Kafka 数据源为您提供实时读取和离线读写 Kafka 的双向通道能力,实现不同数据源与 Kafka 数据源之间进行数据传输。
本文为您介绍 DataSail 的 Kafka 数据同步的能力支持情况。
1 支持的 Kafka 版本
- 实时读、离线读写:
- 支持火山引擎 Kafka 实例和自建 Kafka 集群,Kafka 2.x 版本以上的集群连接,如 Kafka 2.2.0 版本及其以后的版本均支持读取。
- 鉴权模式支持普通鉴权和 SSL 鉴权模式。
2 使用限制
- 子账号新建数据源时,需要有项目的管理员角色,方可以进行新建数据源操作。各角色对应权限说明,详见:管理成员。
- Kafka 数据源目前支持可视化配置实时读取和离线读写 Kafka。
- 为确保同步任务使用的独享集成资源组具有 Kafka 库节点的网络访问能力,您需将独享集成资源组和 Kafka 数据库节点网络打通,详见网络连通解决方案。
- 若通过 VPC 网络访问,则独享集成资源组所在 VPC 中的 IPv4 CIDR 地址,需加入到 Kafka 访问白名单中:
- 确认集成资源组所在的 VPC:
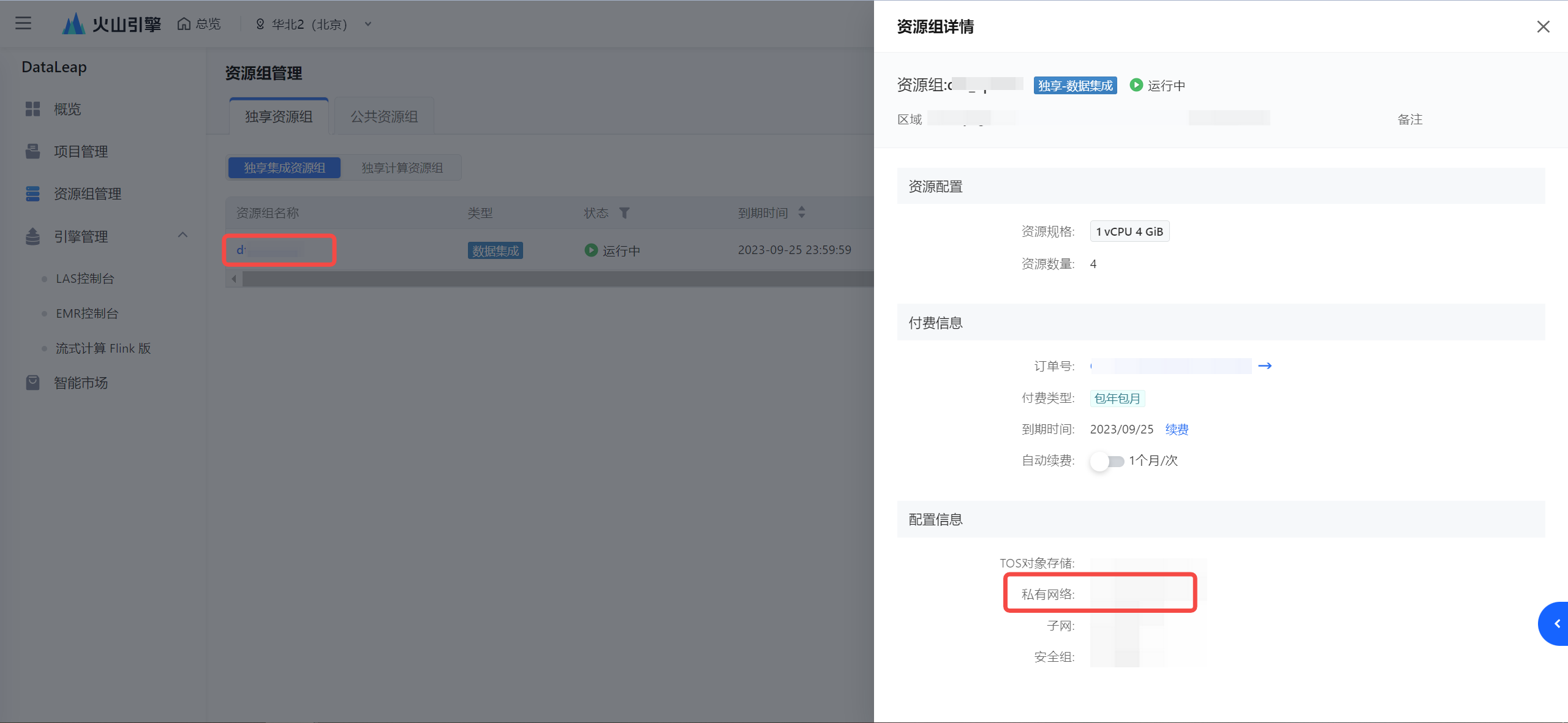
- 查看 VPC 的 IPv4 CIDR 地址:
注意
若考虑安全因素,减少 IP CIDR 的访问范围,您至少需要将集成资源组绑定的子网下的 IPv4 CIDR 地址加入到实例白名单中。
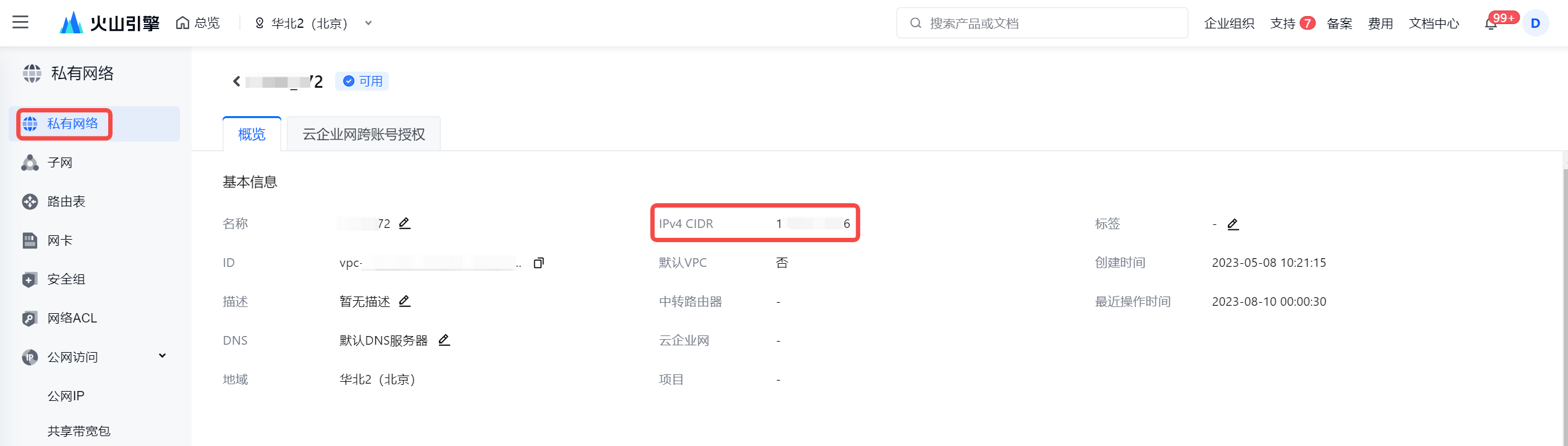
- 将获取到的 IPv4 CIDR 地址添加进 Kafka 实例白名单中。
- 若是通过公网形式访问 Kafka 实例,则您需进行以下操作:
- 独享集成资源组开通公网访问能力,操作详见开通公网。
- 并将公网 IP 地址,添加进 Kafka 实例白名单中。
3 数据源注册
新建数据源操作详见配置数据源,以下为您介绍不同接入方式的 Kafka 数据源配置相关信息:
3.1 火山引擎 Kafka 接入方式
其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|
基本配置 |
*数据源类型 | Kafka |
*接入方式 | 火山引擎 Kafka |
*数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
参数配置 |
*Kafka 实例 ID | 下拉选择已在火山引擎消息队列 Kafka 中创建的 Kafka 实例名称信息。
若您还未创建 Kafka 实例,您可前往 Kafka 实例控制台中创建,详见创建实例。 |
3.2 连接串形式接入
用连接串形式配置 Kafka 数据源,其中参数名称前带 * 的为必填参数,名称前未带 * 的为可选填参数。
参数 | 说明 |
|---|
基本配置 |
*数据源类型 | Kafka |
*接入方式 | 连接串 |
*数据源名称 | 数据源的名称,可自行设置,仅支持中文,英文,数字,“_”,100个字符以内。 |
参数配置 |
*Kafka 版本 | Kafka 版本,下拉可选。当前支持 Kafka 2.2.0 版本。 |
*Kafka 集群地址 | 启动客户端连接Kafka服务时使用。
填写格式为 ip:port 或 host:port 格式,存在多个时,可用逗号分隔。如localhost:2181,localhost:2182 |
