智能推荐平台
智能推荐平台



文档指南

请输入


- 文档首页
 智能推荐平台用户指南模型开发预置模型
智能推荐平台用户指南模型开发预置模型

预置模型
模型代码开发
- 新建预置模型:进入【模型开发】模块,单击【模型管理】,选择【预置模型】模式,单击【新建预置模型】,配置表单信息,模型新建完成后会自动生成版本号。
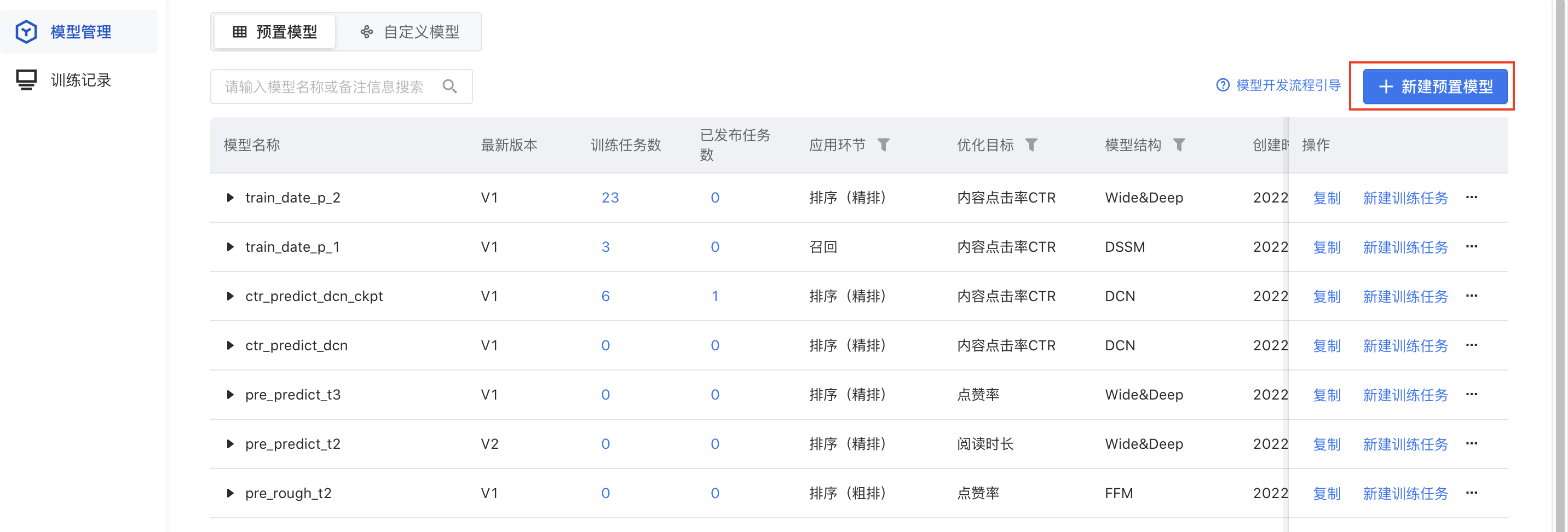
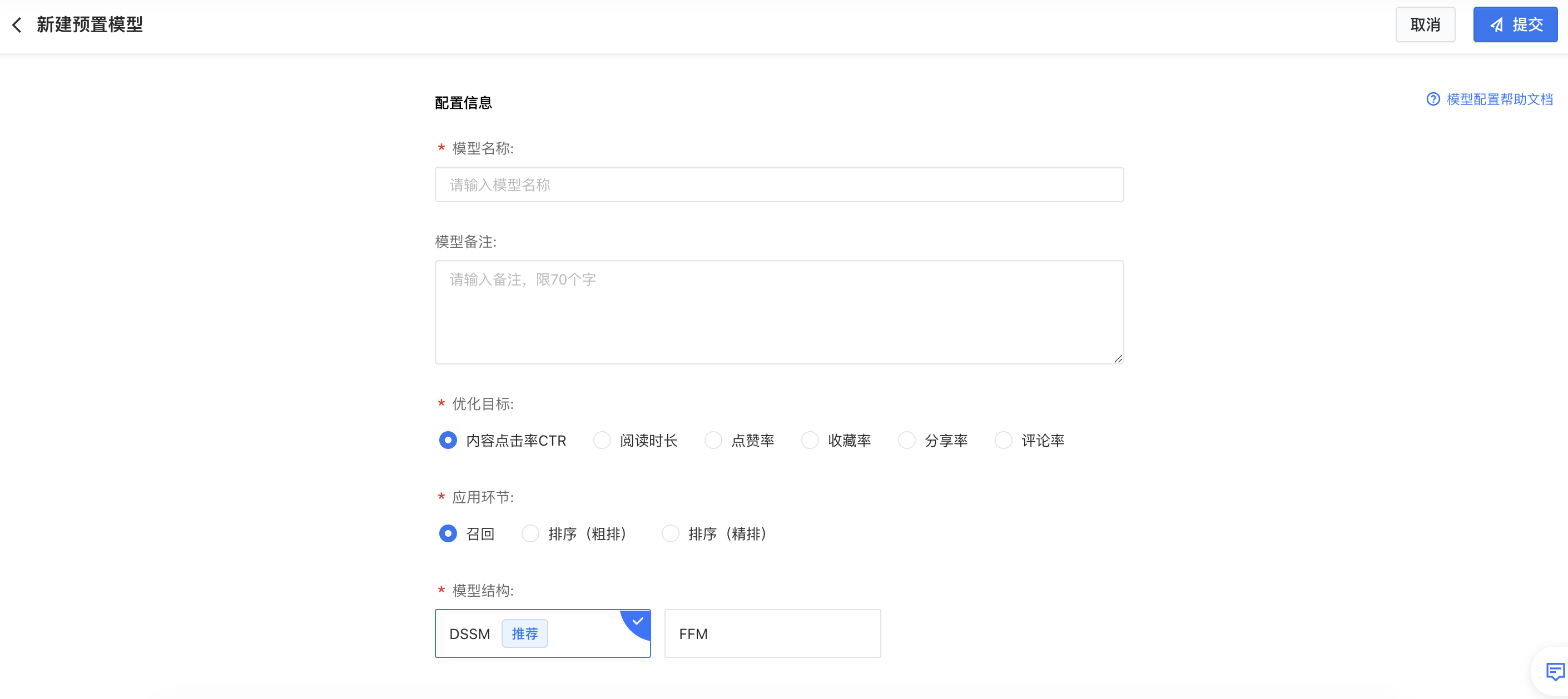
- 优化目标:模型要优化的业务目标,不同行业优化目标不同。例如电商包括商品点击率CTR、商品转化转化率CVR;内容社区包括内容点击率CTR、阅读时长、点赞率、转发率、收藏率、评论率;长视频包括点击率、播放率、播放时长、播放完成率、订阅率。
