Spark是逐行还是同时执行转换操作的?
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
就可以开始正式执行 spark 应用程序了。第一步是创建 RDD,读取数据源;> - HDFS 文件被读取到多个 Worker节点,形成内存中的分布式数据集,也就是初始RDD;> - Driver会根据程序对RDD的定义的操作,提交 Task 到 Exec... Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间...
干货|字节跳动数据技术实战:Spark性能调优与功能升级
为后续更清晰的介绍我们在Spark上做的系列优化,此处简单说明一些相关的基本概念。 **●** **一个SQL是如何执行的?**========================首先,结合下面的示例图,一个SQL会被Spark引擎经过... 会加一个Operator算子去检测产出的分区中是否存在小文件,然后仅对存在小文件的分区进行文件合并。如下右图,检测到event=B和event=C分区存在小文件,仅会对这两个分区中的文件做合并,event=A分区不会做任何操作。==...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
Spark 组件由于其较好的容错与故障恢复机制,在企业的长时作业中使用的非常广泛,而SparkSQL又是使用Spark组件中最为常用的一种方式。 相比直接使用编程式的方式操作Spark的RDD或者DataFrame的API,SparkSQL可直接... ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中没有的能力,例如实时的日志获取,但是使用这个能力的时候需要将对应的实现类转换为Hi...
字节跳动 MapReduce - Spark 平滑迁移实践
本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与... 在迁移过程中某些 MapReduce 参数应该如何转化为等效的 Spark 参数,以及如何等效的在 Spark 中实现 Hadoop Streaming 作业脚本依赖的环境变量注入等问题,这些问题如果交给用户解决,不仅工作量大,失败率也很高。...
 特惠活动
特惠活动
 Spark是逐行还是同时执行转换操作的?-优选内容
Spark是逐行还是同时执行转换操作的?-优选内容
 Spark是逐行还是同时执行转换操作的?-相关内容
Spark是逐行还是同时执行转换操作的?-相关内容
字节跳动 MapReduce - Spark 平滑迁移实践
本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,... 在迁移过程中某些 MapReduce 参数应该如何转化为等效的 Spark 参数,以及如何等效的在 Spark 中实现 Hadoop Streaming 作业脚本依赖的环境变量注入等问题,这些问题如果交给用户解决,不仅工作量大,失败率也很高。...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
Spark 组件由于其较好的容错与故障恢复机制,在企业的长时作业中使用的非常广泛,而SparkSQL又是使用Spark组件中最为常用的一种方式。 相比直接使用编程式的方式操作Spark的RDD或者DataFrame的API,SparkSQL可直... ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中缺乏的能力,例如实时的日志获取。但是使用该能力时,需要将对应的实现类转换为Hive...
揭秘字节跳动云原生 Spark History 服务 UIService
将它们逐行反序列化,并使用 ReplayListener 将其中信息反馈到 KVStore 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 KVStore 中,KVStore 是 Spark 中... 写的是序列化的 event;而`UIMetaLoggingListener`只会被特定的 event 触发,目前是只会被stageEnd,JobEnd 事件触发,但每次写操作是批量的写,将上一阶段的 `UIMetaStore` 的信息完整地持久化。做一个类比,`EventLo...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
火山引擎 LAS 团队将向大家详细介绍字节跳动内部是怎么基于 UIMeta 实现海量数据业务的平稳和高效运转,让技术驱动业务不断发展。# **1. 业务背景**## 1.1 开源 Spark History Server 架构为了能够更好理解本... 将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 `KVStore`中,`KVStore`是 Spark ...
