边缘智能
边缘智能






- 文档首页
 边缘智能边缘智能平台最佳实践使用时序数据流
边缘智能边缘智能平台最佳实践使用时序数据流

基于 eKuiper 框架,边缘智能提供了在边缘侧对时序数据进行处理的能力。本教程将指导您使用时序数据流功能。
背景信息
时序数据流可以获取 IoT 设备的时序数据,让您能够通过类 SQL 语句进行数据的清洗、整理和分析,然后将最终的结果推送至消息中间件或其他设备。
- 时序数据流允许在边缘层面进行时序数据分析,而不是将所有 IoT 数据全部发送回云端。通过在源头过滤、聚合和分析数据,时序数据流有助于有效地利用带宽,以便您快速做出决策。
- 时序数据流同时也可以与视频数据流进行整合使用,即将从视频数据流得到的元数据作为时序数据流的输入,在边缘侧进一步处理。
场景描述
在这篇教程中,我们将会演示如何从设备读取数据,将数据输入到时序数据流进行处理,然后将处理后的结果写入其他设备。
具体来说,本教程模拟了以下情境:
- 在节点上接入一个带有温度(temperature)属性的虚拟输入设备。
- 在节点上部署时序数据流。时序数据流读取输入设备的温度数据,并分析相邻时间段的温度是否有大的变动(如在 5 秒内的温度差超过 0.5℃)。
- 在节点上接入一个只有结果(result)属性的虚拟输出设备。如果温度有大的变动,输出设备的结果会被设定为特定的数值。
前提条件
要使用本教程,您必须有一个边缘智能节点(一体机),并将节点绑定到边缘智能的某个空间。相关操作,请参见快速入门。
准备工作
