智能推荐平台
智能推荐平台






- 文档首页
 智能推荐平台用户指南特征工程样本管理
智能推荐平台用户指南特征工程样本管理

将特定的特征集和行为数据源做拼接,生成样本,样本可用于模型训练。样本分批式样本和流式样本。
- 批式样本:由表格类行为数据表拼接特征生成。
- 流式样本:由消息队列类行为数据表拼接在线特征生成。
目前平台支持3种批式样本样本和1种流式样本。
样本名称 | 样本类型 | 调度周期 | 前置条件 | 特征来源 | Label 来源 |
|---|---|---|---|---|---|
批式1 | 批式 | 1天 | 接入了增量天级数据 | 基于天级行为生成的离线特征 | 批式天级行为表 |
批式2 | 批式 | 1天 | 接入了增量天级数据,发布了在线特征 | 在线特征 | 批式天级行为表 |
批式3 | 批式 | 1小时 | 已创建流式样本且流式样本开启追新 | 来自流式样本 dump | 来自流式样本 dump |
流式 | 流式 | 实时 | 接入了增量实时数据,发布了在线特征 | 在线特征 | 流式实时行为表 |
下面依次介绍新建样本时,需要填写的基础信息、选择行为与特征数据、设置需要在样本中保留原始值的字段、进阶配置。
基础信息
- 样本类型:批式基于天级批式行为数据生成样本;流式基于实时行为数据实时生成样本。
- 创建方式:重新创建是指从0配置行为数据表、特征、辅助信息;基于已有样本创建是指可以选择一个已有样本,在该样本配置基础上进行修改。
- 场景类型:猜你喜欢类型不会包含父物品侧特征;相关推荐类型可以包含父物品侧特征。在数据模块行为数据表 schema 有勾选父物品 id 字段条件下,才可以选择相关推荐类型。
选择行为与特征数据
- 行为数据表:批式样本只能选择 table 类数据表,流式样本只能选择消息队列类数据表;猜你喜欢类型只能选择包含 user 主键和 item 主键的数据表,相关推荐类型只能选择包含 user 主键、item 主键、p_item 主键的数据表。
- 特征来源:指拼接样本时特征值的来源。在线特征在有实时行为数据接入,且有关联特征的栏位上线后才可以选择。批式可以选择离线特征、在线特征;流式只可以选择在线特征。
- 如果特征来源是离线特征,需要手动选择需要的特征。如果特征来源是在线特征,则不需要再手动选择特征,可以直接查看当前所有栏位关联的所有在线特征。
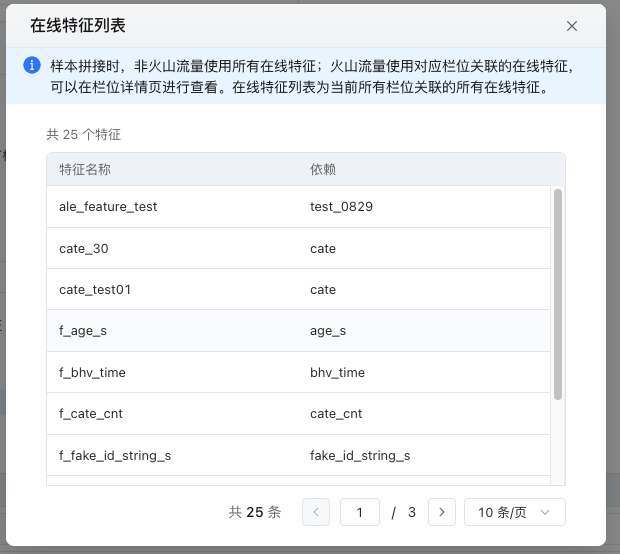
设置需要在样本中保留原始值的字段
辅助信息设置后模型代码中可以获取其对应字段的原始值,用于在模型代码中通过原始值过滤样本以及模型效果验证等场景。批式样本的辅助信息可以从样本特征所在数据表的所有字段中选择,流式样本的辅助信息可以从在线特征所对应的字段中选择。
单击【添加预置字段】和【添加自定义字段】可以增加辅助信息,两者均不允许添加相同名称的字段到辅助信息中,且辅助信息最多可填写20个。辅助信息支持的类型包含string、bigint、float、double、array
说明
- 用户新增自定义字段时,样本中字段名称的格式默认在原始字段名称前加 meta 前缀,【添加自定义字段】时可界面显示查看到样本中的字段名称的 meta 前缀。在后续【自定义模型】编辑代码时,支持 filter_by_feature_value 方法进行数据处理,代码中的样本字段名称同样有 meta 前缀。