*认证方式 | 支持 SASL_PLAINTEXT、SASL_SSL 认证方式,您也可选择 None 不认证。
选择 SASL_PLAINTEXT、SASL_SSL 认证方式时,需确认 Sasl 机制,目前支持选择 PLAIN、GSSAPI(Kerberos)、SCRAM-SHA-256 认证机制。 |
认证机制选择为 PLAIN、SCRAM-SHA-256 方式时,需配置以下用户名和密码信息: |
*用户名 | 输入有权限访问 Kafka 集群环境的用户名信息。 |
*密码 | 输入用户名对应的密码信息。 |
认证机制选择为 GSSAPI(Kerberos)方式时,需配置 Keytab 文件、conf 文件、principal、serviceName 信息: |
*Keytab 文件 | 需上传本地的 Keytab 文件,用于任务执行时进行身份验证。 |
*conf 文件 | 上传本地的 Conf 配置文件,文件参数配置协助身份认证。 |
*principal | 输入 principal 信息,用于 Kerberos 认证中标识 Kafka 服务身份。 |
*serviceName | 输入用于标识 Kafka 服务的 serviceName 名称信息, |
扩展参数 | 配置 Kafka 额外需要的扩展参数信息。
如 Kafka 数据源通过公网形式接入,且开启 SASL_SSL 认证时,可将认证证书信息配置到扩展参数中,固定配置参数如下: 说明 开启 SASL_SSL 后,还需在任务运行高级参数中配置 job.common.skip_dump_parse:true。详见7.2 高级参数列表。 {
"ssl.truststore.certificates":"QmFnIEF0dHJpYnV0ZXMKICAgIGZyaWVuZGx5TmFtZTogY2Fyb290CiAgICAyLjE2Ljg0MC4xLjExMzg5NC43NDY4NzUuMS4xOiA8VW5zdXBwb3J0ZWQgdGFnIDY+CnN1YmplY3Q9L0M9Q04vU1Q9QmVpamluZy9MPUJlaWppbmcvTz1BbGliYWJhL0NOPUFsaUthZmthCmlzc3Vlcj0vQz1DTi9TVD1CZWlqaW5nL0w9QmVpamluZy9PPUFsaWJhYmEvQ049QWxpS2Fma2EKLS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUZLakNDQXhJQ0NRQ2RrVitpTC9jQlR6QU5CZ2txaGtpRzl3MEJBUXNGQURCV01Rc3dDUVlEVlFRR0V3SkQKVGpFUU1BNEdBMVVFQ0F3SFFtVnBhbWx1WnpFUU1BNEdBMVVFQnd3SFFtVnBhbWx1WnpFUU1BNEdBMVVFQ2d3SApRV3hwWW1GaVlURVJNQThHQTFVRUF3d0lRV3hwUzJGbWEyRXdJQmNOTWpJd05URXhNVEF6T1RNeFdoZ1BNakV5Ck1qQTBNVGN4TURNNU16RmFNRll4Q3pBSkJnTlZCQVlUQWtOT01SQXdEZ1lEVlFRSURBZENaV2xxYVc1bk1SQXcKRGdZRFZRUUhEQWRDWldscWFXNW5NUkF3RGdZRFZRUUtEQWRCYkdsaVlXSmhNUkV3RHdZRFZRUUREQWhCYkdsTApZV1pyWVRDQ0FpSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnSVBBRENDQWdvQ2dnSUJBTDMxNWFwRVJjcEFrREFCClNZNEEyYkdyUlpPNENYajRudnFid0VaNTBmMUhsd0FCanpVTUtYRVM3bFdyT3dybnFaalNJZ201d29xdStQcjQKc1doS0ZITjE5U1NuamVLaWxRb0w4U3pNazBwMjJRSksyc3FLUk11SHRvQnRMNnVPVCt5a1YxNklFZzBmWTJVdQovb1gvc0YyTEFWQ0lsMUlHYzJIVktVcjU2YzAvbU02VjZVcjVTdW03Y3RLazJkbTZZUzVnd0RPWGNxQWFaaHdkCmpWenFMRVc4aG1zTVM3bitkMi9OSUpNcVh2VEhEUlE3NHhoUjl0TjJ3OTJrZUVCR09Rb01HL1F3MFJ2UzFhUWkKUktwTnB2Q0U3ejU0M2lzdFl1RmJGamk2NDZ1NmtSQ3I3STJpNFJ3VjBxWFZNMWRqY1MrUHlzVXNJWDRtRWpkUApLcTBGcHR6c2lpM2FlVEZ1TnN3T2xvNUdpZUUzcHNWb3ltSVAySFdkNnhtbG1GYVgzWjhOZDRQeEE2aDB1UklZCnRSYkxrSHc4V2ZPQWw0ZFh4V1FGa2J2TllOTFJCNXhaVVlqbTNDQStaaFlmSlJ0TmxQYTIyNDdQc25idXA2Q0gKazNEUCthRXhkTG1idHl1Z1pPL2xOcWk5V01aMHFMRkdYWkR6OGFzdGdKUEdLaUNqaWhjY3BQMWNkekdsQ3pHdQppRTZTMjVKRUJ1WFBsNHdnNEdYTnVDZzZ0Y0VLTDJxaW52YnJDaW1yaWxXdUZhakJoN2hSSDBkZ2toZXp3NnhVCiszKytaQ2ViRUpPWFo4YnluM3YvZ215eDJQRG5LbEJQY1hDeTIzbmFkYmlYL3pwTnZOdkNxQWV3YWptOUFsV1kKZlhiQ2w1VGtVbnlNUHNoMHJ3V2VlUllSMmtNM0FnTUJBQUV3RFFZSktvWklodmNOQVFFTEJRQURnZ0lCQUR4VwpZSm9XaDlEVnR3RkdwOFRPcmxiWjdrd2ZsS0Z2OEhldzRTWDAwSzVHd0tnbW5uM2ZqZFIwRjhyWjJhci9CcWRECnpSNjNzdjlMR2pNY2k5TldBcVBxTjVNeUtCOTdLckZWNm5IemNZTFJtVCtsdG9scWNmcDVNZUdDcWthN1pURUwKdDY1OHh4YVNYTkVZOUhHSFlza0l1N21XZDQxS0FqMFJMUkpuRUVPckNTWnpmcHpHNExkRDZKMHU3d3B5SlNZTApqR3hpMnhzd3Q1QzB4NzkwTFMvSm1GcTY1Yy92emZBVGpibXU2WFNPM1V2dHNBRHBqMHBIM0ZKRmhMem9UNjdvCk5yVWVGRUhyenNNYzdKZW5ZbVBJWW1FYjR4WGxmY3RqQ3pMYWlORzN1OHVLd1hHQmsvb