在本教程中,我们使用边缘智能的官方虚拟驱动来模拟虚拟的输入和输出设备。如果您使用真实的设备,可根据设备的实际属性进行配置。
准备虚拟输入设备
在这部分,我们将创建一个虚拟的输入设备。输入设备有温度(temperature)属性。这个属性的数据随机生成,数据的生成时间间隔是 1 秒。
登录边缘智能控制台。
在左侧导航栏,从 我的空间 下拉列表选择一个空间。
在左侧导航栏,选择 设备管理 > 设备模板。
创建设备模板。
- 单击 创建设备模板。
- 在 创建设备模板 对话框,配置以下参数,然后单击 确定。
- 名称:设置为 input-device。
- 类型:选择 其他设备。
单击上一步创建的设备模板的名称。
您将进入设备模板的详情页面。定义物模型。
单击 物模型定义 页签。
单击 编辑。
在 默认模块 下,添加以下自定义功能。
功能类型
功能名称
标识符
读写类型
数据类型
描述
属性
temperature
temperature
只读
double
模拟温度数据
单击 确定。
在 发布新版本 对话框,按要求设置一个 版本号,然后单击 确定。
完成以上操作后,您将获得如下图所示的物模型。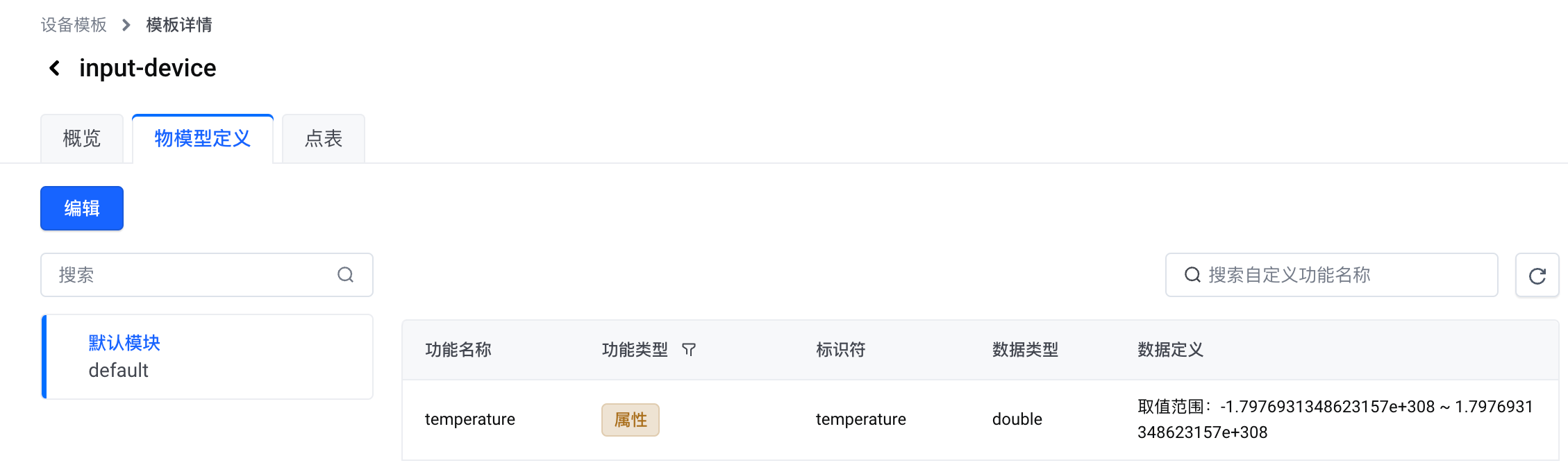
创建点表。
- 单击 点表 页签。
- 单击 创建点表。
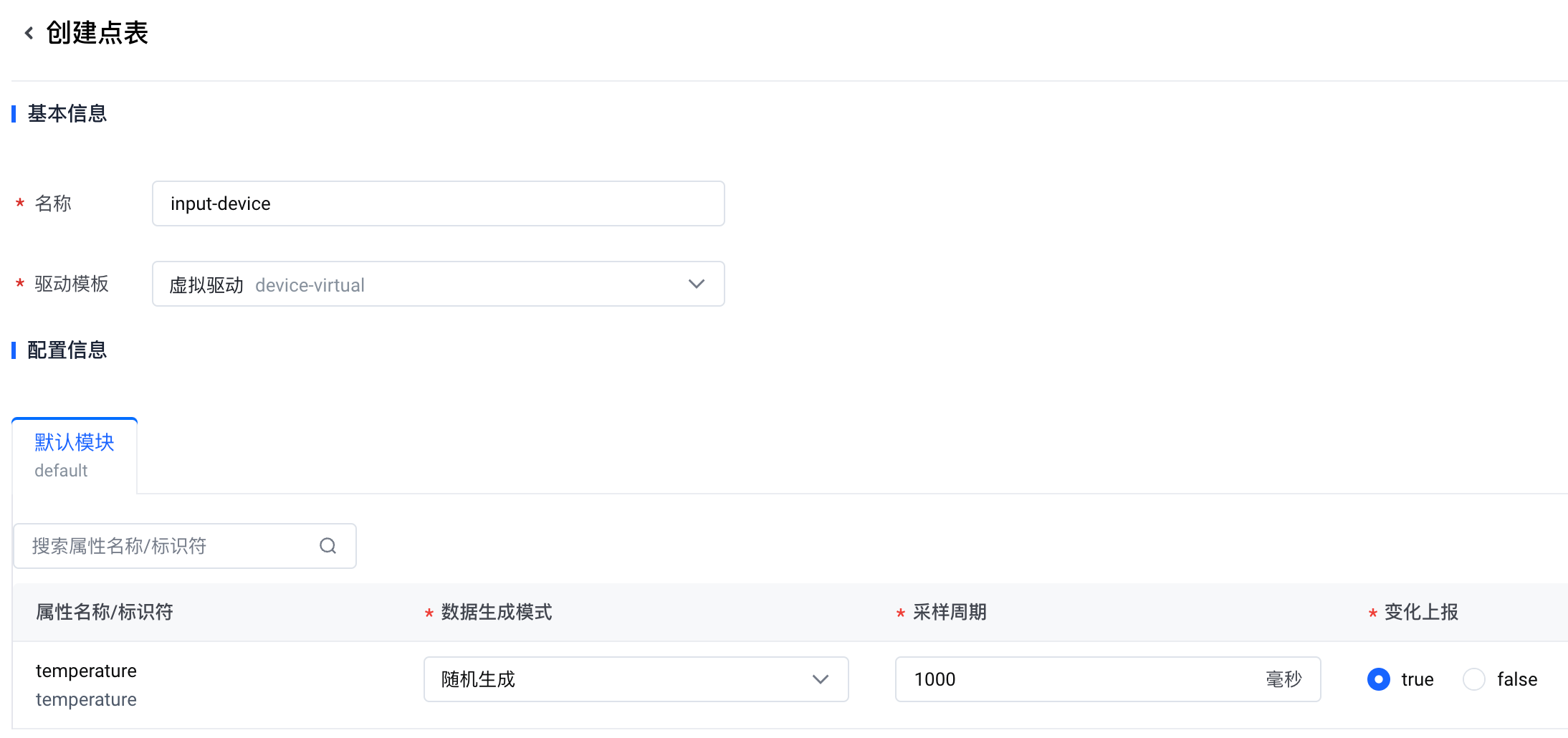
- 在 创建点表 页面,配置以下参数,然后单击 确认。
- 名称:设置为 input-device。
- 驱动模板:选择 官方驱动 > 虚拟驱动。
- temperature 属性:
- 数据生成方式:选择 随机生成。(该设置表示随机生成数据。如果您使用真实的 Modbus 设备,请将该参数设置为 无。)
- 采样周期:设置为 1000 毫秒。(该设置表示每秒采集一次数据。)
- 变化上报:选中 true。
将设备接入节点。
在左侧导航栏,单击 节点。
在节点列表,找到要使用的节点,单击节点的名称。
单击 设备接入 页签。
如果您还没有在节点上部署虚拟驱动,按照页面上的提示,在节点上部署 虚拟驱动。
部署时选择最新的驱动版本。
在 驱动实例 列表选中 虚拟驱动,然后单击 添加设备。
在 添加设备 面板,配置以下参数,然后单击 确定。
- 名称:设置为 input-device-1。
- 设备模板:选择 input-device。
- 子协议类型:选择 other。
- 点表:选择 input-device。
完成以上操作后,设备实例列表将出现新添加的虚拟输入设备。添加完成后,虚拟输入设备的状态是 未激活。数分钟后,设备将自动激活,设备的状态会变为 在线。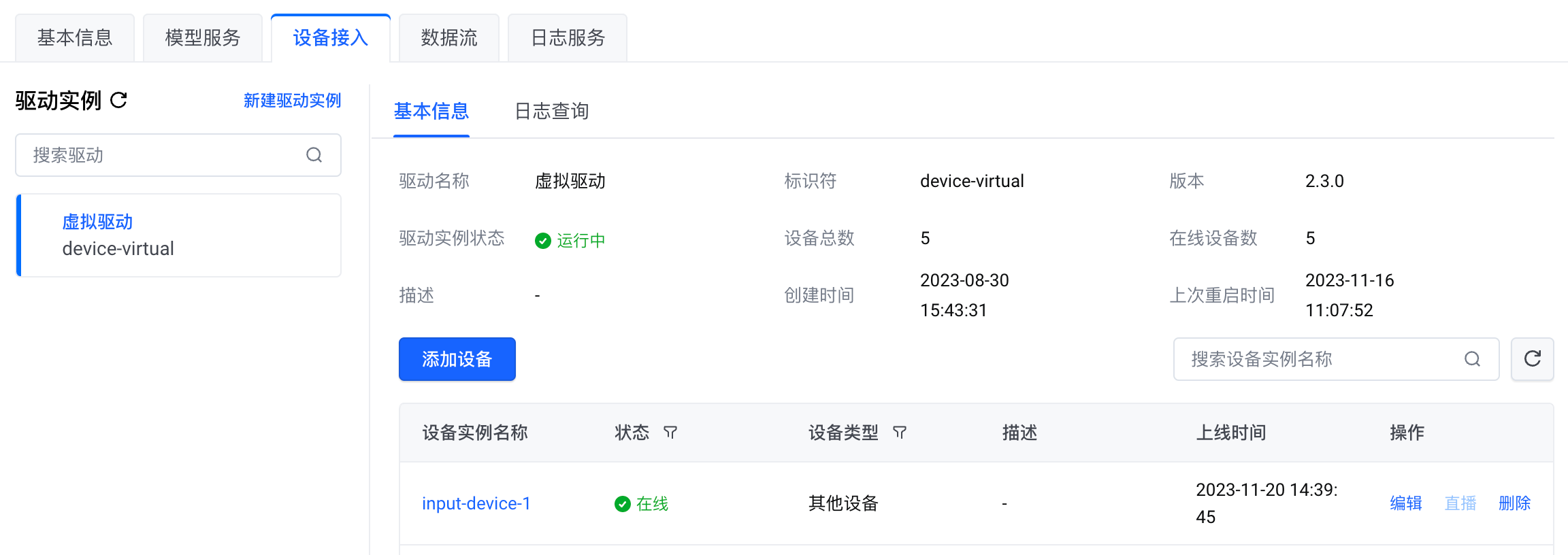
准备虚拟输出设备
在这部分,我们将创建一个虚拟的输出设备。输出设备有结果(result)属性。这个属性的数据由时序数据流写入。如果时序数据流发现输入设备的温度数据发生突变(如在 5 秒内的温度差超过 0.5℃),则将 result 的值设置为 1。
准备虚拟输出设备的步骤与准备虚拟输入设备类似,在这里不再详细描述。这里仅罗列关键的配置。具体步骤,请参见准备虚拟输入设备。
