边缘智能
边缘智能



文档指南

请输入


- 文档首页
 边缘智能边缘智能平台用户指南边缘推理官方模型图文匹配-SigLIP2-Ensemble
边缘智能边缘智能平台用户指南边缘推理官方模型图文匹配-SigLIP2-Ensemble

图文匹配-SigLIP2-Ensemble
图文匹配-SigLIP2 是一个官方模型组。本模型组具备基于 SigLIP2 结构的图文匹配能力,能算出每对图文的相似性分数。
基本信息
图文匹配-SigLIP2 模型组有 5 个模型。其中,Ensemble 模型包含了前处理模型(Pre-Processing)、文字和视觉处理模型(Backbone-Text 和 Backbone-Visual)和后处理模型(Post-Processing),它规定了模型组的整体工作流程。在使用时,您只需部署 Ensemble 模型,不用关心中间的处理过程。
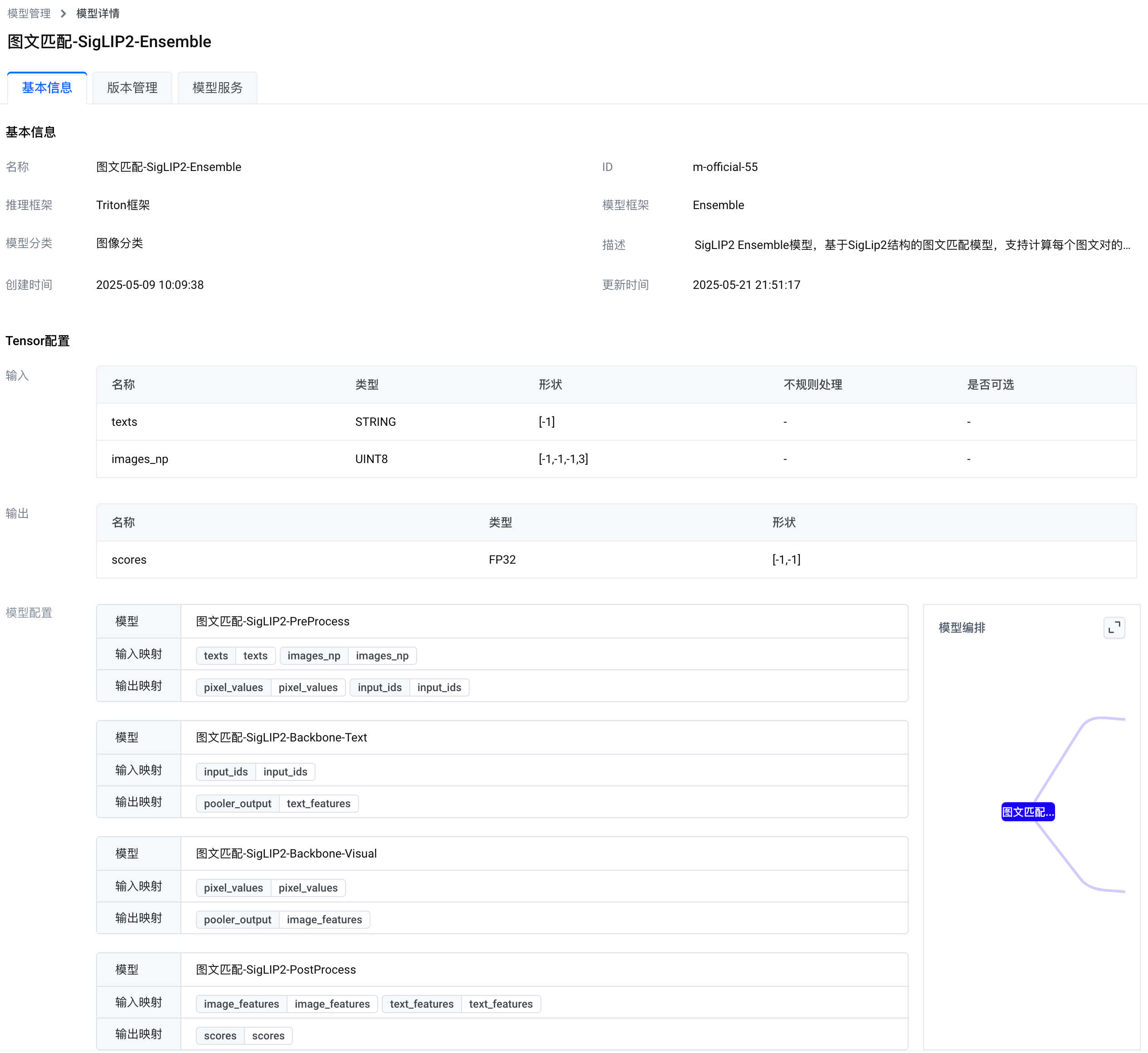
您可以在边缘智能控制台的 官方模型 列表访问 Ensemble 模型。下图展示了本模型的基本信息。
Ensemble 模型输入
| 名称 | 类型 | 形状 |
|---|---|---|
| texts | STRING | [-1] |
| images_np | UINT8 | [-1,-1,-1,3] |
输入说明:
- texts
待匹配图文对的文字描述列表。可以用中文或英文。例如["图像中有2只猫和2个遥控器", "There are two cats and two remote controllers in the picture", "两只狗"]。每个描述文字的长度不能超过 16 个字符。 - images_np
待匹配图文对的图像列表,数据类型是 numpy.uint8,尺寸是[N,高,宽,3]。这里的 3 表示通道数,按 RGB 顺序排列;N 是图像的数量。
Ensemble 模型输出
| 名称 | 类型 | 形状 |
|---|---|---|
| scores | FP32 | [-1,-1] |
输出说明:
结果是一个二维的 numpy.float 类型数组,尺寸是 [N,M]。这里的 N 指的是图像的数量,M 指的是描述文本的数量。
Ensemble 模型部署
图文匹配-SigLIP2-Ensemble 模型提供一个可部署版本。

参考部署模型服务来部署模型服务。在 部署模型服务 参数配置页面,修改以下配置:
说明
下表中未包含的配置项无需修改,建议使用默认值。
| 类型 | 配置项 | 说明 |
|---|---|---|
| 基本信息 | 节点 | 选择一个边缘节点。 |
| 服务名称 | 设置一个服务名称。该名称不能与节点上其他服务的名称重复。 | |
| 模型信息 | 模型 | 选择 官方 | 图文匹配-SigLIP2-Ensemble。 |
| 模型版本 | 选择 v1。 | |
| 服务配置 | HTTP端口 | 指定节点上的一个空闲端口。 |
| GRPC端口 | 指定节点上的一个空闲端口。 |
调用示例
模型服务部署成功后,您可以下载以下客户端调用示例,用来验证模型服务的效果。


最近更新时间:2025.06.09 14:13:33
这个页面对您有帮助吗?
有用
有用
无用
无用