- 应用环节:模型应用的环节,包括召回环节、排序(粗排)环节、排序(精排)环节。
- 模型结构:指算法类型,不同应用环节使用的模型结构不同,例如召回/粗排环节提供了DSSM、FFM等模型结构;精排环节提供了Wide&Deep、DCN等模型结构。
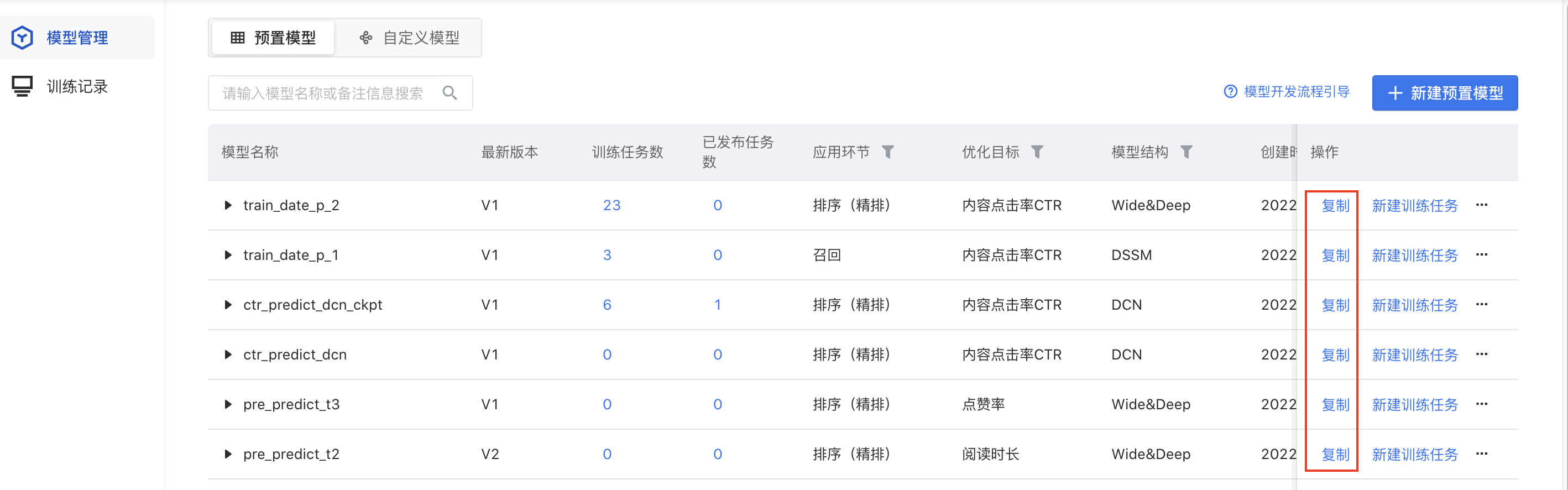
- 复制模型:点击预置模型列表操作栏中的“复制”,模型名称继承源模型,您可以修改模型结构;提交后,会自动生成版本号。
模型训练
新建或复制完预置模型后,模型会自动编译,模型未编译完成,无法新建训练任务。
