大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件最佳实践数据开发Notebook 实践Kernel 类型之 Python Spark on EMR 实践
大数据研发治理套件最佳实践数据开发Notebook 实践Kernel 类型之 Python Spark on EMR 实践

为满足用户数据开发、数据探索场景提供的交互式开发环境。 Notebook 基于开源的 Jupyterlab 定制化开发,支持使用 Python、Bash、Markdown 语言、引入第三方库完成数据查询操作。本文将为您演示 Notebook 任务类型中使用 Python Spark on EMR 的 Kernel 类型。
1 注意事项
- Python Spark on EMR 的 Kernel 类型,仅支持火山引擎 E-MapReduce(EMR)Hadoop、TensorFlow 集群类型创建。
2 准备工作
- 已开通相应版本的 DataLeap 服务并创建 DataLeap 项目。详见开通服务操作。
- Notebook 任务使用 Python Spark on EMR 的 Kernel 类型,需配合独享计算资源组服务一同使用,您需购买合适资源规格的独享计算资源组,并将其绑定至创建成功的 DataLeap 项目下。
购买操作详见资源组管理,项目绑定操作详见创建项目-服务绑定。 - 已创建火山引擎 E-MapReduce(EMR)Hadoop 集群类型。详见创建集群。
注意
独享计算资源组和 EMR Hadoop 集群创建时,所绑定的 VPC、子网、安全组和可用区等网络配置信息,需保持一致。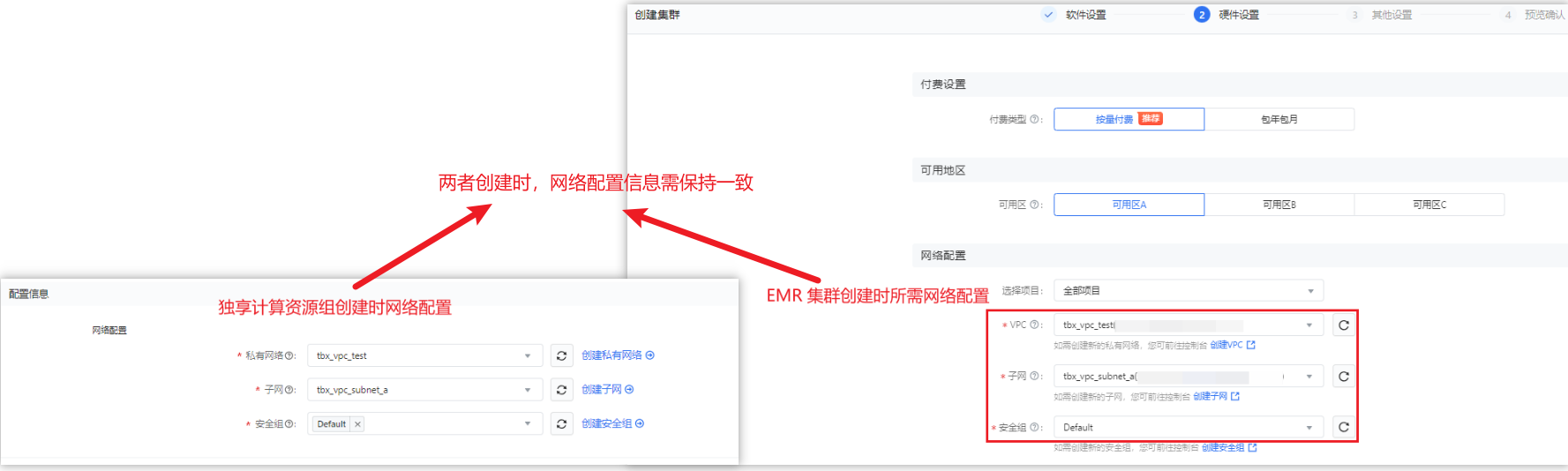
3 新建 Notebook 任务
- 登录 DataLeap租户控制台。
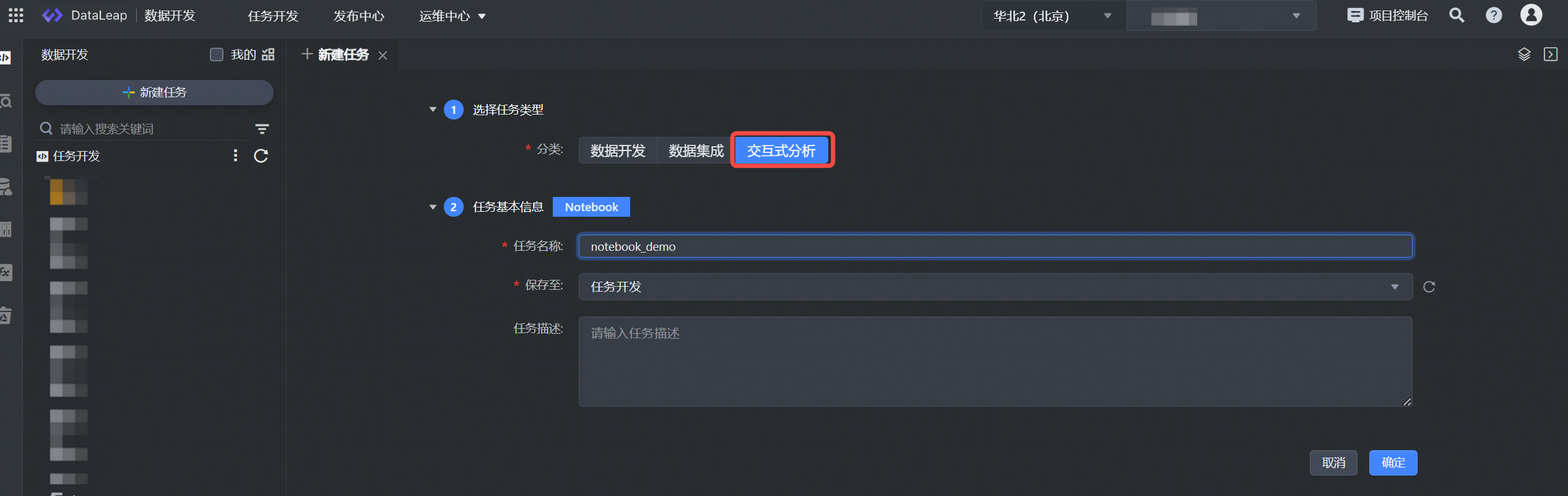
- 在具体项目中进入数据开发界面,并单击新建任务按钮进行任务新建。
