智能推荐平台
智能推荐平台






- 文档首页
 智能推荐平台用户指南特征工程特征
智能推荐平台用户指南特征工程特征

通过配置抽取方法对原始特征或特征进行抽取得到的模型可识别的特征。
新建特征有两种途径:单个新建特征、批量新建特征。
(1)单个添加特征:单个配置每个特征的名称、依赖、抽取方法、参数配置、标签、备注。参数介绍如下:
- 依赖:指抽取方法的输入,可以是原始特征或已有的特征。
- 抽取方法:是对输入的原始特征或特征,按照参数配置抽取加工成模型可识别的特征格式的计算方法。详见下面的【抽取方法说明】。
- 参数配置:是特征抽取方法的参数配置,需要根据具体业务需求去定义。
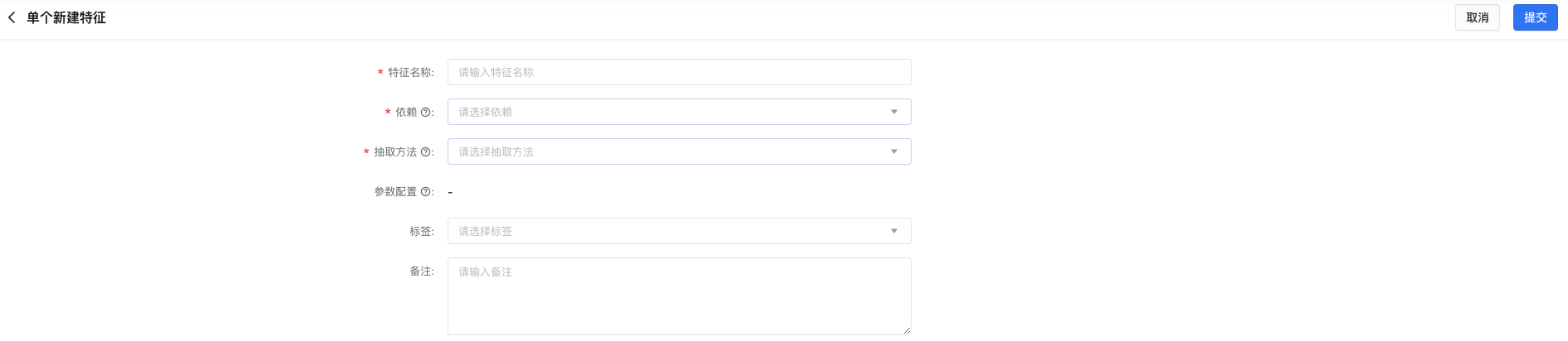
(2)批量新建特征:
- 在 step1 中配置预定义信息,包括筛选原始特征、特征命名规则、默认抽取方法&参数、标签。
- 点击【确认批量生成】,系统会筛选出所有符合条件的原始特征,在原始特征名称的基础上增加前缀或后缀得到特征名称,并且按照原始特征的字段类型定义默认的抽取方法和参数去配置,把所有信息展示在 step2 中。
- 根据需要做相应的修改,最后点击提交。
在线特征是提供给在线服务使用的特征,用于 inference(召回、粗排和精排)。即在线特征是指所有栏位下关联的所有特征,包括在线模型用到的特征,以及手动关联到栏位的特征。
在线特征按目前的分类有(KV、实时窗口、context)。Streaming Feature 是在线特征的 dump,流式样本用 Streaming Feature 和实时 Label (来自于消息队列表)拼接而来。
(1)批量特征关联栏位或取消关联栏位
- 单击【编辑在线特征】,在编辑在线特征状态列表页,勾选需要的若干特征。

