论文数据库结构设计图
 社区干货
社区干货
分布式数据库TiDB的设计和架构
也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。数据库技... 线性扩容及能够处理交易类事务的新型数据库,大数据的存储刚需不可避免。NewSQL的挑战在于,它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有...
分布式数据库TiDB的设计和架构
也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。# 数据库... 线性扩容及能够处理交易类事务的新型数据库,大数据的存储刚需不可避免。NewSQL的挑战在于,它是基于 Google Spanner/F1 论文,未开源它的代码及技术细节,是基础软件最前沿的领域之一,技术门槛最高。NewSQL 代表产品有...
[数据库论文研读] HTAP行列混存 & 智能转换
称为HTAP数据库罢了。这么做的话数据仍然要存两份(row & column),管控面的麻烦从外部转移到内部而已,并没有什么实际的架构创新。**所以,本论文提出了一种新的想法,**不再“分而治之”,而是要构建一个统一的存储层**,使用统一的data layout来管理表数据,这种layout里的“热数据”会针对OLTP特点优化存储结构,而“冷数据”会针对OLAP特点优化存储结构,然后根据时间推移或者query pattern的变化来自动迁移数据的存储结构。# Dat...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
论文链接:https://www.vldb.org/pvldb/vol16/p3528-chen.pdf **背景与介绍**上图是字节典型的广告后端架构,数据通过 Kafka 流入不同的系统。对于离线...
 特惠活动
特惠活动
 论文数据库结构设计图-优选内容
论文数据库结构设计图-优选内容
 论文数据库结构设计图-相关内容
论文数据库结构设计图-相关内容
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 数据排列结构如下图所示: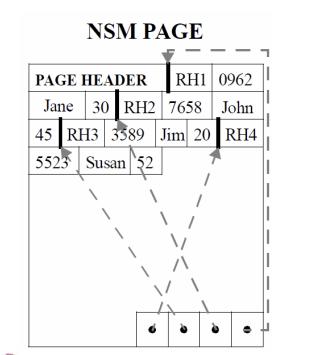列存和行存的区别主要是在存储时将多行数据的相同colum...
数据库表及视图
数据库和表概述数据库其实是数据的逻辑分组。每个数据库包含许多表和视图。表是存放数据的地方,由结构化的行和列组成。视图是依赖于表的保存的查询。当访问视图时,会在后台执行查询并返回结果。 数据库每个数据库都属于一个帐户。用户只能访问属于自己帐户的数据库(当拥有权限时) 创建数据库 sql CREATE DATABASE my_database01;注意 数据库名称中只能包含 字母数字 字符 a-z 0-9 和 下划线 _ 。所有名称将自动转换为 小写 。 ...
未来向量数据库的崛起与多元化场景创新 主赛道 | 社区征文
向量数据库越来越成为开发者关注的重点。## 一、概述:随着人工智能时代的来临,我们要更有效的解决图象、语音和视频等各种非结构化数据。这种信息往往有复杂的关系和模式,不能用传统...
火山引擎新一代数据库的探索与实践
数据库的形态也随之发生了很大变化,各类数据库不断涌现。在基础设施全面云原生化的今天,火山引擎的云原生数据库如何面对数亿日活应用访问下超过 EB 级别的海量存储规模?对于更复杂的非结构化数据类型,火山引擎的... **《云原生数据库 veDB 核心技术剖析与展望》**张雷|火山引擎数据库技术负责人veDB 是一款分布式数据库,采用了云原生计算存储分离架构。本次演讲将为大家介绍火山引擎这款云原生数据库的核心技术原理,并对未...
火山引擎ByteHouse:分析型数据库如何设计列式存储
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 列式存储通过支持按列存储数据,提供高性能的数据分析和查询。作为云原生数据仓库的 ByteHouse,也采用列式存储设计,保证读写性能、支持事务一致性,又适用大规模的数据计算,为用户提供极速分析体验和海量数据处理能力,提升企业数字化转型能力。# 列式存储介绍分析型数据库中的列式存储,是一种数据库的物理存储结构,它是根据数据的列...
字节跳动数据库的过去、现状与未来
如何在数据库领域进行数据管理和数据治理,成了摆在数据库团队面前的巨大难题。而在字节跳动内部,数据库建设主要面临三大挑战:**业务种类繁多。** 以抖音为例,为了管理用户之间复杂的社交关系,同时根据用户点赞、关注等行为进行智能推荐,我们需要用图进行管理。再如抖音电商商城设计订单、库存等数据,这些信息适合用关系型结构化的结构表达。除此之外抖音还存在大量结构化和非结构化数据,如用户上传的图片、视频,这些信息适合用...
火山引擎ByteHouse:分析型数据库如何设计并发控制?
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 分析型数据库设计并发控制的主要原因是为了确保数据的完整性和一致性,同时提高数据库的吞吐量和响应速度。并发控制可以... ByteHouse采取的存储计算分离结构,利用了成熟的高可用分布式文件系统或者对象存储(例如hdfs,S3),保证成功事务所提交数据的高可用。### 技术选型ByteHouse是一款分析型数据库(OLAP),跟事务型数据库(OLTP)在事务...
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
这种字段和数据都频繁变化的就不太适合设计链路过长和复杂的架构,后续维护这种架构会非常麻烦。但同时也不能过于简单,也要有一定的分层架构,不然耦合性太高,一旦源业务系统的业务规则发生变化将会影响整个数据清洗过程,并且对处理后的公共数据利用率也较低。2. 同时考虑字段频繁变化,后续数据存储时就要选择列可以随意增减,或者列增减成本不高的存储方案。我们考虑以上情况,发现Kappa架构还是较符合的,整体流程如图1