2FnQXdYQ3NJOEkwcFIKd3RXL1FlZFh4bEZ0VWZBVFJabkkvZUxxdko1Y1E2YVhnL0d5SnRBditjY0ZmMDA0SzFFUjAwRUNlNzM4V05YbQorNk5Oa2hONWdQaHdzZm9EaHErYTdabXZqOSt4L1hEalNScVo4aitYSU1pOVpRalR3VUFnOUptbmh5UjRlSlhuCm9RQXhHYzNpaTk4WW9Bc3BLWkdSWDZMb1JmWWJORTNUWEpzU3pHdzczK1BxUzF5NzR4Tk5tTXgyWFg2SVYvNTMKSXM1bUE4ZmxpNkJJRUtrQWdFNlBuMHQ2djVFUDZoYVZGODR2SmF6WVJJbFlmbFIybWk4cDhkVTZrb2hpQzc5QwplNHNlUlRUWmd5WFUrNWRnRklYcWFndWIyQTc5dFJ0UEFyKzRYaTg0anpZODRjZVV3cVgyZnhSd2tmYVVVSmI4CkhoMnErUCtWSmVLNTBCODNEWjR1aStXTkpiQWFBYmNMTXNuL2lkWDMKLS0tLS1FTkQgQ0VSVElGSUNBVEUtLS0tLQpCYWcgQXR0cmlidXRlcwogICAgZnJpZW5kbHlOYW1lOiBjYXJvb3QyCiAgICAyLjE2Ljg0MC4xLjExMzg5NC43NDY4NzUuMS4xOiA8VW5zdXBwb3J0ZWQgdGFnIDY+CnN1YmplY3Q9L0M9Q04vU1Q9SFovTD1IWi9PPUFCL0NOPUthZmthQ0EvZW1haWxBZGRyZXNzPXpoZW5kb25nbGl1Lmx6ZEBhbGliYWJhLmNvbQppc3N1ZXI9L0M9Q04vU1Q9SFovTD1IWi9PPUFCL0NOPUthZmthQ0EvZW1haWxBZGRyZXNzPXpoZW5kb25nbGl1Lmx6ZEBhbGliYWJhLmNvbQotLS0tLUJFR0lOIENFUlRJRklDQVRFLS0tLS0KTUlJRFBEQ0NBcVdnQXdJQkFnSUpBTVJzYjBETE0xZnNNQTBHQ1NxR1NJYjNEUUVCQlFVQU1ISXhDekFKQmdOVgpCQVlUQWtOT01Rc3dDUVlEVlFRSUV3SklXakVMTUFrR0ExVUVCeE1DU0ZveEN6QUpCZ05WQkFvVEFrRkNNUkF3CkRnWURWUVFERXdkTFlXWnJZVU5CTVNvd0tBWUpLb1pJaHZjTkFRa0JGaHQ2YUdWdVpHOXVaMnhwZFM1c2VtUkEKWVd4cFltRmlZUzVqYjIwd0lCY05NVGN3TXpBNU1USTFNRFV5V2hnUE1qRXdNVEF5TVRjeE1qVXdOVEphTUhJeApDekFKQmdOVkJBWVRBa05PTVFzd0NRWURWUVFJRXdKSVdqRUxNQWtHQTFVRUJ4TUNTRm94Q3pBSkJnTlZCQW9UCkFrRkNNUkF3RGdZRFZRUURFd2RMWVdacllVTkJNU293S0FZSktvWklodmNOQVFrQkZodDZhR1Z1Wkc5dVoyeHAKZFM1c2VtUkFZV3hwWW1GaVlTNWpiMjB3Z1o4d0RRWUpLb1pJaHZjTkFRRUJCUUFEZ1kwQU1JR0pBb0dCQUxaVgpiYklPMVVMUVFOODUzQlRCZ1JmUGlSSmFBT1dmMzh1OEdDMFROcC9FOXF0STg4QSs3OXl3QVAxN2s1V1lKN1hTCndYTU9KM2gxcWtRVDJUWUpWZXRaNkU2OUNVSnE0QnNPdk5sTlJ2bW5XNmVGeW1oNVFac0V6Mk1Ub294SmpWakMKSlFQbEkyWFJEaklyVFZZRVFXVUR4ajJKaEI4VlZQRWVkKzZ1NEtRVkFnTUJBQUdqZ2Rjd2dkUXdIUVlEVlIwTwpCQllFRkhGbE9vaXFReFhhblZpMkdVb0RpS0REMzN1ak1JR2tCZ05WSFNNRWdad3dnWm1BRkhGbE9vaXFReFhhCm5WaTJHVW9EaUtERDMzdWpvWGFrZERCeU1Rc3dDUVlEVlFRR0V3SkRUakVMTUFrR0ExVUVDQk1DU0ZveEN6QUoKQmdOVkJBY1RBa2hhTVFzd0NRWURWUVFLRXdKQlFqRVFNQTRHQTFVRUF4TUhTMkZtYTJGRFFURXFNQ2dHQ1NxRwpTSWIzRFFFSkFSWWJlbWhsYm1SdmJtZHNhWFV1Ykhwa1FHRnNhV0poWW1FdVkyOXRnZ2tBeEd4dlFNc3pWK3d3CkRBWURWUjBUQkFVd0F3RUIvekFOQmdrcWhraUc5dzBCQVFVRkFBT0JnUUJUU3owNHAwQUpYS2wzMHNIdytVTS8KL2sxakdGSnpJNXAwWjZsMkp6S1FZUFAzUGZFL2JpRTgvcm1pR1lFZW5OcVdOeTFaU25pRUh3YThML1V4OThjaQo0SDBaU3BVck1vMis2YmZ1Tlc5WDM1Q0ZQcDV2WVlKcWZ0aWxKQktJSlgzQzNKMXJ1T3VCUjI4VXhFNDJ4eDRLCnBRNzB3Q2hOaTkxNGM0QitTeGtHVWc9PQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==",
"ssl.truststore.type":"PEM",
"ssl.endpoint.identification.algorithm":""
}
|
3.3 测试连通性
参数项填写完整后,勾选已绑定的独享集成资源组,并单击上方测试按钮,执行测试连通性。同时,您可展开资源组 ID,查看该资源组所属 VPC 下各子网的网络连通情况,您需确保各子网均能与数据源连通,避免因子网连通问题导致任务执行异常。
若当前是多环境项目时,您需进行资源组的生产环境测试、开发环境测试连通性,确保不同环境数据源使用的资源组,网络均能正常连通。
说明
- 数据源与独享集成资源组网络需保证能互通,详见网络连通解决方案。
- 多环境项目中,生产资源组与开发资源组可自定义配置映射关系,您可前往项目控制台 > 环境映射中进行配置。操作详见环境映射。
连通性测试成功后,单击确定按钮,在弹窗中完成可用资源组的选择后,便可完成新增。
4 后续步骤
数据源创建完成后,您可以进行后续的 Kafka 集成任务配置,详见:配置 Kafka 任务。






 大数据研发治理套件
大数据研发治理套件
