边缘智能
边缘智能



文档指南

请输入


- 文档首页
 边缘智能边缘智能平台用户指南边缘推理官方模型视觉提示分割-SAM2.1-Ensemble
边缘智能边缘智能平台用户指南边缘推理官方模型视觉提示分割-SAM2.1-Ensemble

视觉提示分割-SAM2.1-Ensemble
视觉提示分割-SAM2.1 是一个官方模型组。本模型组以 SAM2.1 - large 模型为基础,既支持根据点(+框)对 1 个目标进行分割,也支持根据框对多个目标进行分割。
SAM2(即 Segment Anything 2)是 Meta 开发的模型,它能对图像里的任意物体进行分割,不受特定类别或领域的限制。该模型的特别之处在于其训练数据的规模,用到了 1100 万张图像和 110 亿个掩码。如此大量的训练,让 SAM2 成为开展新图像分割任务训练的有力开端。
基本信息
视觉提示分割-SAM2.1 模型组有 4 个模型。其中,Ensemble 模型里集成了前处理模型(Pre-Processing)、图像编码器(Encoder)和掩码解码器(Decoder),它规定了模型组的整体工作流程。在使用时,您只需部署 Ensemble 模型,不用关心中间的处理环节。
您可以在边缘智能控制台的 官方模型 列表访问 Ensemble 模型。下图展示了本模型的基本信息。
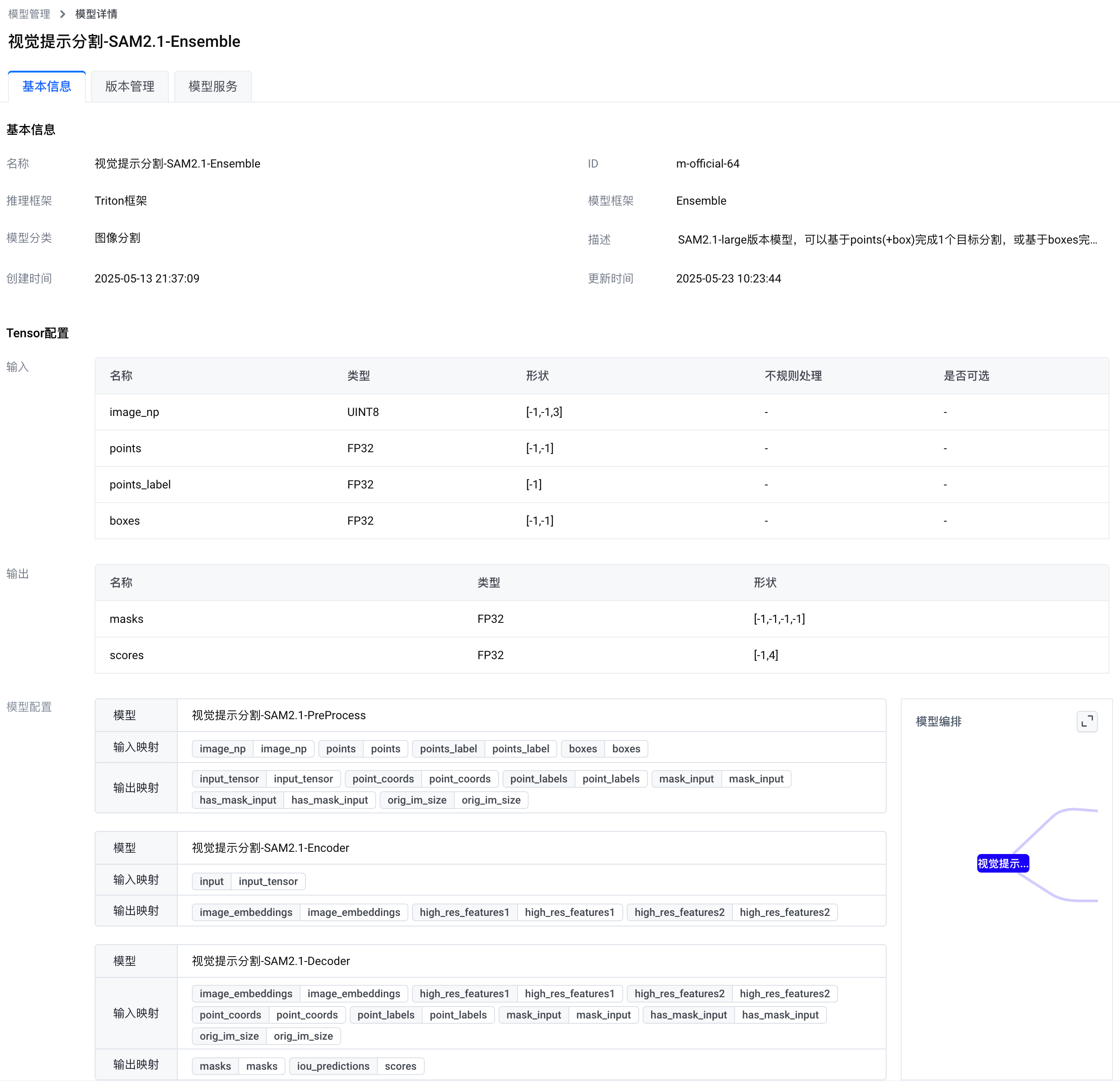
Ensemble 模型输入
| 名称 | 类型 | 形状 |
|---|---|---|
| image_np | UINT8 | [-1,-1,3] |
| points | FP32 | [-1,-1] |
| points_label | FP32 | [-1] |
| boxes | FP32 | [-1,-1] |
输入说明:
- image_np
这是要测试的图像,数据类型为 numpy.uint8,尺寸是[高, 宽, 3],这里的 3 表示通道数,通道顺序是 RGB。 - points
这是一个 numpy.float32 类型的二维数组,格式为[[x1, y1][, x2, y2], ...]。[x, y]是提示点在水平和垂直方向的像素坐标,提示点的数量没有限制。 - points_label
这是一个 numpy.float32 类型的一维数组,格式为[1, 1, .....]。- 数组里的元素只能是 1 或者 0。1 表示这个提示点的位置属于要分割的目标;0 表示这个点是背景点,不属于要分割的目标。