- 用户新增预置字段时,辅助信息会同时写入两种,两种存储在样本字段名称的格式上存在 meta 前缀差异(一种在原始字段名称前加 meta 前缀,另一种和原始字段名称一致),【添加预置字段】时界面没有显示呈现(均未加 meta 前缀)。在后续【自定义模型】编辑代码时,用户可在 model.py 文件中选择使用 filter_by_fids 或 filter_by_feature_value 方法进行数据处理,两种方法存在如下差异:
- filter_by_fids:样本名称**不加 **meta 前缀存储时,后续模型代码中使用 filter_by_fids 方法处理数据。即【自定义模型】编辑代码时,model.py 文件首先声明使用 from monolith.native_training.data import filter_by_fids 方法,在代码中使用 filter_by_fids 方法进行数据处理。 该场景下,模型代码中的样本字段名称和原始字段名称一致。
- filter_by_feature_value(推荐使用):样本名称**加 **meta 前缀存储时,后续模型代码中使用 filter_by_feature_value 方法处理数据。即在【自定义模型】编辑代码时,在 model.py 文件首先声明使用 from monolith.native_training.data.feature_utils import filter_by_feature_value 方法,在代码中使用 filter_by_feature_value 方法进行数据处理。该场景下,模型代码中的样本字段名称格式在原始字段名称前加 meta 前缀。
- 单击【添加自定义字段】可自定义增加辅助信息,先选择原始字段中的行为表/物品表/用户表/其他表的具体字段,样本中的字段名称、样本中的字段类型将自动生成,且样本中的字段名称的格式默认为在原始字段名称前加 meta 前缀。对于已保存的样本,自定义辅助信息不支持编辑和删除,请确认后保存。
- 单击【添加预置字段】可增加已有的辅助信息,需要先选择样本中的字段名称,再选择原始字段(来源)。对于已保存的样本,预置的辅助信息仅支持编辑,不支持删除,请确认后保存。
预置字段明细如下表所示。
数据字段(来源) | 数据字段(来源)的字段类型 | 样本中的字段名称 | 样本中的字段类型 | 是否必填 | 信息说明 |
|---|---|---|---|---|---|
user_id | string | uid | int | 必填 | 所选行为数据源的用户主键字段。 |
item_id | bigint | item_id | bigint | 必填 | 所选行为数据源的物品主键字段。 |
bhv_time | int、bigint | generate_time | int、bigint | 必填 | 对应原始行为数据表的 bhv_time 字段。如果行为数据源是中间表,则根据实际情况选择。 |