模型编译完成,可新建训练任务,配置训练任务信息。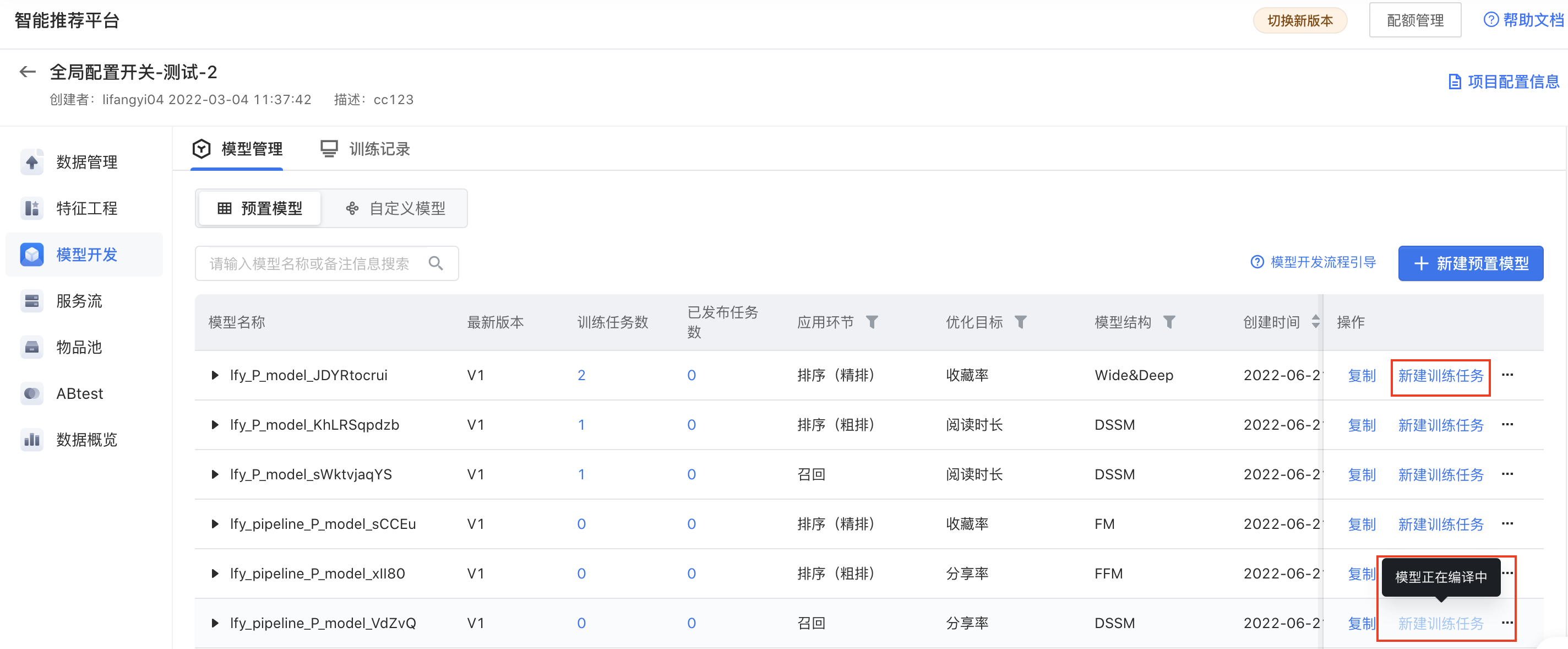
- 训练模式配置:
- 预加载模型配置:模型备份会生成 checkpoint,您可以加载相同模型下且模型结构一样的 checkpoint 接着进行训练。checkpoint 为模型备份时训练完成的样本时间,例如,您选择的 checkpoint 为 2022 年 7 月 4 日 09:59:59,意味着加载了训练到 7 月 4 日 09:59:59 样本的模型。
- 追新机制配置:配置追新机制及训练时间范围。
- 训练资源配置
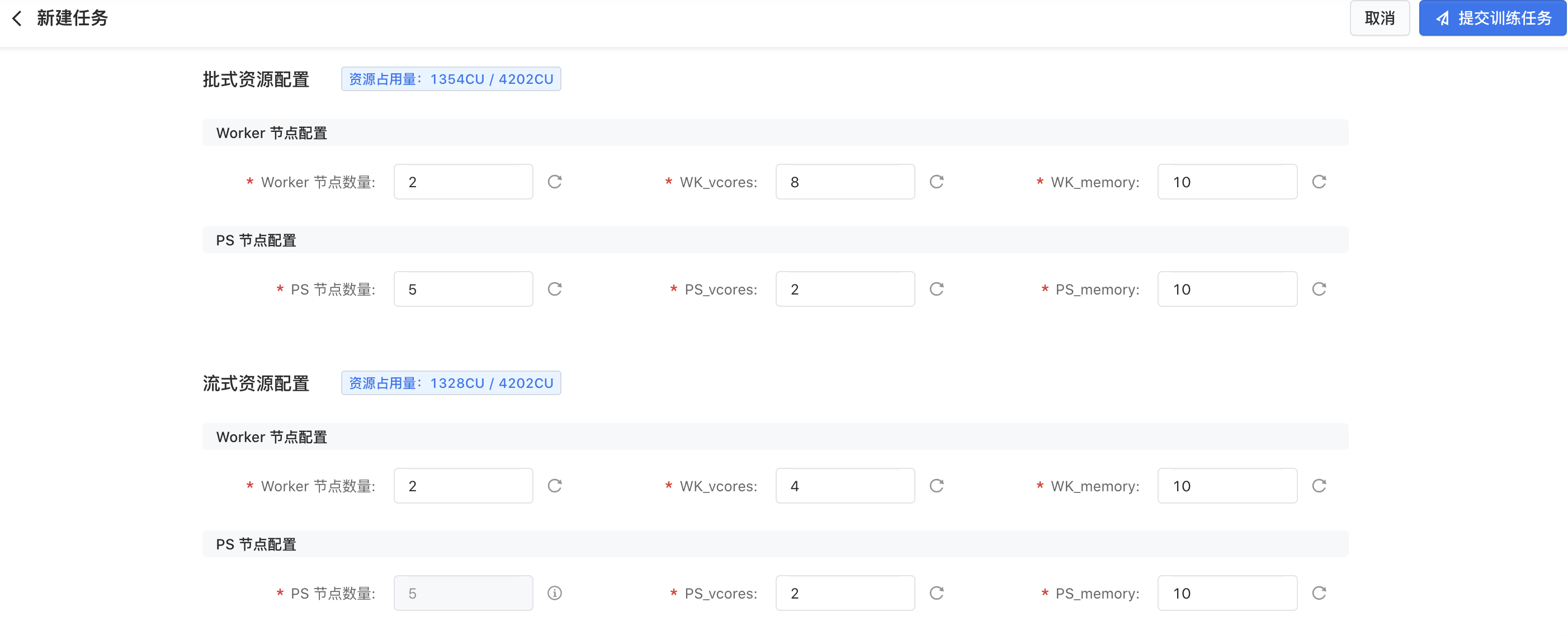
- 批式资源配置:所有追新模式都需要配置批式资源,配置的资源量不能超过模型训练配额。具体配置包括:
- Worker 节点数量:Worker 节点的个数。每个 Worker 负责训练一部分样本,Worker数越多,模型训练速度越快,但由于梯度采用异步更新的方式,因此 Worker 数太多会造成训练效果有损。推荐的 Worker 数范围:2-200。
- WK_vcores:每个 Woker 分配的 CPU 核数。WK_vcores 越多,模型训练速度越快,一般用默认配置即可。
- WK_memory:每个 Woker 分配的内存大小(GB)。采用默认配置即可。
- PS 节点数量:Parameter Server(PS)即参数服务器的个数。每个 PS 节点存了模型一部分参数,一般 Worker 数设置越大,PS 数也需要设置的越大。
- PS_vcores:每个 PS 节点分配的 CPU 核数,PS_vcores 越多,模型训练速度越快,一般用默认配置即可。
- PS_memory:每个 PS 节点分配的内存大小(GB),模型占用内存总大小=PS数量*PS_memory,因此 PS 数量越大,PS_memory 可适当调小。
- 流式资源配置:流式追新模式需要配置流式资源,流式的 PS 节点数量与批式一致,不可修改;配置的资源量不能超过模型训练配额。
- 估算一个模型训练任务总资源开销的计算公式:
- CPU核数=Worker节点数量WK_vcores+PS数PS_vcores
- 内存大小=Worker节点数量WK_memory+PS数PS_memory