points_label的元素数量必须和points的元素数量一样。
- boxes
这是一个 numpy.float32 类型的二维数组,格式为[[x1, y1, x2, y2], ...]。[x1, y1, x2, y2]分别是目标边界框(bbox)左上角点的水平、垂直像素坐标,以及右下角点的水平、垂直像素坐标。
这个参数可以不提供,也可以提供 1 个和提示点对应的边界框,还可以提供多个边界框坐标。- 如果提供多个边界框坐标,就能实现多目标分割功能,每个目标由对应的边界框来指定。
- 如果边界框的数量小于等于 1,就会进行单目标分割,要分割的目标由提示点来确定。
Ensemble 模型输出
| 名称 | 类型 | 形状 |
|---|---|---|
| masks | FP32 | [-1,-1,-1,-1] |
| scores | FP32 | [-1,4] |
输出说明:
结果是一个字典类型的数据,有 2 个键,分别是 ["masks","scores"],对应的数值都是 numpy.float32 类型的数组。
masks对应的数值是一个形状为[N, 高, 宽, 1]的数组。这里的 N 是分割结果的数量。
若提供了多个边界框(bbox)坐标,N 就等于边界框的数量;若没提供多个边界框坐标,N 等于 1。“高”和“宽”不用特别在意,和图像原本的尺寸一样。最后一维的 1 表示这是灰度图。scores是和masks对应的得分列表,数组长度和 N 相同,是 numpy.float32 类型的一维数组。
Ensemble 模型部署
视觉提示分割-SAM2.1-Ensemble 模型提供一个可部署版本。

参考部署模型服务进行模型服务的部署。在 部署模型服务 参数配置页面,修改以下配置:
说明
下表中未包含的配置项无需修改,建议使用默认值。
| 类型 | 配置项 | 说明 |
|---|---|---|
| 基本信息 | 节点 | 选择一个边缘节点。 |
| 服务名称 | 设置一个服务名称。该名称不能与节点上其他服务的名称重复。 | |
| 模型信息 | 模型 | 选择 官方 | 视觉提示分割-SAM2.1-Ensemble。 |
| 模型版本 | 选择 v1。 | |
| 服务配置 | HTTP端口 | 指定节点上的一个空闲端口。 |
| GRPC端口 | 指定节点上的一个空闲端口。 |
调用示例
模型服务部署成功后,您可以下载以下客户端调用示例,用来验证模型服务的效果。


最近更新时间:2025.06.09 14:13:33
这个页面对您有帮助吗?
有用
有用
无用
无用