大数据研发治理套件
大数据研发治理套件






- 文档首页
 大数据研发治理套件用户指南数据集成数据源列表配置 CloudFS 数据源
大数据研发治理套件用户指南数据集成数据源列表配置 CloudFS 数据源

DataSail 中 CloudFS 数据源,为您提供了可视化离线读和可视化实时写入火山引擎大数据文件存储(Cloud File System , 简称 CloudFS、CFS)或湖仓一体分析服务(LAS)文件的数据集成通道能力,实现和不同数据源之间进行数据传输。
本文将为您介绍 DataSail 对 CloudFS 数据同步能力的支持情况。
1 使用限制
当前仅支持离线读 CloudFS 和实时写入 CloudFS 能力。
子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
2 通用要求
您需先创建 CloudFS 文件存储或 LAS 文件管理,操作详见各文档说明。
确保数据集成同步任务使用的独享集成资源组具有目标 CloudFS 文件存储集群 DataNode 和 NameNode 的网络访问能力:
CloudFS 文件存储集群使用的 VPC 需和独享集成资源组中的 VPC 保持一致,其 VPC 下的子网和安全组也尽可能保持一致。
若是连接串形式访问,您可通过公网或内网形式访问,不同网络环境处理方式详见网络连通解决方案。
离线读
CloudFS 读取作业以 root 作为账户读取文件,所以您需要确保 CloudFS 集群内 root 账户具有目标 CloudFS 文件的读权限。
DataSail 支持读取以下格式的文件:
Json:要求文件内每行为一个 Json 数据,key 字段大小写敏感。
Pb:Protobuf 格式,需要在作业配置界面填写 Pb 类定义和需要读取的类名。
Parquet:parquet 文件格式,会自动解析 Schema, 无需额外配置。
CSV:单条记录按行分隔,单条记录内部默认按英文逗号分隔,可更改行内分隔符。
TXT:文本文件,单条记录按行分隔,单条记录内部可配置常用分隔符(如逗号、空格)或自定义分隔符, 支持 GBK 和 UTF-8 字符集。
实时写
目前仅支持写 CloudFS 数据源。
CloudFS 数据源对上游数据格式有要求,目前支持 Json 和 Pb。其中 Pb 格式需要在作业配置界面指定 Pb 类定义和目标类名。
CloudFS Writer 会先写入一个临时目录,在一定时间区间的数据全部到达后,再将临时文件移动到目标目录,因此文件在目标目录可见存在一定延迟,目前支持天级和小时级延迟的写入。
CloudFS Writer 以 root 作为 Hadoop user 写入文件,需提前确认指定路径的读写权限。
