUMBLOB
支持
LONGBLOB
支持
DATE
支持
TIME
支持
DATETIME
支持
TIMESTAMP
支持
YEAR
支持
Oracle 模式
字段类型
离线读(OceanBase Reader)
NUMBER
支持
FLOAT
支持
BINARY_FLOAT
支持
BINARY_DOUBLE
支持
CHAR
支持
NCHAR
支持
VARCHAR2
支持
NVARCHAR2
支持
VARCHAR
支持
CLOB
支持
RAW
支持
DATE
支持
TIMESTAMP
支持
TIMESTAMP WITH TIME ZONE
支持
TIMESTAMP WITH LOCAL TIME ZONE
支持
5 数据同步任务开发
5.1 数据源注册
新建数据源操作详见配置数据源,下面为您介绍用连接串方式配置 OceanBase 数据源信息:
注意
Oceanbase 侧如果是白名单访问机制,则不同网络环境的连接串地址,需要添加不同的 IP 地址到数据库白名单中,确保集成资源组使用的 VPC 与 Oceanbase 网络能互通:
- 如果使用的是公网连接串访问,则需要给集成资源组添加公网 IP,并将公网 IP 地址加入到白名单中。
- 如果使用的是私网连接串访问,则需要将资源组 VPC 下的 IPv4 CIDR 地址加入到白名单中。
详见网络连通解决方案。
参数 | 说明 |
|---|---|
基本配置 | |
数据源类型 | OceanBase |
接入方式 | 连接串 |
数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
参数配置 | |
数据库模式 | 下拉选择 OceanBase 数据库模式,支持选择 MySQL 或 Oracle 模式。 |
JDBC URL | 填写连接 OceanBase 数据库的 JDBC 地址信息:
|
用户名 | 有权限访问数据库的用户名信息。 |
密码 | 输入用户名对应的密码信息。 |
5.2 新建离线任务
OceanBase 数据源测试连通性成功后,进入到数据开发界面,开始新建 OceanBase 相关通道任务。
新建任务方式详见离线数据同步。
5.3 可视化配置说明
任务创建成功后,您可根据实际场景,配置 OceanBase 离线读通道任务。
5.3.1 OceanBase 离线读
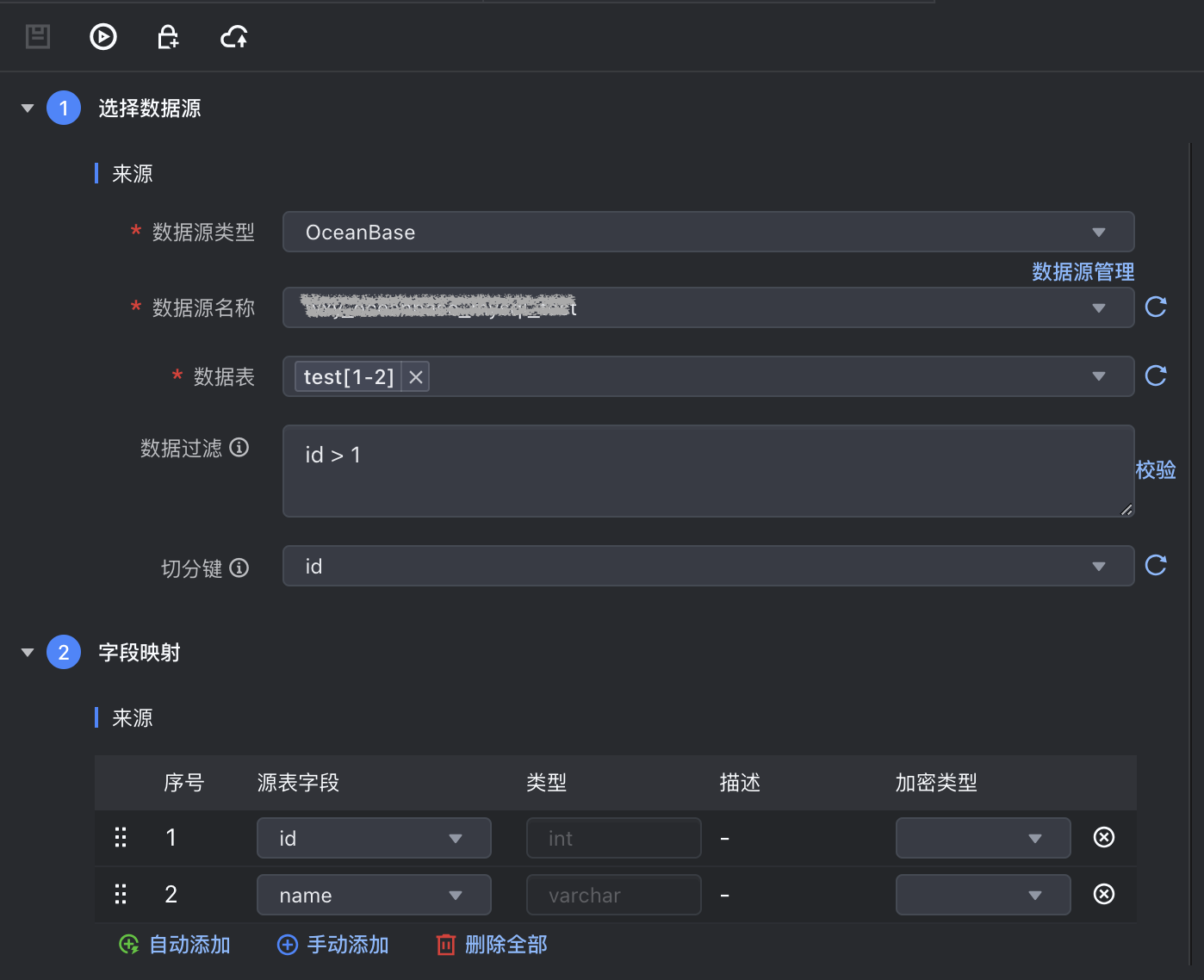
数据来源选择 OceanBase,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|---|
*数据源类型 | 下拉选择 OceanBase 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 OceanBase 数据源,下拉可选。 |
*数据表 | 选择需要采集的数据表信息,您可同时选择多个 Schema 相同的表进行数据同步,支持区间表达式和时间表达式方式,来快速配置选择多个表。
|