- 选择交互式分析任务类型。
- 填写任务基本信息,单击确定按钮,完成任务创建。
4 配置任务
4.1 配置环境启动信息
新建任务完成后,首次打开 Notebook,需先配置环境启动信息:
其中名称前带 * 的参数为必填参数,名称前未带 * 的参数为可选参数。
参数 | 说明 |
|---|---|
*选择Kernel | Notebook Kernel 是执行 Notebook 文件包含代码的计算引擎,比如 ipython kernel 执行 python 代码。 |
*关联实例 | Python Spark on EMR 的 Kernel 类型,支持下拉选择项目控制台中已绑定的 EMR 集群实例信息,项目支持绑定多个 EMR 集群,您可根据实际情况选择已绑定的 EMR Hadoop 集群。 |
*计算资源组 | 下拉选择已绑定至项目中的独享计算资源组。 |
资源配置 | 资源可根据独享计算资源组规格,进行配置,以 CU 为单位,默认配置 1CU(1CU = 1Core 4GB),下拉可选择更多规格的资源配置。 |
Spark 参数 | 输入任务执行环境中,所需要用到的 Spark 参数,可通过以下方式进行配置:
|
说明
打开 Notebook 任务,配置环境后,默认将自动启动 Kernel,您也可以勾选“Notebook任务打开时,默认不自动启动Kernel。 ”选项,将暂不启动 Kernel。
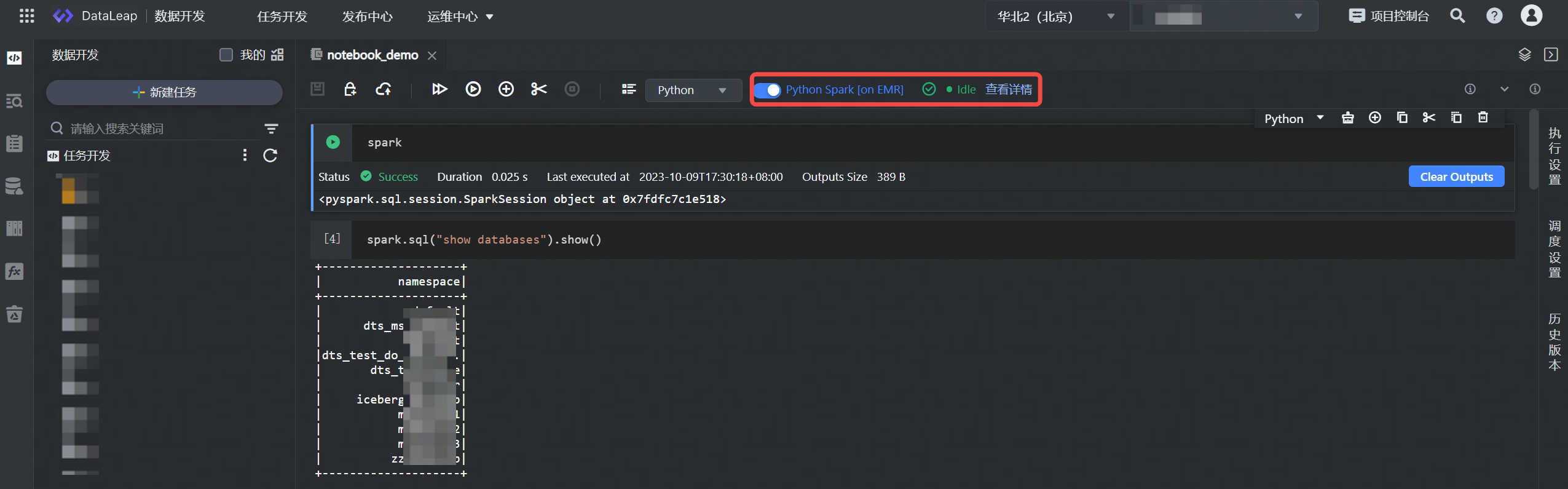
启动信息配置完成后,单击确认按钮,启动 Kernel 连接,待导航栏 Kernel 状态为 Idle 后,即代表启动成功,可进行后续的调试运行代码逻辑。
- Kernel 状态说明:
- Idle 空闲状态:Kernel 处于空闲状态,随时可运行任务。
- Busy 状态:正在运行代码,Kernel 处于忙碌状态,需等待当前代码执行完成后,再执行后续任务代码。