CloudFS 实时 Writer目前上游只能承接 BMQ、RocketMQ、Kafka 和 DataSail 这几种消息队列类型数据源。这几种数据源会将消息的原始负载直接发送到 CloudFS Writer,然后由 CloudFS Writer 直接以二进制形式写入 CloudFS 文件,因此不需要配置 column 字段。
3 支持的字段类型
3.1 离线读
目前支持离线读取 Json 和 Pb 格式的文件,内部支持的数据类型如下:
| 类型分类 | 数据集成 column 配置类型 | Json 数据类型 | Pb 数据类型 |
|---|---|---|---|
整数类 | tinyint、int、bigint | 数字 | int32、int64、 |
| 浮点类 | float、double、decimal | float、double | |
| 字符串类 | string | 字符串 | string、enum |
| 时间类 | date、timestamp | 时间字符串、整数时间戳 | 时间字符串、整数时间戳 |
| 布尔类 | boolean | 布尔值 | bool |
| 数组类 | array | 数组 | repeated |
| 字典类 | map | 对象 | message |
| 二进制类型 | binary | bytes |
4 数据同步任务开发
4.1 数据源注册
新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 CloudFS 数据源配置相关信息:
火山引擎 CloudFS 接入方式
注意
CloudFS 文件存储集群所在的 VPC 需和独享集成资源组中的 VPC 保持一致,确保网络能互相访问。不同 VPC 情况时,详见“2 通用要求”相关说明。
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数说明 基本配置 *数据源类型 CloudFS *接入方式 火山引擎 CloudFS *数据源名称 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 参数配置 *Access key ID 进入火山引擎,访问控制台的密钥管理界面,复制 Access key ID 填写到此处。如果为子用户,请联系主账号获取密钥。 *Secret Access Key 与 Access Key ID 配套使用,类似登录密码,用于签名您的访问参数,以防被篡改。 *文件存储名称
下拉选择已创建成功的 CloudFS 文件存储名称。
若还没有创建文件存储,您也可单击首页获取按钮,前往 CloudFS 控制台界面创建。详见创建文件存储。LasFS 接入方式