req_time | int、bigint | req_time | int、bigint | 必填 | 对应原始行为数据表归因后的 req_time 字段,表示该条行为归因行为的发生时间。如果行为数据源是中间表,则根据实际情况选择。 |
bhv_type | string | actions | int | 必填 | 对应原始行为数据表的 bhv_type 字段。另需要保证行为类型枚举值和数据模块定义枚举值保持一致;过滤掉行为类型为空值的数据。 |
_final_request_id | string | req_id | string | 必填 | 对应原始行为数据表的 request_id 字段。如果行为数据源是中间表,则根据实际情况选择(支持流式样本后请使用系统生成的_final_request_id 字段)。 |
spm | string | page | string | 选填 | 对应原始行为数据表的 spm 字段。如果行为数据源是中间表,则根据实际情况选择。 |
scm | string | vid | string | 必填 | 对应原始行为数据表的 scm 字段。如果行为数据源是中间表,则根据实际情况选择。 |
ts | int、bigint | __meta__ts | int、bigint | 流式样本必填 | 用于确定流式样本dump的分区时间,一般选择行为表的ts字段(服务器接收到数据的秒级时间戳) |
video_play_time | int32、int64、float、double | video_play_time | int32、int64、float、double | 选填 | 对应原始行为数据表的 video_play_time 字段。如果行为数据源是中间表,则根据实际情况选择。 |
video_duration | int32、int64、float、double | video_duration | int32、int64、float、double | 选填 | 对应原始行为数据表或者原始物品表的 video_duration 字段。如果行为数据源是中间表,则根据实际情况选择 |
stay_time | int32、int64、float、double | stay_time | int32、int64、float、double | 选填 | 对应原始行为数据表的 stay_time 字段。如果行为数据源是中间表,则根据实际情况选择 |
publish_time | int、bigint | publish_time | int、bigint | 选填 | 表示发布时间的字段。例如商品发布时间、内容发布时间等。 |
price | float | price | float | 选填 | 对应数据源中 float 类型、可以代表价格的字段。 |
read_count | int | read_count | int | 选填 | 通常用于表示阅读的章节数。 |
进阶配置
**样本生成时间:**默认情况下批式样本是在天级行为的次日凌晨生成,现在可以在 1 天至 30 天范围内设置样本延后生成的时间。延后设置为 1 天则是基于次日向后顺延 1 天。假设今天是 1 月 1 日,正常样本生成任务是在 1 月 2 日凌晨执行,延后 1 天则样本生成任务在 1 月 3 日凌晨执行。
通常情况下,不需要修改此配置,但当某日的样本数据需要基于后续几天的数据进行修正时,可以配置样本的延后生成时间,当样本数据修正后才执行样本生成任务。