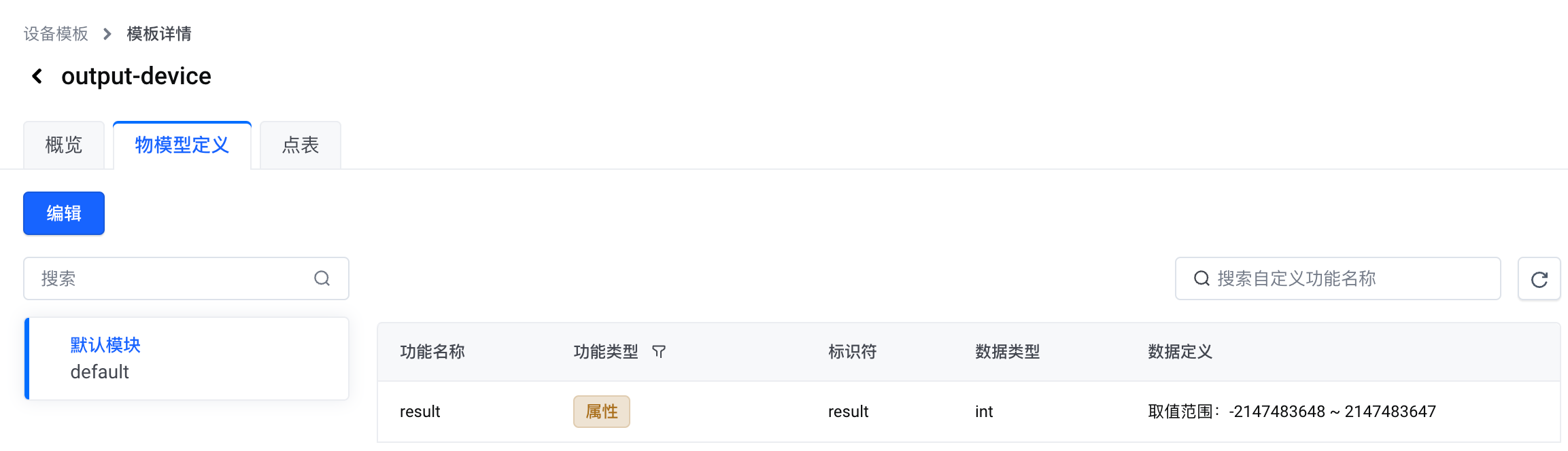
创建设备模板。命名为 output-device。
定义物模型。在 默认模块 下添加以下自定义功能。
功能类型
功能名称
标识符
读写类型
数据类型
描述
属性
result
result
读写
int
接收输出数据
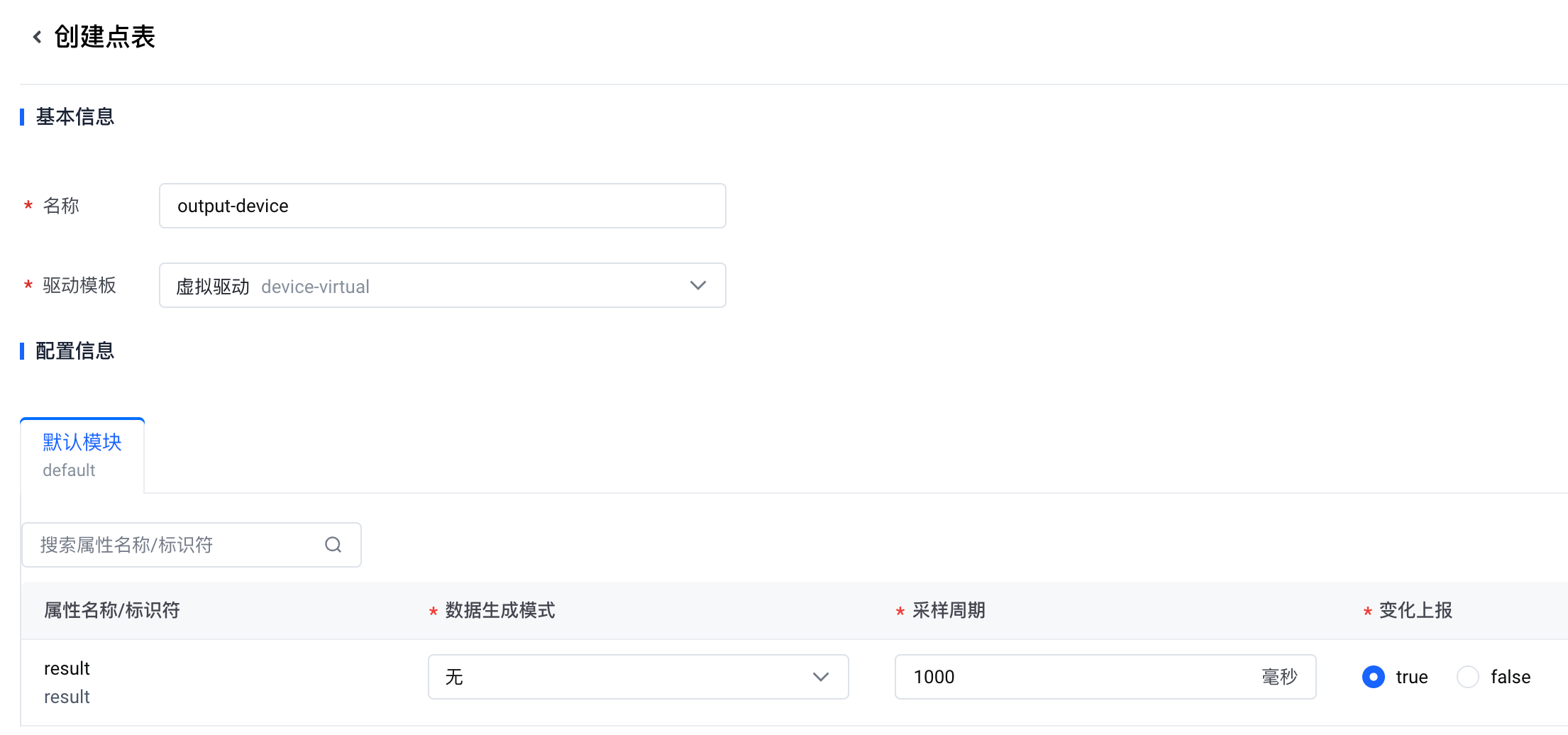
创建点表。
- 驱动模板:选择 虚拟驱动。
- result 属性:
- 数据生成模式:选择 无。(这里无需随机生成数据。因为输出设备的数据由时序数据流写入。)
- 采样周期:设置为 1000 毫秒。
- 变化上报:选择 true。
添加输出设备。命名为 output-device-1。
输出设备的状态是 未激活,这是因为设备与节点之间还没有发生通信。一旦设备与节点之间发生通信,设备将会自动激活。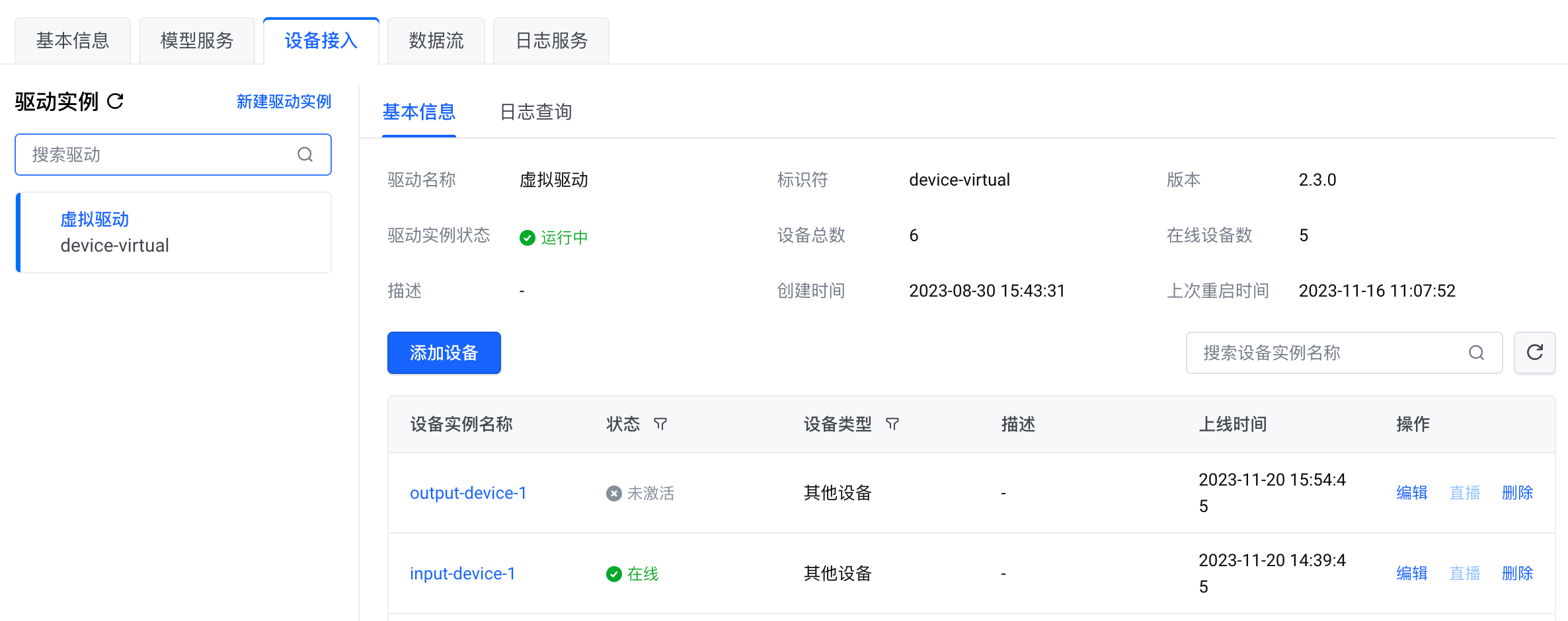
部署时序数据流
准备工作完成后,我们就可以创建和部署时序数据流。在开始之前,我们先汇总一下输入和输出属性。
设备名称 | 类型 | 属性 |
|---|---|---|
input-device-1 | 输入设备 | temperature(double) |
output-device-1 | 输出设备 | result(int) |
在这部分,我们将创建一个时序数据流,它的工作流程如下:从 input-device-1 的 temperature 获取数据,将数据依次流转到多个 SQL执行过程 节点进行处理,然后将最终结果写入 output-device-1 的 result。
