spark使用神经网络
 社区干货
社区干货
干货|字节跳动数据技术实战:Spark性能调优与功能升级
文章会为大家讲解字节跳动 **在Spark技术上的实践** ——LAS Spark的基本原理,分析该技术相较于社区版本如何实现性能更高、功能更多,为大家揭秘该技术做到极致优化的内幕,同时,还会为大家带来团队关于LAS Spark技... 主要适用分区数据量均匀的场景,即每个分区的总数据量差异不大,且分区内部均有小文件。这种场景主要是因为Spark任务的最后一个stage并行度较大导致,如下左图,InsertInto之前的最后一个Operator的并行度为7,则最终也...
字节跳动 Spark Shuffle 大规模云原生化演进实践
Shuffle 是用户作业中会经常触发的功能,各种 ReduceByKey、groupByKey、Join、sortByKey 和 Repartition 的操作都会使用到 Shuffle。所以在大规模的 Spark 集群内,Spark Shuffle 经常会成为性能及稳定性的瓶颈;Shuffle 的计算也会涉及到频繁的磁盘和网络 IO 操作,解决办法是需要把所有节点的数据进行重新分区并组合。下文将详细介绍字节跳动在 Spark Shuffle 云原生化方向的大规模演进实践。### **Spark** **Shuffle 原理介绍*...
字节跳动 Spark 支持万卡模型推理实践|CommunityOverCode Asia 2023
上层应用管理还是底层的网络、存储等,在管理中都有非常多的可选方案,为 Spark 的云原生化使用提供了便利。 **字节跳动 Spark 规模**... ArceeApplication 用于描述具体的作业,ArceeCommand 描述用于作业的操作;Webhook 模块,主要用于 Application / Pod 的配置注入和校验;Application Manager 负责作业的生命周期管理;PodSetManager 是作业资源管理;E...
基于 Zeppelin 的 Flink/Spark 云原生实践
我们通过裁剪只包含 Flink 和 Spark 的部分,同时利用 Docker 镜像的多阶段构建技术,达到镜像缩小、体积缩小的目的,实现镜像层数的缩减;* **元数据** **存储**:Zeppelin 包含多种元数据,其中重要的元数据 Notebook 可以支持本地文件的存储、远程存储、对象存储等;在扩展之后能够支持火山引擎 TosNotabookRepo 的对象存储;另外一种存储则需要借助 K8s 里的 Persistent Volume 机制,将一块磁盘/云盘,映射成固定的 Volume 挂载到...
 特惠活动
特惠活动
 spark使用神经网络-优选内容
spark使用神经网络-优选内容
 spark使用神经网络-相关内容
spark使用神经网络-相关内容
字节跳动 MapReduce - Spark 平滑迁移实践
本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角度来看,MapReduce 引擎的运维和使用也都存在着一系列问题。在此背景下,字节跳动 Batch 团队设计并实现了一套 MapReduce 任务平滑迁...
字节跳动 MapReduce - Spark 平滑迁移实践
本文整理自字节跳动基础架构工程师魏中佳在本次 CommunityOverCode Asia 2023 中的《字节跳动 MapReduce - Spark 平滑迁移实践》主题演讲。随着字节业务的发展,公司内部每天线上约运行 100万+ Spark 作业,与之相对比的是,线上每天依然约有两万到三万个 MapReduce 任务,从大数据研发和用户角度来看,MapReduce 引擎的运维和使用也都存在着一系列问题。在此背景下,字节跳动 Batch 团队设计并实现了一套 MapReduce 任务平滑迁...
资源池管理
Spark 资源池是项目中用来管理计算资源的,资源池中的计算资源相互隔离,相互独立。 前提条件创建资源池时所使用的私有网络、子网、安全组,都需要提前创建。相关文档,请参见创建私有网络。说明 Spark 任务的每个任务实例(Pod)会占用 1 个子网 IP 和 1 个辅助 ENI。请确保当前资源池所属私有网络下的子网 IP 和辅助 ENI 有充足余量,否则会导致任务数受限。 默认只有主账号、项目负责人和项目管理员有权限管理 Spark 资源池。请确保...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
也就是说会存在大量的网络请求,量级大概是 M 乘以 R,这个请求的数量级也是非常大的。这两个问题随着作业规模的扩大,会带来越来越严重的 Shuffle Failure 问题。Shuffle Failure 意味着超时,Shuffle Failure 本身还有可能导致 Stage 重算,甚至导致作业失败,严重影响批式作业的稳定性,同时还会浪费大量的计算资源(因为 Fetch 等待超时的时候,CPU 是空闲的)。## Spark 在字节跳动的应用在字节跳动内部,Spark 作业规模较大:-...
