一张图看双十一数据库
 社区干货
社区干货
超复杂调用网下的服务治理新思路
第一个要点是微服务的数量。如果一个系统内的微服务数目只有几百个,那么绘制一张囊括所有微服务的调用图是有利于管理的;但如果超过了 1000 个,再把它们塞到一张图后整张图变得不可读,它的意义就不大了。第二点,... 如果用户想要在域外访问这个数据库,我们需要通过左下角的 Query、ETL 把它转化成一个离线数据库。整个大框是一个 domain,它不同于 DDD 的 domain,它被称为服务域,可以理解成是一组服务的集合。字节跳动内部也参考了...
字节跳动 NoSQL 的探索与实践
允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致可以分为以下几类:- KV 类:以 Redis 为代表;- 文档型:以 MongoDB 为代表;- 列存:以 HBase 为代表;- 图、时序等新兴的数据库也都属于 NoSQL 范畴。... 从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page ra...
字节跳动基于数据湖技术的近实时场景实践
Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fli... 接下来介绍一下抖音电商实时数仓团队在各类业务具体场景的实践案例。7. ## **分析型场景实践**### **营销大促**对于618、双11等购物节日,平台需要提前进行大促招商和资源提报,业务有当日分析和当日决策的需...
字节跳动 NoSQL 的探索与实践
作者:王佳毅|火山引擎存储&数据库解决方案负责人> 本文整理自火山引擎开发者社区技术大讲堂第三期演讲,主要为大家介绍了 NoSQL 的前世今生和发展脉搏,以及字节跳动 NoSQL 的实践。## NoSQL 应用的现状什么是... 从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page ra...
 特惠活动
特惠活动
 一张图看双十一数据库-优选内容
一张图看双十一数据库-优选内容
 一张图看双十一数据库-相关内容
一张图看双十一数据库-相关内容
字节跳动自研万亿级图数据库 & 图计算实践
自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性** ;作为一个工具,图数据对外提供的接口都... 这一节就来从内部实现来作进一步介绍。下面这张图展示了 ByteGraph 的内部架构,其中 bg 是 ByteGraph 的缩写。就像 MySQL 通常可以分为 SQL 层和引擎层两层一样,ByteGraph 自上而下分为 **查询层 (bgdb)** ...
VikingDB:大规模云原生向量数据库的前沿实践与应用
火山引擎向量数据库高级工程师 VikingDB 简介 ... 为开发者提供一站式AIGC API支持,让开发者更关注业务逻辑,助力开发者效能提升,降低业务创新周期。官网:https://www.aigcaas.cn**可用执行动作** * 创建一张图像人脸融合* 创建卡通化...
火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
血缘中涉及的元数据会冗余一份,并存储到图里。- 在血缘存储方面(见上图右边部分),除了图数据库之外,血缘本身也会依赖元数据的存储,如 Mysql 以及索引类存储。- 在血缘消费层面,第一版只支持通过 API 进行消... 并将第一个版本两张图融合成一张图,解决了无法通过表遍历字段血缘的问题。除此之外,第二个版本还**引入了任务类型节点**,服务于以下三种遍历场景:- **单纯遍历数据血缘**,即从数据节点到数据节点。- **数...
字节跳动 NoSQL 的探索与实践
允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致可以分为以下几类:* **KV 类**:以 Redis 为代表;* **文档型**:以 MongoDB 为代表;* **列存**:以 HBase 为代表;* **图、时序等新兴的数据库**... 从图数据库又引申出来一个非常大的概念——图计算。举个例子,在 Google 上搜索时,需要基于网页的链接关系计算每个页面的 page rank,从而对页面进行排序。页面的链接关系其实就是一张图,基于网页链接关系的 page ra...
分布式数据库在抖音春晚活动中的应用
## 分布式数据库架构简介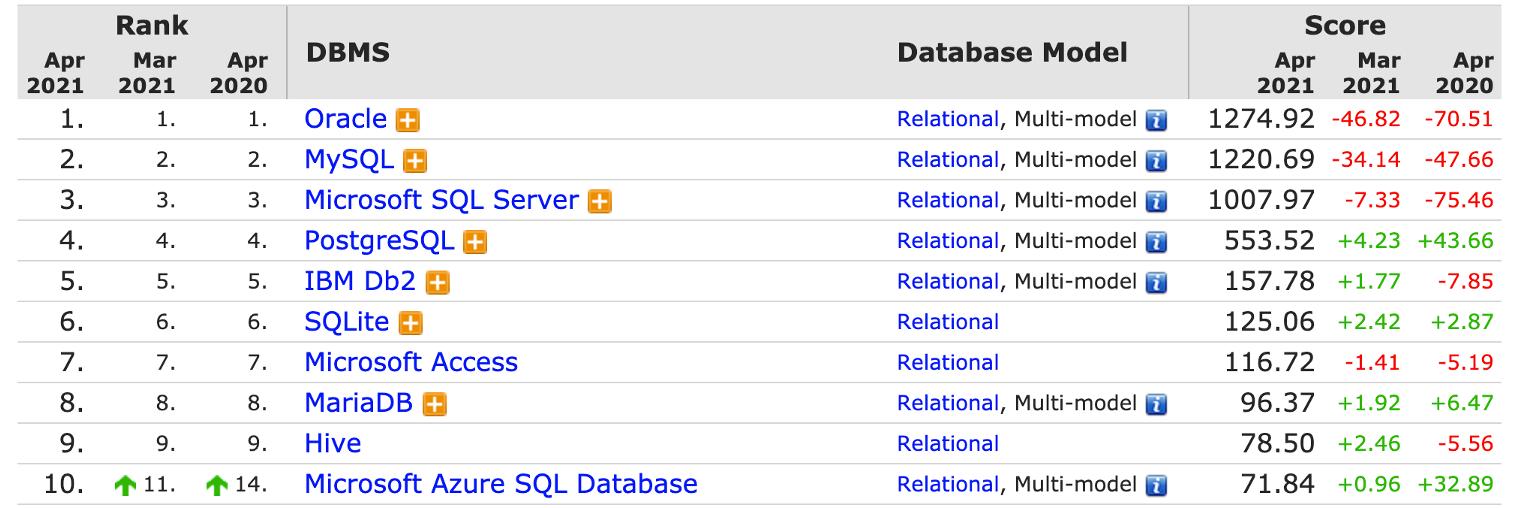相信对数据库感兴趣的同学对上面这张图也不会陌生。这张图是 DB Engines 的数据库排名,准确来说是一个关系型数据库的排名。在 2021 年 4 月份的榜单上,MySQL 和 PG 都是关系型数据库的 Top5。这就意味着,如果我们想做一款数据库产品,大概率永远都绕不过 MySQL 和 PG 的生...
干货|数据湖技术在抖音近实时场景的实践
具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。* Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS)* H... 接下来介绍一下抖音电商实时数仓团队在各类业务具体场景的实践案例。分析型场景实践### **营销大促**对于618、双11等购物节日,平台需要提前进行大促招商和资源提报,业务有当日分析和当日决策的需...
字节跳动基于数据湖技术的近实时场景实践
Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(F... 接下来介绍一下抖音电商实时数仓团队在**各类业务具体场景**的实践案例。## **3.1 分析型场景实践****(1)营销大促**对于618、双11等购物节日,平台需要提前进行大促招商和资源提报,业务有当日分析和当日决策的...
分布式数据库在抖音春晚活动中的应用
分布式数据库架构简介 相信对数据库感兴趣的同学对上面这张图不会陌生。这张图是 DB Engines 的数据库排名,准确来说是一个关系型数据库的排名。在 2021 年 4 月...