步骤1. 创建时序数据流模板
登录边缘智能控制台。
在左侧导航栏,从 我的空间 下拉列表选择一个空间。
- 在左侧导航栏,选择 数据处理 > 数据流模板。
- 单击 创建模板。
- 在 创建模板 对话框,配置以下参数,然后单击 确定。
- 名称:设置为 time-series-demo。
- 模板类型:选择 时序数据流。
步骤2. 为模板创建版本
- 单击上一步创建的数据流模板的名称。
- 在 版本管理 区域,单击 创建版本。
- 在 创建版本 对话框,设置一个 版本名称,然后单击 确定。
在本教程中,我们使用 v1 作为版本名称。
步骤3. 为版本编排数据流
单击上一步创建的版本的名称。
在 数据流编排 页面,单击 开始编辑。
按照下图绘制数据流,然后单击 保存。
具体绘制方法,请参见数据流编排指南。说明
- 数据流中包含三个 SQL 执行过程 节点,这些节点是有冗余的。这样做是为了方便调试和扩展使用。实际使用时,请根据需要进行调整。
- 数据流中包含两个输出节点:虚拟时序设备输出源 和 Kafka输出。使用 Kafka 输出是为了更直观地看到输出的内容。使用 Kafka输出 节点的前提是您有已搭建好的 Kafka 服务器。如果您没有 Kafka 服务器,则无需在数据流中增加 Kafka输出 节点。
步骤4. 基于模板创建数据流实例
- 在左侧导航栏,选择 数据处理 > 数据流实例。
- 单击 创建实例。
- 在 创建数据流实例 对话框,配置以下参数,然后单击 确定。
- 名称:设置为 time-series。