需要注意的是,样本一旦创建成功,则不能修改该配置,请谨慎选择。
流式样本 dump 成的批式样本不支持编辑,其他类型样本都支持编辑。可编辑范围包括修改样本备注,修改辅助信息;另外如果特征来源为离线特征,也支持添加特征。
特征来源为离线特征的批式样本可以执行生成历史样本。选择需要生成样本的时间范围。注意确认该时间范围在该样本关联行为数据源的时间分区范围内,且也在对应的特征集中原始特征关联的所有数据源的时间分区范围内。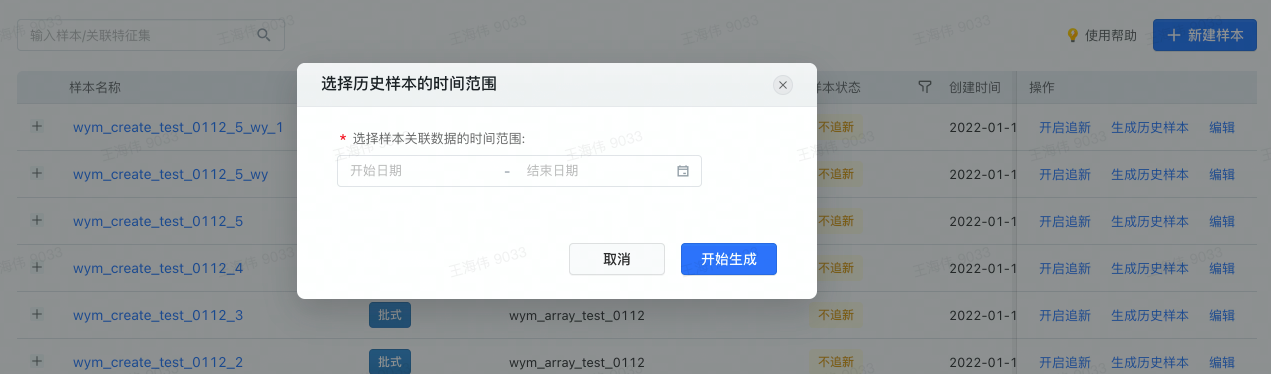
对批式样本开启追新,会从操作时间的第二天按照样本配置对操作当天及之后的数据生成样本;对流式样本开启追新,会从当前时刻按照样本配置开始生成样本。
样本状态为「实时追新」的流式样本可以在操作列执行【开始dump】操作,在弹框中输入 dump 到批式样本的名称,点击【开始dump】即把该流式样本dump成小时级追新的批式样本。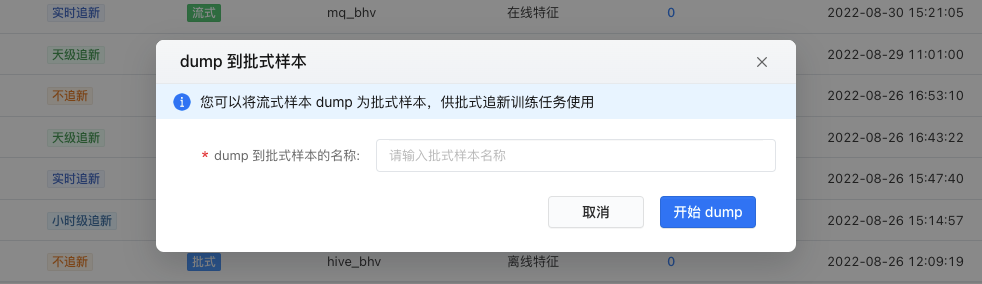
(1)批式样本若满足以下任何条件,不支持停止追新。
- 该样本关联模型训练任务的训练状态为「训练中」
- 该样本关联模型的发布状态为「已发布」
(2)流式样本若满足以下任务条件,不支持停止追新。
- 该样本关联模型训练任务的训练状态为「训练中」
- 该样本关联模型的发布状态为「已发布」
- 该流式样本 dump 的批式样本关联模型训练任务的训练状态为「训练中」
- 该流式样本 dump 的批式样本关联模型的发布状态为「已发布」
流式样本若满足以下任务条件,不支持停止 dump。
- 该流式样本 dump 的批式样本关联模型训练任务训练状态为「训练中」
- 该流式样本 dump 的批式样本关联模型发布状态为「已发布」
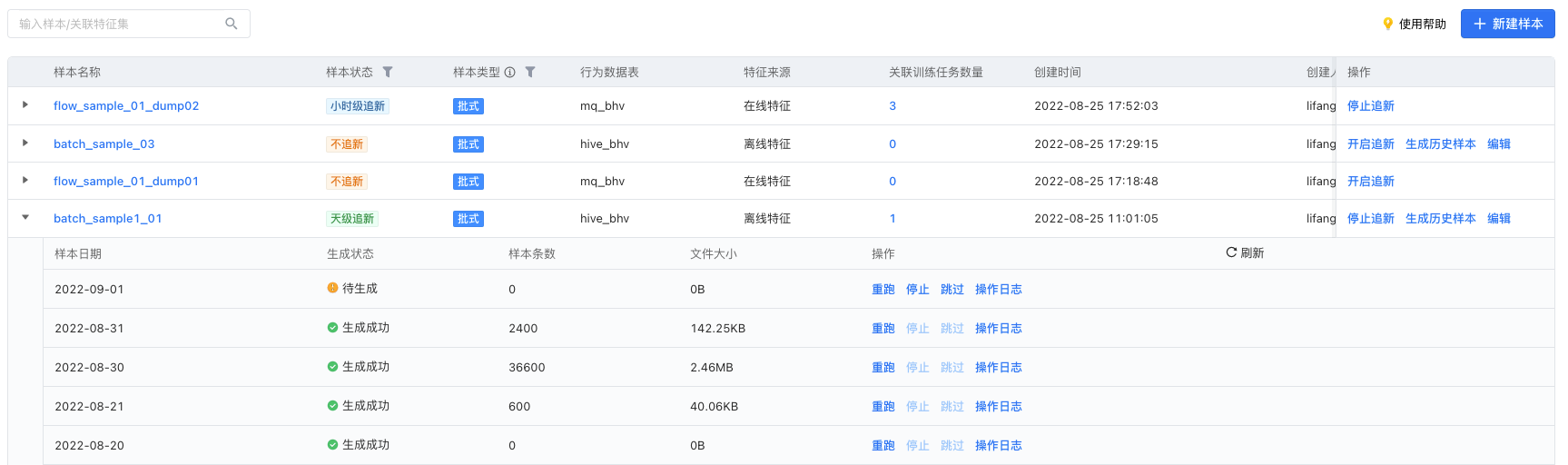
在对批式样本【开启追新】或执行【生成历史样本】后,可以点击样本最左侧的图标,查看该样本下的所有天级子样本。不同类型样本下的分区样本支持不同的操作。
- 特征来源为离线特征的批式样本:支持重跑、停止、跳过、查看日志。
- 流式样本 dump 生成的批式样本和流式样本:暂不支持操作,之后会支持查看日志,敬请期待。
查看样本数据
如果需要查询样本的明细数据,可以通过批式数据处理任务写 SQL 进行查询。目前所有批式样本数据均可通过这种方式查询。
查询样本数据与查询数据表数据时有两点不同:
- 查询样本时需要在样本表名称前增加 sample 前缀;
- 分区字段是 _fs_date 而不是 ds;
示例:查询样本名称为“tpl_batch_sample”中所有列并返回前10个结果,SQL 代码如下:
SELECT * FROM sample.tpl_batch_sample WHERE _fs_date = '${date}' LIMIT 10
对于不再需要的样本任务,建议及时归档,以保持列表中都是还在使用的样本任务。不同于删除,归档操作只会将选中的项目从列表中移除,使其不再可见,并不会真正将其从磁盘中删除。因此,您在新建样本任务时无法使用已归档的样本任务名称。