LasFS 接入方式,支持访问 LAS 文件系统中的文件,您可配置 LAS 相关参数,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数说明 基本配置 *数据源类型 CloudFS *接入方式 LasFS *数据源名称 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 参数配置 *Access key ID 进入火山引擎,访问控制台的密钥管理界面,复制 Access key ID 填写到此处。如果为子用户,请联系主账号获取密钥。 *Secret Access Key 与 Access Key ID 配套使用,类似登录密码,用于签名您的访问参数,以防被篡改。
4.2 新建离线任务
CloudFS 数据源测试连通性成功后,进入到数据开发界面,开始新建 CloudFS 相关通道任务。新建任务方式详见离线数据同步、流式数据同步。
任务创建成功后,您可根据实际场景,配置 CloudFS 离线读通道任务。
4.3 可视化配置 CloudFS 离线读
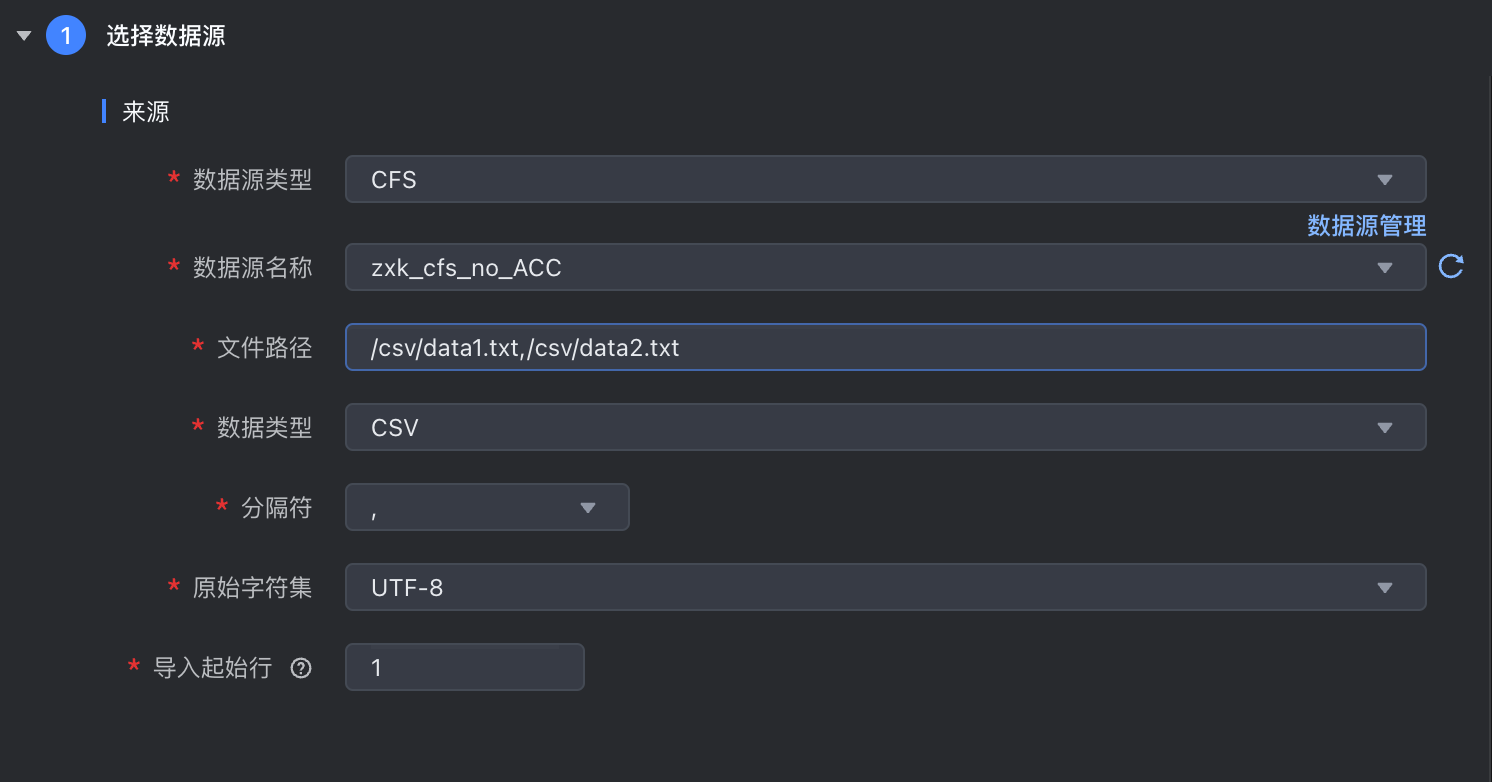
数据来源选择 CFS,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
| 参数 | 说明 |
|---|---|
| *数据源类型 | 下拉选择 CFS 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 CFS 数据源,下拉可选。 |
*数据源地址 | 填写需要采集的数据文件所在路径:
|
*数据类型 | 支持选择 json、pb、parquet、csv、txt 等几种数据类型:。
|
4.4 可视化配置 CloudFS 实时写
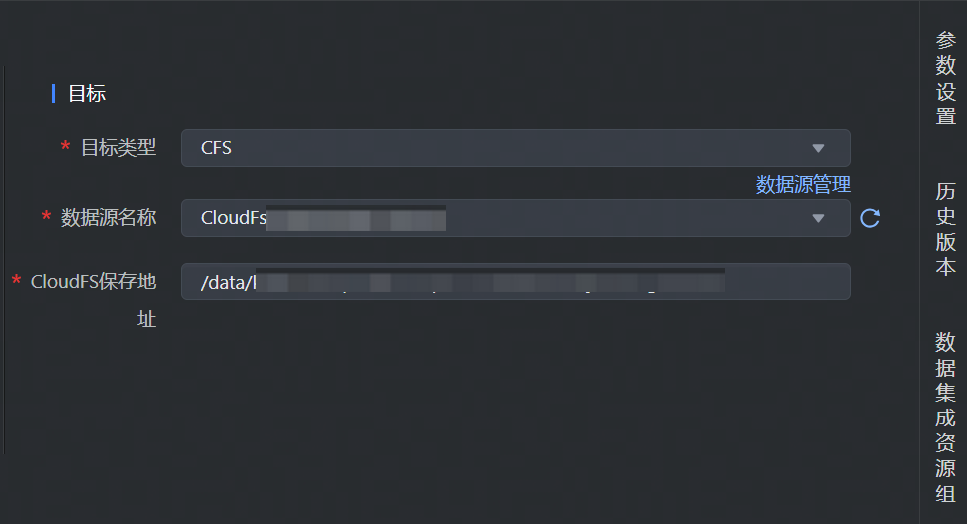
流式集成任务实时写入 CFS 数据源,数据目标类型选择 CFS,并完成以下相关参数配置:
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
| 参数 | 说明 |
|---|---|
| *目标类型 | 下拉选择 CFS 数据源类型。 |
*数据源名称 | 已在数据源管理中注册成功的 CFS 数据源,下拉可选。 |
*CloudFS/LasFS 保存地址 | 填写需要写入数据的 CloudFS/LasFS 存储路径信息。 说明 LasFS 当前仅支持两种地址路径:
|
4.5 字段映射
可视化离线读 CloudFS,数据来源和目标端配置完成后,需要指定来源和目标端的字段映射关系,根据字段映射关系,数据集成任务将源端字段中的数据,写入到目标端对应字段中。
您可通过以下三种方式操作字段映射关系:
自动添加:单击自动添加按钮,根据两端数据表信息,可以自动填充来源和目标的字段信息。
手动添加:单击手动添加按钮,可以手动编辑来源和目标的字段信息,可以逐个添加。
移动\删除字段:您也可以根据需要移动字段映射顺序或删除字段。
说明