数据过滤 | 支持您将需要同步的数据进行筛选条件设置,只同步符合过滤条件的数据,可直接填写关键词 where 后的过滤 SQL 语句,例如:create_time > '${date}',不需要填写 where 关键字。 说明 该过滤语句通常用作增量同步,暂时不支持 limit 关键字过滤,其 SQL 语法需要和选择的数据源类型对应。 |
切分建 | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 |
5.3.2 字段映射
数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
您可通过以下三种方式操作字段映射关系:
- 自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
- 手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
- 移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
5.4 DSL 配置说明
OceanBase 数据源支持使用脚本模式(DSL)的方式进行配置。
在某些复杂场景下,或当数据源类型暂不支持可视化配置时,您可通过任务脚本的方式,按照统一的 Json 格式,编写 OceanBase Reader 参数脚本代码,来运行数据集成任务。
3.4.1 进入 DSL 模式
进入 DSL 模式操作流程,可详见 MySQL 数据源-4.4.1 进入DSL 模式。
3.4.2 OceanBase 离线读
进入 DSL 模式编辑界面后,您可根据实际情况替换相应参数,OceanBase 离线读脚本示例如下:
// 变量使用规则如下: // 1.自定义参数变量: {{}}, 比如{{number}} // 2.系统时间变量${}, 比如 ${date}、${hour} // ************************************** { // [required] dsl version, suggest to use latest version "version": "0.2", // [required] execution mode, supoort streaming / batch now "type": "batch", // reader config "reader": { // [required] datasource type "type": "oceanbase", // [optional] datasource id, set it if you have registered datasource "datasource_id": 12345, // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value "columns": [ { "name": "name_sample", "type": "type_sample" } ], "filter": "id > 10", "split_pk": "split_pk_sample", "table_name": "table_name_sample" } }, // writer config "writer": { }, // common config "common": { // [required] user parameter "parameter": { // ********** please write here ********** // "key" : value } } }
Reader 参数说明,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数:
参数名 | 描述 | 默认值 |
|---|---|---|
*type | 数据源类型,输入 OceanBase 类型的 Reader type,默认固定值填写:oceanbase | 无 |
*datasource_id | 注册的 OceanBase 数据源 ID。可以在项目控制台 > 数据源管理界面中查找。 | 无 |
*table_name | 需要同步的数据表名称,支持多表同步至一张目标表,多表同步须保证多张表结构一致。
| 无 |
filter | 同步数据的筛选条件,同步数据时只会同步符合过滤条件的数据,直接填写关键词 where 后的过滤 SQL 语句。
| 无 |
split_pk | 根据配置的字段进行数据分片,建议使用主键或有索引的列作为切分键,同步任务会启动并发任务进行数据同步,提高同步速率:
说明 目前仅支持类型为整型或字符串的字段作为切分建。 | 无 |
*columns | 所配置的表中需要同步的列名集合,使用 JSON 的数组描述字段信息。
| 无 |
5.5 高级参数说明
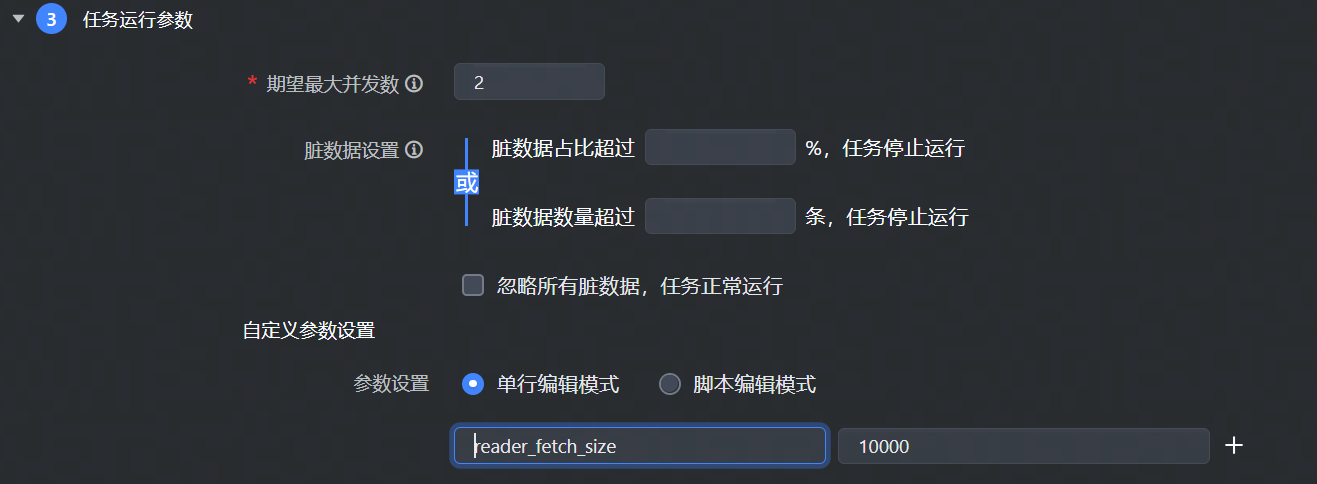
- 对于可视化通道任务,读参数可在任务运行参数 > 自定义参数设置中配置,如下图所示:
- 对于 DSL 任务,读参数请配置到
reader.parameter下,直接输入参数名称和参数值。如下图所示: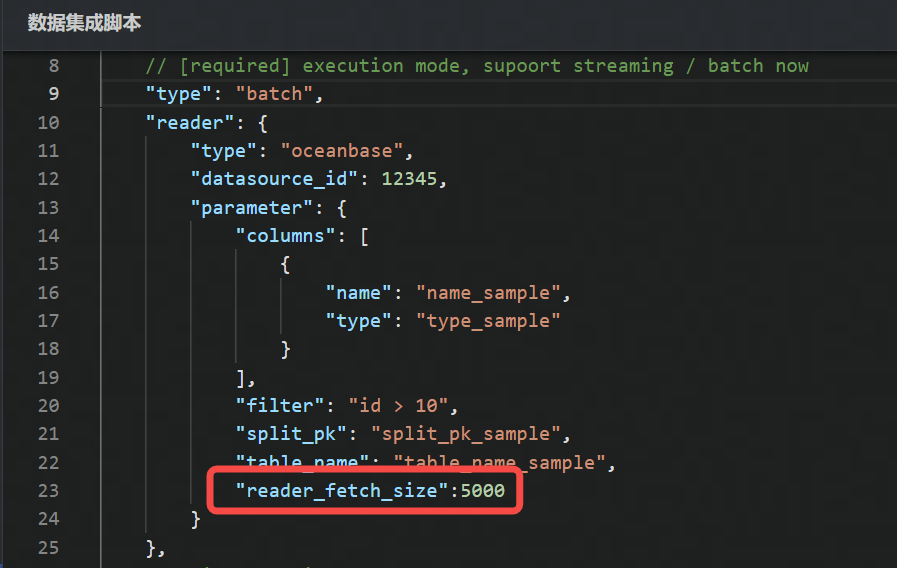
5.5.1 OceanBase 批式读常见参数
参数名 | 描述 | 默认值 |
|---|---|---|
init_sql | 读取数据前执行的 SQL 语句。对于视图的查询可能需要使用 init SQL 语句初始化环境。 | 无 |
reader_fetch_size | 每次拉取的数据条数,只在准确分片中有效。 | 10000 |
shard_split_mode | 分片模式,支持准确分片、并发分片、不分片三种模式:
| 准确分片 |
customized_sql | 自定义查询读取 SQL 语句中。filter 过滤配置项不足以描述所筛选的条件,通过该配置型来自定义筛选SQL。 | 无 |