边缘智能
边缘智能






- 文档首页
 边缘智能边缘大模型网关API 调用指南自部署模型使用 Realtime API 调用自部署 ASR 模型
边缘智能边缘大模型网关API 调用指南自部署模型使用 Realtime API 调用自部署 ASR 模型

本文档介绍如何通过火山引擎边缘大模型网关,使用有状态、基于事件的 Realtime API 来调用您自部署的语音识别(ASR)模型。
概述
Realtime API 通过 WebSocket 协议进行通信,适用于需要低延迟、实时流式传输的场景。它允许客户端与服务端建立持久连接,并在此连接上进行双向的事件驱动通信,从而实现语音识别。
建连参数
与 Realtime API 建立 WebSocket 连接时,需要指定以下参数:
URL:
wss://ai-gateway.vei.volces.com/v1/realtime查询参数:
?model=<your_model_name>请求头 (Header):
Authorization: Bearer $YOUR_API_KEY
快速开始
本节将通过一个完整的 Python 示例,引导您完成一次 API 调用,包括建立连接、发送音频数据以及接收识别结果。
准备工作
在开始之前,请确保您已获取以下信息:
模型调用名称 (
<your_model_name>):在 大模型管理 页面获取。API 密钥 (
$YOUR_API_KEY):在 网关访问密钥 页面获取。说明
请确保该密钥已绑定您的自部署 ASR 模型。关于如何绑定自部署 ASR 模型,请参见 调用自部署模型。
步骤 1:编写调用代码
创建一个名为
requirements.txt的文件,并填入以下依赖:numpy soundfile scipy websockets==12.0 openai创建一个名为
ASR_client.py的文件,并将以下示例代码粘贴进去。说明
- 注意将代码中的
<your_model_name>和$YOUR_API_KEY替换为实际值;将<your_audio_file>替换成输入音频文件的路径。可以使用以下音频文件进行测试:

- 以下示例代码仅用于测试,请勿用于生产环境。
# prerequisites # pip install websockets==12.0 numpy soundfile scipy import asyncio import base64 import json import numpy as np import soundfile as sf from scipy.signal import resample import websockets SAMPLE_RATE = 16000 # your_sample_rate def resample_audio(audio_data, original_sample_rate, target_sample_rate): number_of_samples = round(len(audio_data) * float(target_sample_rate) / original_sample_rate) resampled_audio = resample(audio_data, number_of_samples) return resampled_audio.astype(np.int16) async def send_audio(client, audio_file_path: str): duration_ms = 100 samples_per_chunk = SAMPLE_RATE * (duration_ms / 1000) bytes_per_sample = 2 bytes_per_chunk = int(samples_per_chunk * bytes_per_sample) extra_params = {} if audio_file_path.endswith(".raw"): extra_params = { "samplerate": SAMPLE_RATE, "channels": 1, "subtype": "PCM_16", } audio_data, original_sample_rate = sf.read(audio_file_path, dtype="int16", **extra_params) if original_sample_rate != SAMPLE_RATE: audio_data = resample_audio(audio_data, original_sample_rate, SAMPLE_RATE) audio_bytes = audio_data.tobytes() for i in range(0, len(audio_bytes), bytes_per_chunk): await asyncio.sleep((duration_ms - 20) / 1000) chunk = audio_bytes[i: i + bytes_per_chunk] base64_audio = base64.b64encode(chunk).decode("utf-8") append_event = { "type": "input_audio_buffer.append", "audio": base64_audio } await client.send(json.dumps(append_event)) print("send complete") commit_event = { "type": "input_audio_buffer.commit" } await client.send(json.dumps(commit_event)) async def receive_messages(client): while not client.closed: message = await client.recv() print(message) event = json.loads(message) if event.get("type") == "conversation.item.input_audio_transcription.completed": return def get_session_update_msg(): config = { "input_audio_format": "pcm", "input_audio_sample_rate": SAMPLE_RATE, "input_audio_bits": 16, "input_audio_channel": 1, "result_type": 0, "turn_detection": { "type": "server_vad", "threshold": 0.5, "prefix_padding_ms": 300, "silence_duration_ms": 300, } } event = { "type": "transcription_session.update", "session": config } return json.dumps(event) async def with_openai(audio_file_path: str): key = "$YOUR_API_KEY" ws_url = "wss://ai-gateway.vei.volces.com/v1/realtime?model=<your_model_name>" headers = { "Authorization": f"Bearer {key}", } async with websockets.connect(ws_url, ping_interval=None, extra_headers=headers) as client: session_msg = get_session_update_msg() await client.send(session_msg) await asyncio.gather(send_audio(client, audio_file_path), receive_messages(client)) if __name__ == "__main__": file_path = "<your_audio_file>" asyncio.run(with_openai(file_path))- 注意将代码中的
步骤 2:安装依赖并运行
打开终端,运行以下命令安装所需的 Python 库:
pip install -r requirements.txt执行脚本:
python3 ASR_client.py
运行成功后,您将在终端看到详细的日志输出,包括连接状态、发送的事件以及从服务端接收到的识别结果。
API 参考
Realtime API 的交互是基于事件的。客户端和服务端通过交换一系列 JSON 格式的事件来完成一次完整的语音识别任务。
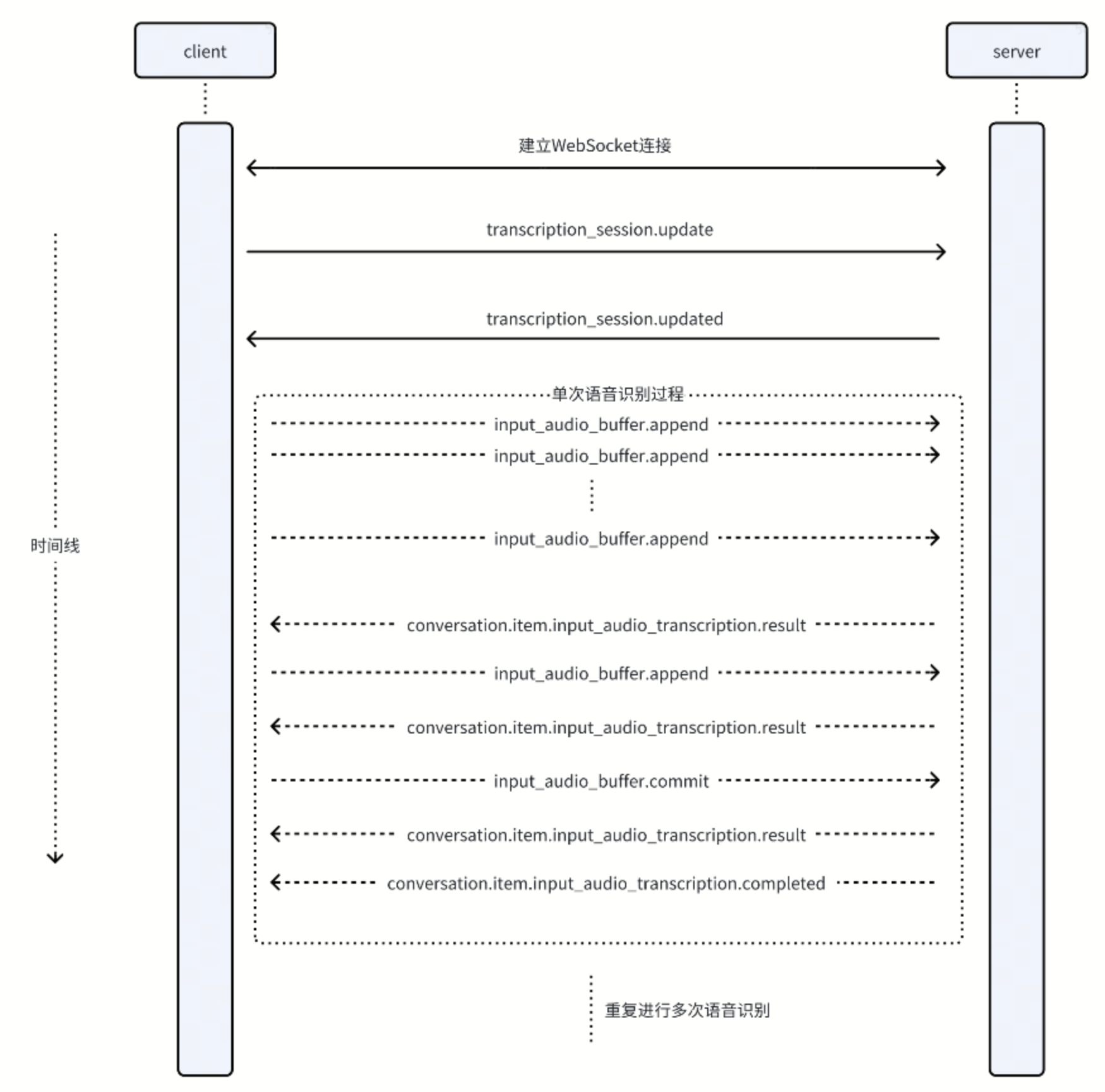
事件列表
| 通信方向 | 事件名称 | 说明 |
|---|---|---|
| 客户端 → 服务端 | 会话初始化 - transcription_session.update | 在连接建立后发送,用于配置 ASR 会话参数。 |
| 语音上报 - input_audio_buffer.append | 将 Base64 编码的音频数据块发送到服务端。 | |
| 上报完成 - input_audio_buffer.commit | 通知服务端,客户端已完成当前轮次的音频数据发送。 | |
| 服务端 → 客户端 | 配置确认 - transcription_session.updated | 确认服务端的会话配置已更新。 |
| 增量结果输出 - conversation.item.input_audio_transcription.delta | 实时返回识别过程中的增量结果。 | |
| 全量结果输出 - conversation.item.input_audio_transcription.result | 实时返回识别过程中的全量结果。 | |