- disconnected 断开状态 (断网):Kernel 有网络断开的情况,您需要手动刷新下界面,启动 Kernel 后,再执行任务。
- connected 连接状态:Kernel 正处于连接状态。
- dead 状态:连接失败状态,您可以在右侧查看失败原因。
- 您可单击 Kernel 按钮,进行 Kernel 高级设置参数替换。
4.2 编辑任务
启动 Kernel 状态正常后,即可进入代码编辑查询界面。目前支持 Python、Bash、Markdown、Raw 三种语言。
您可以在当前的 cell 框中,输入对应语言的代码逻辑,以 Python 语言为例,为您介绍几种使用示例:
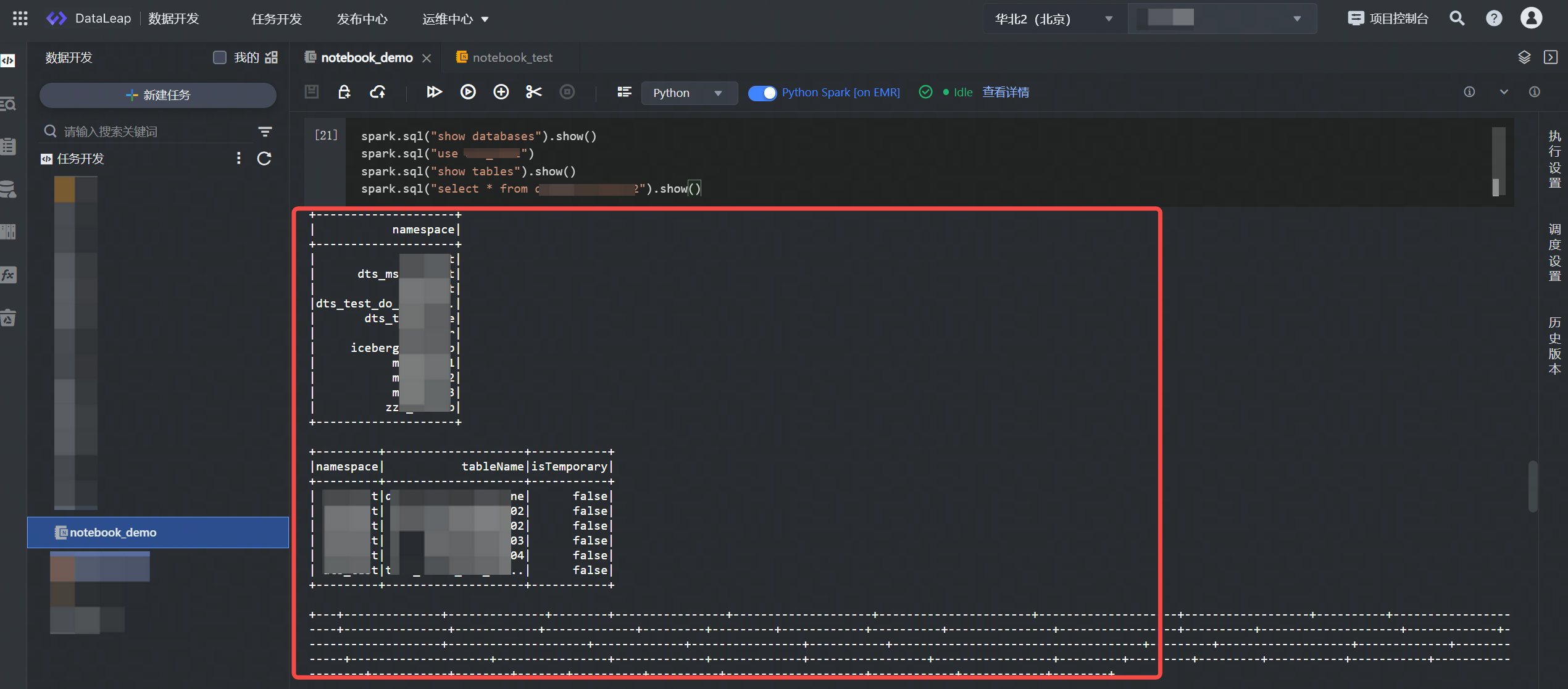
查询 EMR Hive 表数据示例:
spark.sql("show databases").show() spark.sql("use database_name") spark.sql("show tables").show() spark.sql("select * from table_name").show()单击上方操作栏中的运行按钮,执行所编辑的示例语句,等待执行完成后,便可在下方查看运行结果。
注意
Notebook 调试场景,需进入 EMR 控制台 > 集群详情 > 服务列表 > Spark 服务参数界面,在 livy.conf 配置文件中,对以下两个参数进行调整:
- 添加自定义参数 livy.server.session.timeout-check.skip-busy = true
- livy.server.session.timeout 调为 43200000 (12h)
- 如果会用比较多的 Notebook EMR Spark Kernel 类型,建议调大 livy.server.session.max-creation
使用 pyplot 画图:
- 登录 EMR 集群,安装示例所使用到的第三方包。登录操作详见登录集群。