- 资源占用量=MAX(CPU核数,内存大小/4)
- 效果指标采样率:计算模型离线效果指标时,采集样本的比例,例如训练样本数100万,采样10%用来计算模型离线效果指标。如果您的样本数较大,可以设置的小些,从而节省计算资源;设置的越大,效果指标越可信。

模型效果评估
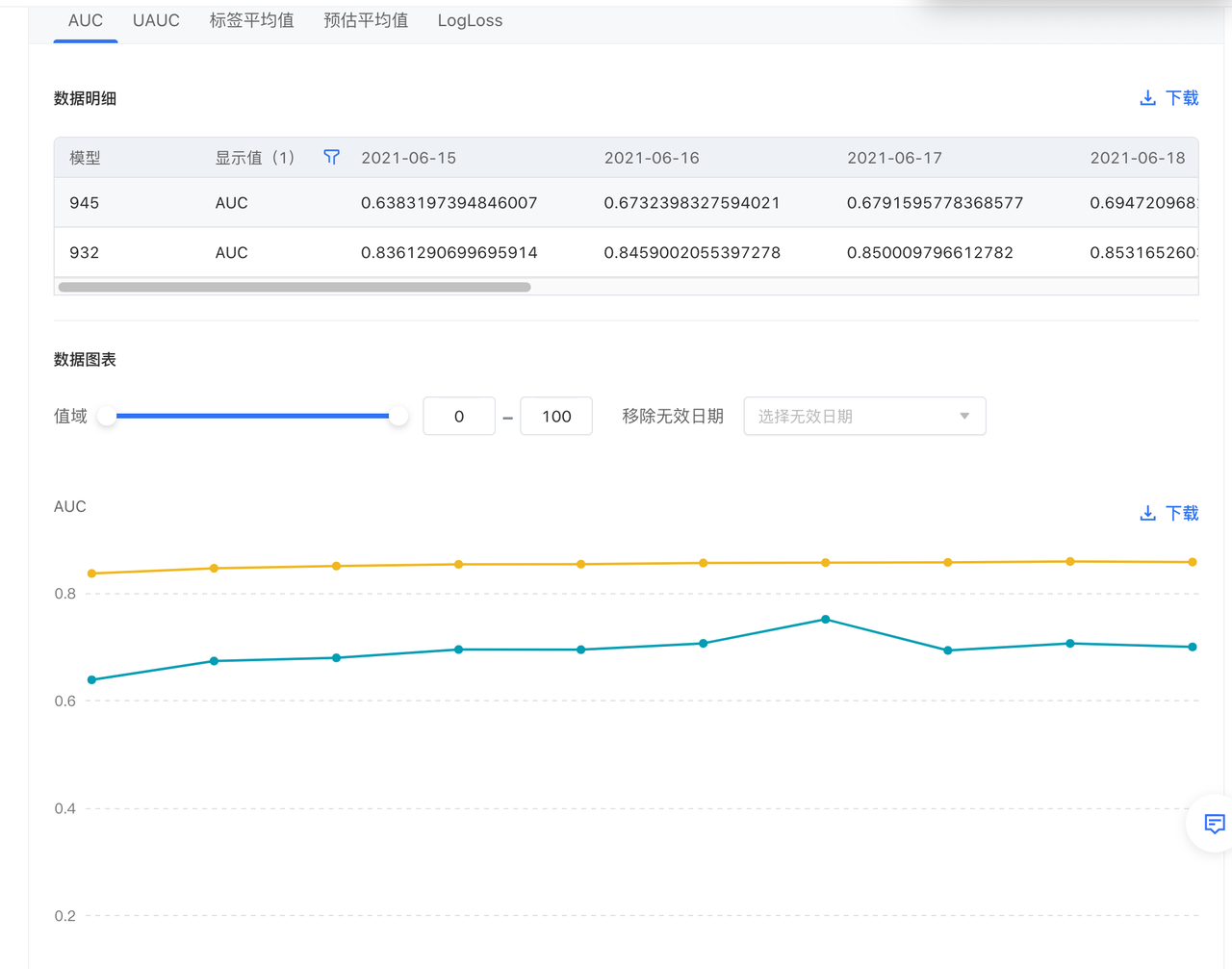
模型进入到训练阶段后,点击任务 ID 即可查看模型效果指标。添加任务 ID,可以对比添加的多个任务 ID 与第一个任务 ID 效果指标的差异。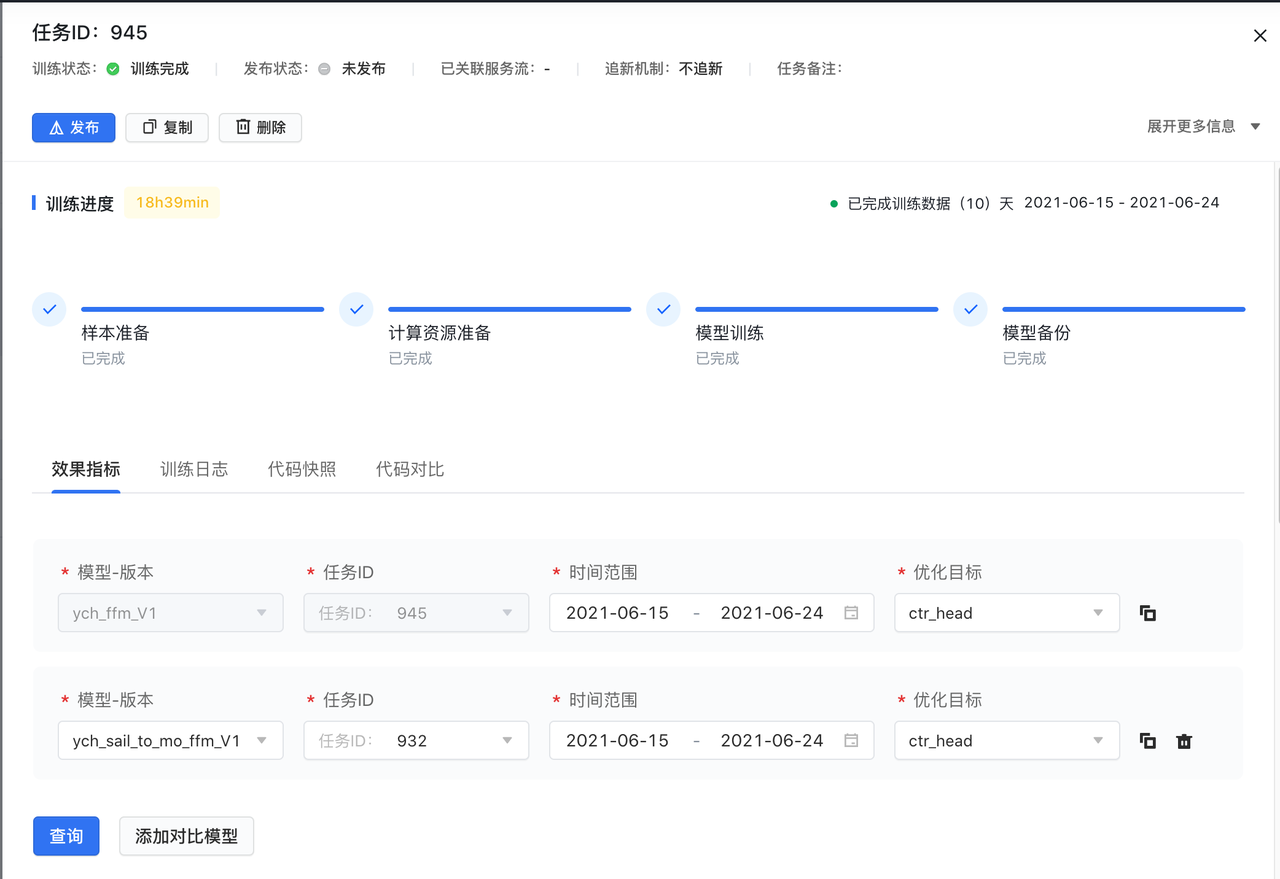
模型发布