实时 CloudFS Writer 目前上游只能承接 BMQ、RocketMQ、Kafka 和 DataSail 这四种消息队列类型数据源。这四种数据源会将消息的原始负载直接发送到 CloudFS Writer,然后由 CloudFS Writer 直接以二进制形式写入,因此不需要配置 column 字段。
4.6 DSL 任务模板配置
CloudFS 离线读和实时写均不支持 DSL 模板配置。
5 可选高级参数
5.1 CloudFS 离线读
对于可视化通道任务,高级参数可在任务开发界面:任务运行参数 > 自定义参数设置中填写,读参数需要加上 job.common.: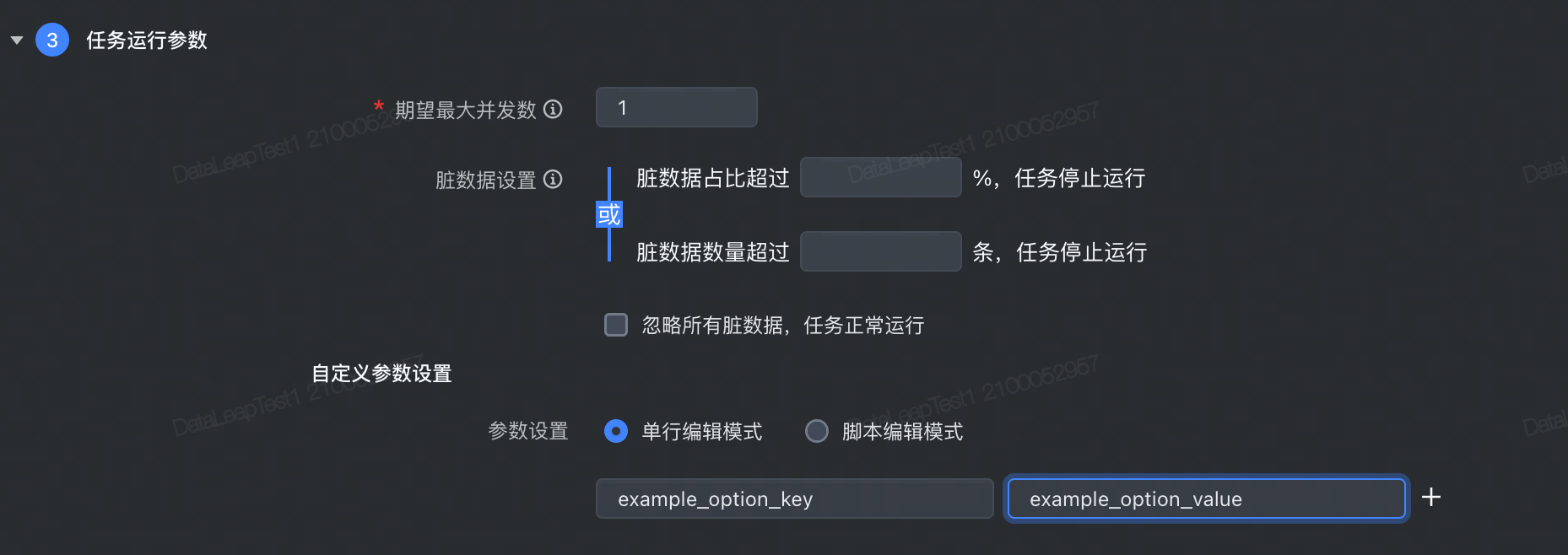
JSON 数据格式相关参数
参数 描述 默认值 job.common.case_insensitive JSON 内容解析时是否对字段 Key 大小写敏感 true job.common.support_json_path 是否支持带 .的字段名。true为支持,false 为不支持false job.common.json_serializer_features DataSail 使用 fastjson 解析 JSON 内容,用户可以通过此参数设置 JSON 解析的 features,详情参考 SerializerFeature - fastjson 1.2.83 javadoc。多个 SerializerFeature 使用逗号分隔。 无 job.common.convert_error_column_as_null 是否将类型转化失败的字段默认置为 null。 false CSV 数据格式相关参数
参数 描述 默认值 job.common.csv_escape CSV 的 escape 字符 无 job.common.csv_quote CSV 的 quote 字符 无 job.common.csv_with_null_string 将 CSV 中的这个字段值视为 null 无
5.2 CloudFS 实时写
实时写高级参数可在任务开发界面:任务运行参数 > 高级参数中,选择开启按钮后,进行填写,写参数时需要加上 job.writer. 前缀:
| 参数 | 描述 | 默认值 |
|---|---|---|
| job.writer.rolling.max_part_size | 文件切割大小,单位字节,默认10G。 注意这里是指未压缩读的数据大小, 而非 hdfs 最终文件大小 | 10737418240 |
| job.writer.hdfs.replication | hdfs 副本数 | 3 |
job.writer.hdfs.compression_codec | hdfs 压缩格式,支持以下几种:
| zstd |
job.writer.dump.directory_frequency | 写入 hdfs 文件夹的频率,支持以下参数:
| dump.directory_frequency.day |