火山引擎基于 Zeppelin 的 Flink/Spark 云原生实践
文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路、火山引擎云原生计算研发工程师-王正# Apache Zeppelin 介绍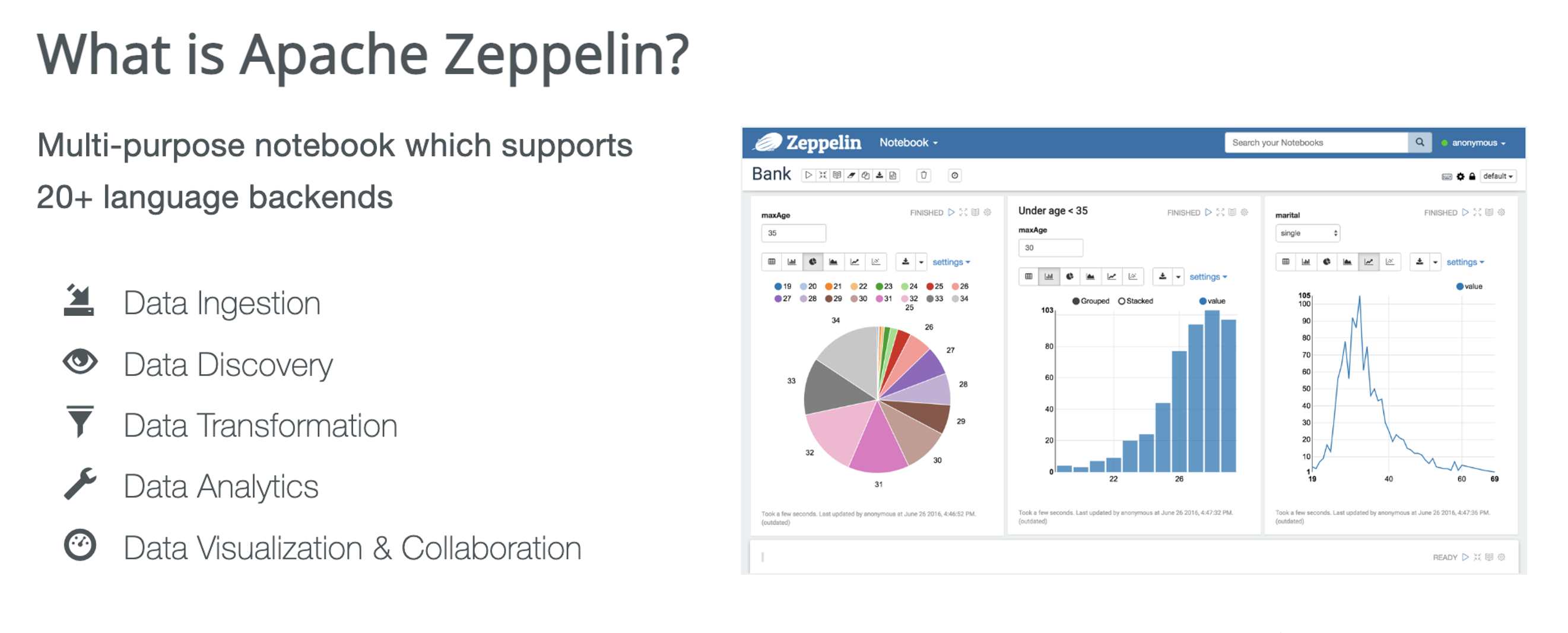Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,...
基于 Zeppelin 的 Flink/Spark 云原生实践
文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路 火山引擎云原生计算研发工程师-王正**01** **Apache Zeppelin ... Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,如饼图、柱状图、折线图等。典型使用场景是通过开发 Zeppelin 的代码片段或者 SQL,通过...
揭秘|UIService:字节跳动云原生 Spark History 服务
解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 `KVStore`中,`KVStore`是 Spark 中基于内存的KV存储,可以存储任意的类实例。前端会从`KVStore`查询所需的对象,实现页面的渲染。 ## 1.2 **痛点**### **1....
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 `KVStore`中,`KVStore`是 Spark 中基于内存的KV存储,可以存储任意的类实例。前端会从`KVStore`查询所需的对象,实现页面的渲染。痛点* #### **...
揭秘|UIService:字节跳动云原生Spark History 服务
解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使用 `ReplayListener`将其中信息反馈到 `KVStore` 中,还原任务的状态。无论运行时还是 History Server,任务状态都存储在有限几个类的实例中,而它们则存储在 `KVStore`中,`KVStore`是 Spark 中基于内存的KV存储,可以存储任意的类实例。前端会从`KVStore`查询所需的对象,实现页面的渲染。 **痛点...