- 选择单击【批量关联栏位】或【批量取消关联】,在弹框页中选择欲增加关联或取消关联的若干个栏位,单击确定。
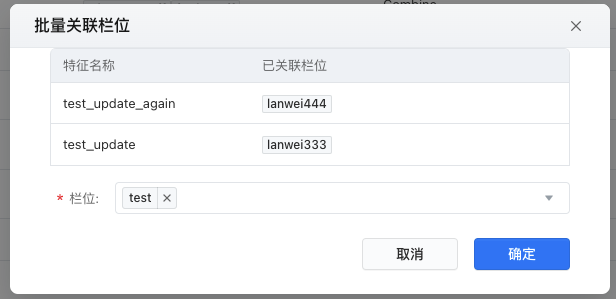
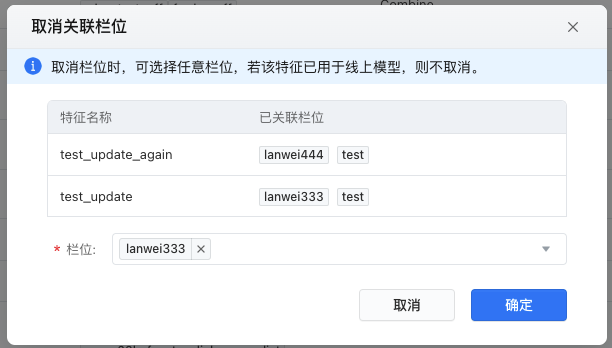
- 编辑完需要关联或解除关联栏位的特征后,点击【保存】,返回原特征列表页
(2)单个特征关联栏位或取消关联栏位
- 关联栏位:特征列表页点击关联栏位数量,在弹框中点击【关联栏位】,再选择需要增加的栏位,点击【确定】返回特征列表页。
- 取消关联:选择需要取消关联的栏位,点击【取消关联】,弹框中点击【确定】返回特征列表页。
栏位关联方式
特征列表的关联栏位数量,显示手动发布且关联的栏位的数量 以及 在线模型中使用且发布到线上的栏位数量。
当查看特征关联的栏位详情时,关联方式列通过在线模型使用、手动发布显示不同关联方式。其中,通过在线模型使用关联的栏位,不支持手动解除关联。
- 在线模型:通过在线服务中召回、精排或粗排被选中而发布到线上的模型。
- 通过在线模型发布到线上的特征:包含在模型代码中,当模型发布到线上时,会调用 feature store 发布到线上的特征。
发布特征可将特征关联到栏位,发布成功后才可用于在线预估及流式样本。
单击【发布特征】,从特征维度和栏位维度分别确定此次发布中会增加关联及取消关联的特征栏位关系,确定没问题后,单击【确定】,系统会按照此配置更新特征与栏位的关联关系。
特征工程方法 | 依赖类型 | 依赖数量 | 输入类型 | 参数列表 | 使用说明 |
|---|---|---|---|---|---|
| 原始特征 | 1 | Int | 无 | 把 int转成 string 做 hash |
| 原始特征 | 1 | bigint | 无 | 把bigint 转成 string 做 hash |
| 原始特征 | 1 | string | 无 | 做 hash |
| 原始特征 | 1 | float | 无 | 把 float 转成 string 做 hash |
| 原始特征 | 1 | double | 无 | 把 double 转成 string 做 hash |
| 原始特征 | 1 | bigint | 无 | 对 bigint 取 log,再做hash |
| 原始特征 | 1 | string | delimeters:string | 将输入按照分隔符分隔,并保留小于等于指定数量的分隔后的字段,最后做hash。输入 string 的编码格式为 utf8。 |
| 原始特征 | 1 | string | delimeters:string | 将输入按照分隔符分隔,并保留小于等于指定数量的分隔后的字段,最后做hash。输入 string 的编码格式为非 utf8。 |
| 原始特征 | 1 | array< int > | Topk:int | 把输入项的前topk个数据做hash,Topk=-1代表不做截断。输入数组的数据类型为 int。 |
| 原始特征 | 1 | array< bigint > | Topk:int | 把输入项的前topk个数据做hash,Topk=-1代表不做截断。输入数组的数据类型为 bigint。 |
| 原始特征 | 1 | array< string > | Topk:int | 把输入项的前topk个string数据做hash,Topk=-1代表不做截断 |
| 原始特征 | 1 | array< float > | Topk:int | 把输入项的前topk个float数据做hash,Topk=-1代表不做截断 |
| 原始特征 | 1 | array< double > | Topk:int | 把输入项的前topk个数据double做hash,Topk=-1代表不做截断 |
| 原始特征 | 2 | array< string >, array< float > | num_id:int | 该方法用于从选择的第一个 array 中取部分值进行 hash,有两种使用场景。
该方法依赖两个 array 类型的原始特征作为输入。第1个是待处理的字符串 array;第2个是对应的权重 array。二者须长度一样,在产品内配置时一定要先选择待处理的字符串 array 再选择对应的权重 array。另外,num_id <0 时会遍历第1个 array 的所有值。 |
| 原始特征 | 1 | string | 无 | 取ip的前3段,然后进行hash |
| 原始特征 | 1 | bigint | div: int | 此方法用来计算精确到秒的时间戳所属范围,并做hash |
| 原始特征 | 1 | bigint | div1: int | 此方法用来计算精确到秒的时间戳所属范围,并做hash。但是比上个方法多了一个参数 |
| 原始特征 | 2 | bigint, bigint | div: int | 先计算(第二个input - 第一个input)/div得到一个值,若该值<{max_value},则取该值,否则则取max_value。最后将结果hash |
| 原始特征 | 1 | bigint | multiple:int | 先计算log( input + 1 ) * multiple,然后hash |
| 原始特征 | 1 | float | multiple:int | 先计算log( input + 1 ) * multiple,然后hash |
| 原始特征 | 1 | float | div_num:float | 先计算input * div_num,然后hash |
| 特征 | 2 | array< uint64 >, array< uint64 > | 无 | 对两个特征值嵌套计算。
最终输出的特征长度固定为 mn |
| 特征 | 2 | array< uint64 >, array< uint64 > | 无 | 判断两个列表中是否有元素会匹配 |
| 原始特征 | 1 | map(internal) | topk | 输入必须是用户实时窗口聚合类原始特征,表示对用户最近发生行为的item维度按行为次数倒序排列,取topk后做哈希 |
| 原始特征 | 1 | map(internal) | topk type
without_fid smooth_alpha | 对用户最近发生行为的 item 按取出的原始特征取 TopK 后做哈希。 |
| 原始特征, 特征 | 2 | map(internal), array< uint64 > | 无 | 输入的第一个对象必须是用户、父物品实时窗口聚合类原始特征(recent、score类)。用物品侧特征跟用户、父物品最近发生行为的物品统计做Match,Match 后做哈希。 |
| 原始特征, 特征 | 2 | map(internal), array< uint64 > | topk type
without_fid | 描述同上。 |
FeatureColumnFloatValues | 原始特征 | 1 | array | 无 | 对于连续值原始特征,直接使用其原始值参与模型训练,一般用于仅更新模型参数而不更新特征 embeding。 |
FeatureColumnInt64Values | 原始特征 | 1 | array | 无 | 对于连续值原始特征,直接使用其原始值参与模型训练,一般用于仅更新模型参数而不更新特征 embeding。 |