- 模板:选择 自定义模板/时序数据流/time-series-demo。
- 版本:选择 v1。
- 节点:选择您的节点。
步骤5. 部署数据流
单击上一步创建的数据流实例的名称。
单击 编辑数据流。
按照下表的说明,为数据流的各个节点设置控制参数,完成后单击 保存。
节点
控制参数
说明
设备输入源
device
选择虚拟输入设备(input-device-1)。
output
设置为 table1,表示使输入数据流转到 table1 表。
table1 表示定义一个 table1 表,这样在下个 SQL 处理节点中您可以在 SQL 语句中使用 table1。SQL执行过程(1)
sql
设置为
select * from table1;
这是一个冗余的 SQL 执行语句,表示将 table1 表的数据推送到 table2 表。output
设置为 table2。
SQL执行过程(2)
sql
设置为
select max(log(temperature)) as result1, min(log(temperature)) as result2 from table2 GROUP BY COUNTWINDOW(5);
这条 SQL 执行语句表示:从log中取 temperature 的值,然后在每 5 个值中取最大值存为 result1,取最小值存为 result2。COUNTWINDOW 是 eKuiper 的计数窗口。更多信息,请参见计数窗口。
output
设置为
table3。SQL执行过程(3)
sql
设置为
select 1 as result from table3 where abs(result1 - result2) > 0.5;
这条 SQL 执行语句表示:当result1 - result2的绝对值大于 0.5 时,将 result 设置为 1。注意
请注意,此处一定要使用
xxx as result。这里的 result 与虚拟输出设备的 result 属性相对应,并且数据类型也一定要对应,否则会导致无法观测到数据。output
设置为
table4。虚拟时序设备输出源
device
选择虚拟输出设备(output-device-1)。
Kafka输出
kafka-brokers
Kafka 服务器的访问地址(包含端口号)。格式:
<address>:<port>。topic
设置消息的主题。
sasl-auth
设置 Kafka 服务器启用的 SASL 认证的类型。在本教程中,Kafka 服务器未采用 SASL 认证,该参数的值为 none。
单击页面右上角的 部署,然后在弹出的对话框单击 部署。
提交部署请求后,您可以回到数据流实例页面。当数据流实例的状态变为 运行中,表示数据流已经部署成功。
结果验证
数据流部署成功后,我们可以查看输出设备的运行数据,来验证结果。
- 在左侧导航栏,选择 设备管理 > 设备实例。
- 单击虚拟输出设备的名称(output-device-1)。
- 单击 运行状态 页签。
在输出设备的 result 属性中,我们可以看到如下的数据点。