火山引擎基于 Zeppelin 的 Flink/Spark 云原生实践
Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路、火山引擎云原生计算研发工程师-王正# Apache Zeppelin 介绍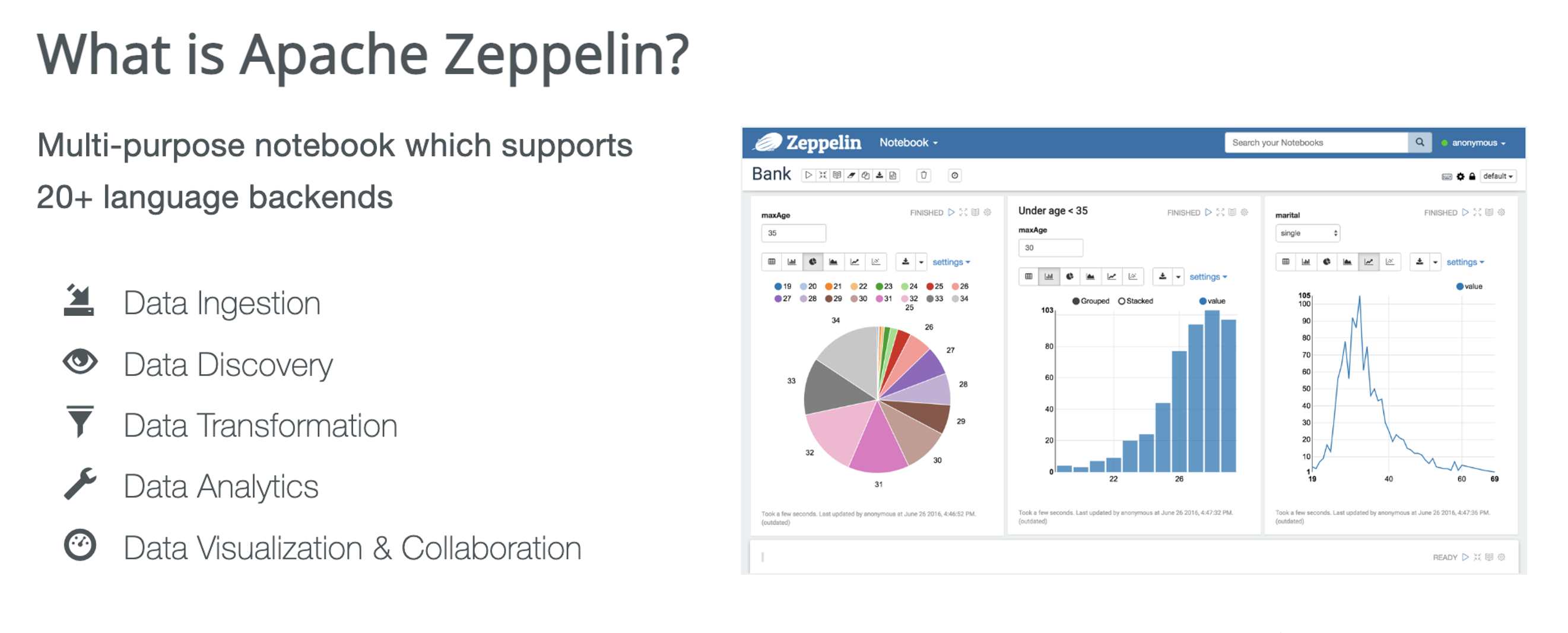Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,如饼图、柱状图、折线图等。典型使用场景是通过...
字节跳动 Spark 支持万卡模型推理实践
上层应用管理还是底层的网络、存储等,在管理中都有非常多的可选方案,为Spark的云原生化使用提供了便利。**字节跳动 Spark 规模及云原生化挑战**对 VCI 进行参数配置。详情请参见 Pod Annotation 说明。 前提条件本地已安装 kubectl 工具。详细操作,请参见 kubectl 安装指导。 本地已安装 Helm 工具。详细操作,请参见 Helm 安装指导。 创建集群前,需要确保已完成准备工作。详细情况,请参见 准备工作。 已开通弹性容器实例。详细操作,请参见 VCI 入门指引。 步骤一:创建 VPC-CNI 容器网络模型...
Cloud Shuffle Service 在字节跳动 Spark 场景的应用实践
也就是说会存在大量的网络请求,量级大概是 M 乘以 R,这个请求的数量级也是非常大的。这两个问题随着作业规模的扩大,会带来越来越严重的 Shuffle Failure 问题。Shuffle Failure 意味着超时,Shuffle Failure 本身还有可能导致 Stage 重算,甚至导致作业失败,严重影响批式作业的稳定性,同时还会浪费大量的计算资源(因为 Fetch 等待超时的时候,CPU 是空闲的)。 **Spark 在字节跳动的应****用**在字节跳动内...