- 新建 Notebook 任务,并选择 Python Spark on EMR 的 Kernel 类型,等待任务启动。
- 启动成功后,输入以下绘图示例语句:
说明
绘图语句,需要在绘图 cell 最后一行命令中添加
%matplot plt语句才可正常显示绘图结果。import matplotlib.pyplot as plt fig, ax = plt.subplots() fruits = ['apple', 'blueberry', 'cherry', 'orange'] counts = [40, 100, 30, 55] bar_labels = ['red', 'blue', '_red', 'orange'] bar_colors = ['tab:red', 'tab:blue', 'tab:red', 'tab:orange'] ax.bar(fruits, counts, label=bar_labels, color=bar_colors) ax.set_ylabel('fruit supply') ax.set_title('Fruit supply by kind and color') ax.legend(title='Fruit color') plt.show() %matplot plt
使用 Bash 语言编辑示例:
您可在 Cell 编辑框中,根据实际场景输入 Shell 语句,示例如下:echo ${date} #打印业务日期使用 Markdown 语言编辑示例:
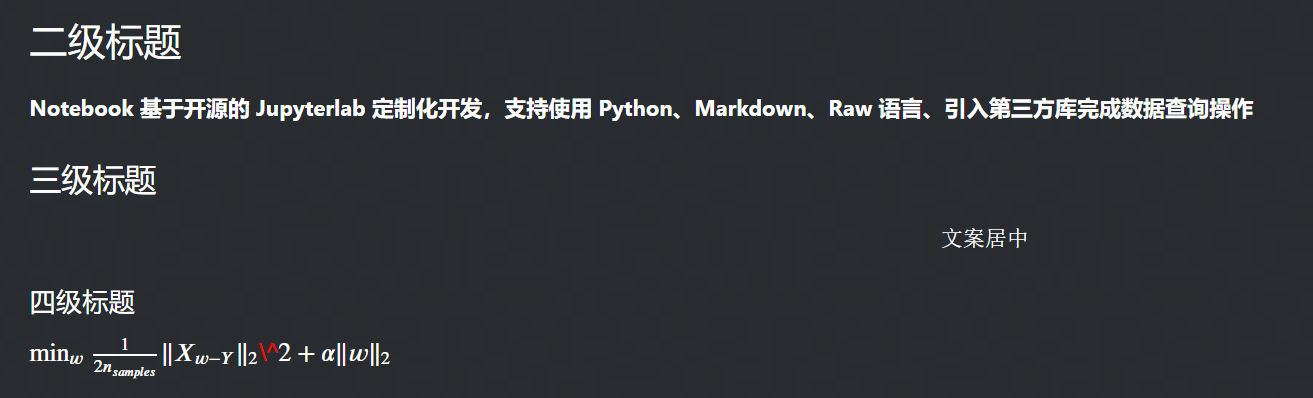
您可在 Cell 编辑框中,根据实际场景输入 Markdown 语句,示例如下:## 二级标题 **Notebook 基于开源的 Jupyterlab 定制化开发,支持使用 Python、Markdown、Raw 语言、引入第三方库完成数据查询操作** ### 三级标题 $$文案居中$$ #### 四级标题 $\min_w \frac{1}{2n_{samples}} \Vert X_{w-Y}\Vert _2\^2+\alpha \Vert w \Vert _2$单击上方操作栏运行按钮(或快捷键:shift + Enter),等待执行完成后,便可展示如下结果:
Raw 纯文本示例
Notebook 中的 Raw 语言是纯文本形式,您可根据实际情况输入相应的文本信息用于记录,这里是文本编辑模式 您可在此输入所需记录的信息,以上示例为您演示的是: 1、查询 EMR Hive 表数据; 2、使用 pyplot 画图; 3、Markdown 语言示例。
4.3 代码配置 Spark Conf
若您不想在环境启动 Kernel 页面时配置 Spark conf 参数,想在代码中配置 Spark conf 时,您需要先新增一个 cell,并按照如下形式输入代码:
%%configure -f {"conf": {"spark.driver.cores": 3, "spark.executor.cores": 3}}
说明
启动页面配置的 spark conf 和代码里配置的 spark conf 均会生效。
4.4 内置变量
DataLeap 平台的 Notebook 任务中,已为您添加以下内置变量参数,您无需再操作以下变量:
sc: SparkContext spark: pyspark.sql.session.SparkSession
4.5 任务基础设置
- 功能操作:
Notebook 任务编辑界面更多操作,如 Cell 单元框功能按钮说明、参数可详见 Notebook - 4.2 编辑任务。 - 执行设置:
您可单击进入右侧侧边栏执行设置按钮,进入执行设置界面,配置计算资源组、资源配置、Spark参数等。具体操作详见上方 5.1 配置环境启动信息。 - 调度设置:
进入右侧边栏调度设置,配置节点调度相关属性。设置操作详见:调度设置。
5 后续操作
数据开发界面任务编辑且测试完成后,后续您可进行任务的提交发布,以及任务运维操作。详见5.1 离线任务提交、任务运维。