| 完整结果输出 - conversation.item.input_audio_transcription.completed | 返回当前轮次音频的最终、完整识别结果。 |
客户端事件详解
会话初始化 - transcription_session.update
客户端在建立连接后,必须首先发送此事件来配置 ASR 会话。它定义了音频输入的格式、期望的返回结果类型以及语音活动检测(VAD)等行为。
参数:
session(object)input_audio_format(string)音频格式。例如:
pcm。input_audio_codec(string)音频编码。例如:
raw。input_audio_sample_rate(integer)音频采样率(Hz)。例如:
16000。input_audio_bits(integer)采样位深。例如:
16。input_audio_channel(integer)音频通道数。例如:
1。result_type(integer)ASR 结果的输出模式。
0表示全量输出 (.result事件),1表示增量输出 (.delta事件)。默认值为0。如果您的模型仅支持全量输出,务必将
result_type设置为0,网关将透传模型识别结果。如果您的模型支持增量输出:
当
result_type设置为0时,网关会将增量结果聚合成全量返回。当
result_type设置为1时,网关将透传模型识别结果。
turn_detection(object)语音活动检测(VAD)配置,用于判断一句话的结束。
type(string)VAD 模式。取值包括:
server_vad_text_mode: 由网关根据 ASR 模型返回结果的间隔来判断语音结束。"turn_detection": { "type": "server_vad_text_mode", "text_interval": 300, //判断识别结束的时间间隔(单位ms) }server_vad: 由 ASR 模型自身进行 VAD 处理。如果不传递 ASR 相关参数或者参数值为 null,那么网关会传递默认值。默认值示例如下。注意
如果 ASR 模型不支持 VAD。请勿选择该方式,否则会返回错误。
"turn_detection": { "type": "server_vad", "threshold": 0.5, "prefix_padding_ms": 300, "silence_duration_ms": 500 }priority_order_mode: 客户端上报多种 VAD 模式,由网关决定采取哪种模式(使用的模式通过transcription_session.updated事件返回)。"turn_detection": { "type": "priority_order_mode", "modes": [ { "type": "server_vad", "threshold": 0.5, "prefix_padding_ms": 300, "silence_duration_ms": 500 }, { "type": "server_vad_text_mode", "text_interval": 300 } ] }如果此字段为
null,则表示由客户端控制语音结束(通过发送input_audio_buffer.commit事件)。
示例:
{ "type": "transcription_session.update", "session": { "input_audio_format": "pcm", "input_audio_codec": "raw", "input_audio_sample_rate": 16000, "input_audio_bits": 16, "input_audio_channel": 1, "result_type": 0, "extra_data": {}, "turn_detection": { "type": "server_vad_text_mode", "text_interval": 300, } } }
语音上报 - input_audio_buffer.append
用于将音频数据块流式传输到服务端。音频数据需要经过 Base64 编码。
参数:
audio(string)Base64 编码后的原始音频字节流。
示例:
{ "event_id": "event_wQp5vyn4VloVTOcrQS6bo", "type": "input_audio_buffer.append", "item_id": "item_ezC2f0aiYLtsTILllMIXe", "audio": "xxxxxx" }
上报完成 - input_audio_buffer.commit
当客户端 VAD 判断一句话结束后,发送此事件通知服务端当前轮次的音频已全部发送完毕。服务端在收到此事件后,会开始处理并返回最终识别结果。如果 VAD 由服务端处理,则客户端无需发送此事件。
参数:无
示例:
{ "event_id": "event_wQp5vyn4VloVTOcrQS6bo", "type": "input_audio_buffer.commit", "item_id": "item_ezC2f0aiYLtsTILllMIXe" }
服务端事件详解
配置确认 - transcription_session.updated
服务端在收到客户端的 transcription_session.update 请求后,会返回此事件,以确认会话配置已成功应用。事件内容将包含当前生效的完整会话配置。
参数:
session(object)包含所有已应用的会话参数,结构与客户端事件中的
session对象类似。
示例:
{ "event_id": "event_5678", "type": "transcription_session.updated", "session": { "id": "sess_001", "object": "realtime.transcription_session", "input_audio_format": "pcm", "input_audio_codec": "raw", "input_audio_sample_rate": 16000, "input_audio_bits": 16, "input_audio_channel": 1, "result_type": 0, "turn_detection": { "type": "server_vad_text_mode", "text_interval": 300, } } }
增量结果输出 - conversation.item.input_audio_transcription.delta
如果 result_type 配置为 1 (增量输出),服务端会通过此事件实时返回识别过程中的增量文本结果。
说明
适用于采用增量输出模式的模型,如 gpt-4o-transcribe。
参数:
delta(string)当前识别出的新增文本片段。
start(float)该文本片段在音频流中的开始时间(秒)。
end(float)该文本片段在音频流中的结束时间(秒)。
示例:
{ "type": "conversation.item.input_audio_transcription.delta", "event_id": "event_001", "item_id": "item_001", "content_index": 0, "delta": "Hello", "start": 0.0, "end": 3.319999933242798 }
全量结果输出 - conversation.item.input_audio_transcription.result
如果 result_type 配置为 0 (全量输出),服务端会通过此事件实时返回当前已识别到的完整语句。每次返回的都是当前句子的全量内容。
说明
适用于采用实时输出全量结果的模型,如方舟大模型语音识别。
参数:
transcript(string)当前识别出的完整文本。
words(array)包含每个词详细信息(如起止时间)的对象数组。
示例:
{ "type": "conversation.item.input_audio_transcription.result", "event_id": "event_001", "item_id": "item_001", "transcript": "Hello, how?", "words": [ { "start": 0.0, "end": 1.319999933242798, "word": "Hello" }, ... ] }
{ "type": "conversation.item.input_audio_transcription.result", "event_id": "event_002", "item_id": "item_001", "transcript": "Hello, how are you?", "words": [ { "start": 0.0, "end": 1.319999933242798, "word": "Hello" }, ... ] }
完整结果输出 - conversation.item.input_audio_transcription.completed
在服务端判断一句话识别结束后(通过 VAD 或收到 commit 事件),会发送此事件,标志着一轮识别任务的完成。该事件包含最终的、最准确的识别结果。
参数:
transcript(string)最终的完整识别文本。
words(array)包含最终结果中每个词详细信息的对象数组。
示例:
{ "event_id": "event_2122", "type": "conversation.item.input_audio_transcription.completed", "item_id": "msg_003", "transcript": "Hello, how are you?", "words": [ { "start": 0.0, "end": 1.319999933242798, "word": "Hello" }, ... ] }