- 发布:模型发布是将离线训练的模型部署到线上,供服务流使用,提供在线推理服务。建议您发布训练效果指标符合预期的追新模式的模型。点击操作栏中的发布即可执行模型发布,是否能执行发布与训练状态有关:
- 对于不追新的训练任务来说,训练完成后就能执行发布操作。
- 对于追新的训练任务来说,状态为训练中且至少有一次备份 checkpoint,才能执行发布操作。

- 下线:发布到线上的模型在满足一定条件时可以下线。
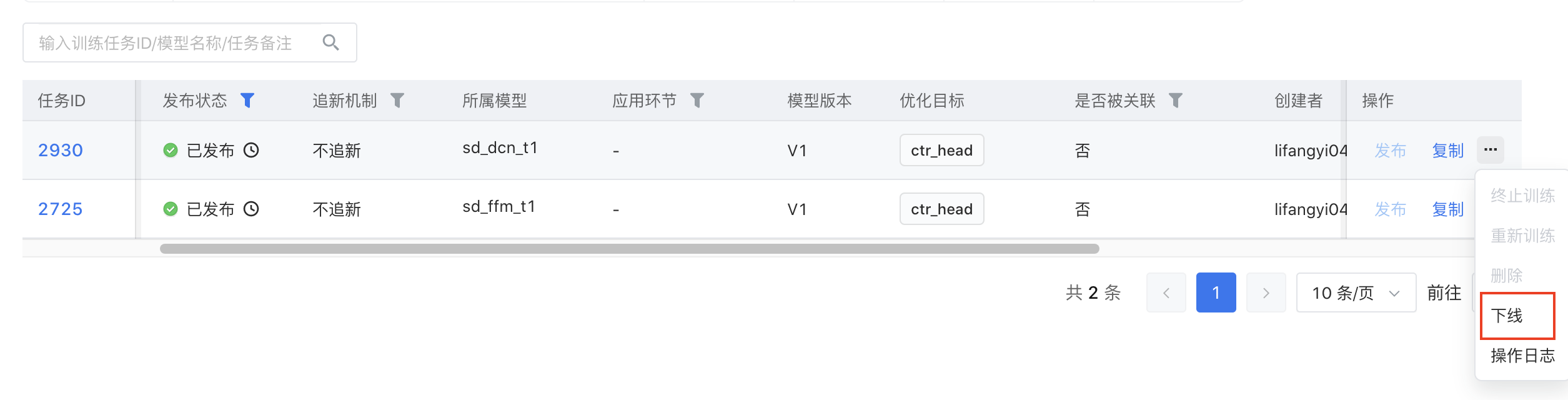
- 召回模型:没有关联已发布的召回任务则可以下线。
- 粗排模型/精排模型:没有关联已上线的在线服务,或没有关联运行中的AB实验则可以下线。
最近更新时间:2023.10.18 19:37:09
这个页面对您有帮助吗?
有用
有用
无用
无用