根据本教程中的设置,输入设备每秒随机生成一个温度数据;SQL 执行语句对每 5 个温度数据做一次最大值与最小值之间的温度差计算,即每 5 秒会有一个分析结果;由于设置了条件(温度差大于 0.5 时将 result 设置为 1),所以约每 10 秒 result 会有一个数据。
如果数据流的输出包含 Kafka 节点,您可以自行查看 Kafka 收到的数据。下图是通过 kafka-ui 查看到的结果。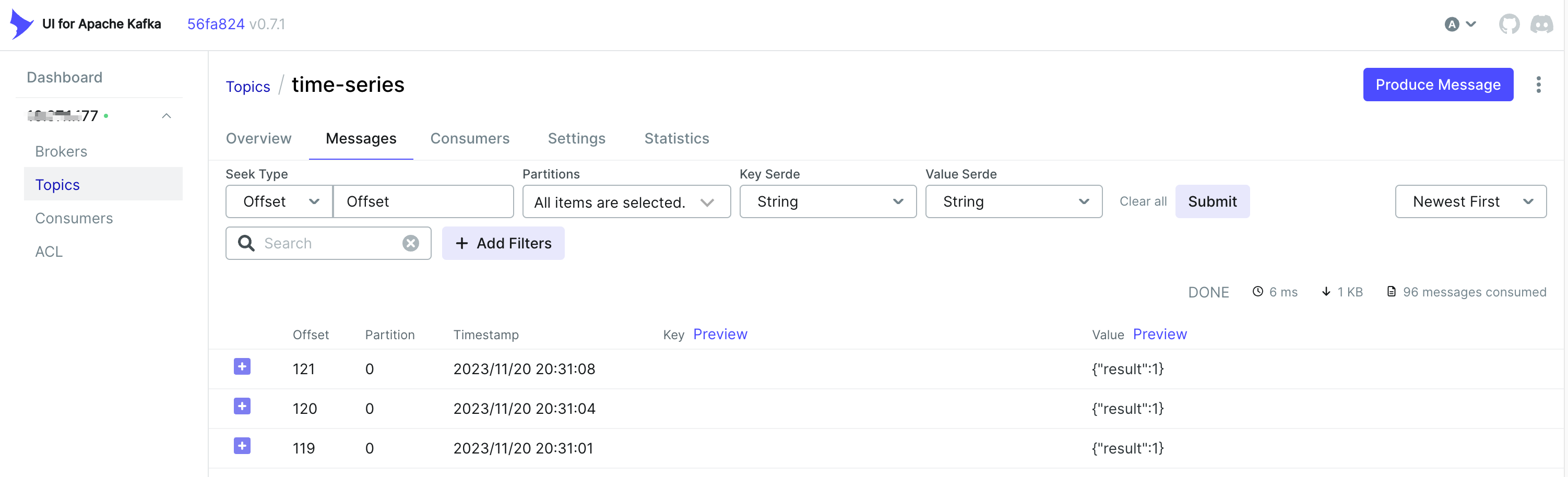
附录
在上文模拟的场景中,只有当温度突变时,才会将 result 设置为 1。假设我们需要在温度没有突变时,将 result 设置为 0。那么需要如何配置数据流呢?
以下是一种方案:
复制数据流模板的已有版本,生成一个新版本。编排新版本的数据流,增加一个 SQL执行过程 节点和一个 虚拟时序设备输出源 节点。如下图所示。
使用新版本创建数据流实例,按照以下说明配置新节点的控制参数,旧节点的控制参数与上文的说明相同。
节点
控制参数
说明
SQL执行过程(新增)
sql
设置为
select 0 as result from table3 where abs(result1 - result2) <= 1;
这条 SQL 执行语句表示:当result1 - result2的绝对值小于 1 时,将 result 设置为 0。output
设置为
table5。虚拟时序设备输出源(新增)
device
选择虚拟输出设备(output-device-1)。
部署新的数据流实例。
部署新的数据流实例后,在输出设备的运行数据中,您可以观察到下图所示的结果。