spark使用tensorflow
 社区干货
社区干货
字节跳动正式开源分布式训练调度框架 Primus
> 项目地址:https://github.com/bytedance/primus 随着机器学习的发展,模型及训练模型所需的数据量越来越大,也都趋向于通过分布式训练实现。而算法工程师通常需要对这些分布式框架涉及到的底层文件存储和调度系统有较深的理解,才能够快速批量开启模型训练,保证资源利用率。目前业界有很多类似的框架,如 TonY、TensorFlowOnSpark,Kubeflow 中的 Training Operators 等,但这些框架或多或少存在某些问题,如与固定的机器学习...
字节跳动 Spark 支持万卡模型推理实践|CommunityOverCode Asia 2023
字节内部探索 Spark 从 Hadoop 迁移到 Kubernetes 对作业的云原生化运行。字节跳动的大数据资源管理架构和 Spark 的部署演进大致可分为三个阶段:* 第一个阶段是完全基于 YARN 的离线资源管理,通过大规模使用 ... Spark 云原生技术方案目前主流的使用方式包括 Spark Native 和 Google 开源的 Spark Operator 两种方式。两种方式殊途同归,最终都是调用 Spark-submit 命令行工具。不同的是,Google 的 Spark Operator 支持了更加丰...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
### 1. 开篇2023年即将过去,又到了一年一度的技术总结时刻,在这一年,参与了多个大数据项目的开发建设工作,也参与了几个数仓项目的治理优化工作,在这么多的项目中,让我印象比较深刻的就是在使用Spark引擎执行任务出现的报错现象,接下来就回顾复盘下这次任务报错现象及具体的解决方案。### 2. 问题描述因为现在大多数的批量任务都是使用Spark去执行,所以Spark的地位在公司是举足轻重,那么对于Spark的深入理解和优化显得尤为重...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
## 一、Spark 架构原理 | 对源RDD和参数RDD求并集后返回一个新的RDD|intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD...
 特惠活动
特惠活动
 spark使用tensorflow-优选内容
spark使用tensorflow-优选内容
 spark使用tensorflow-相关内容
spark使用tensorflow-相关内容
干货|字节跳动数据技术实战:Spark性能调优与功能升级
文章会为大家讲解字节跳动 **在Spark技术上的实践** ——LAS Spark的基本原理,分析该技术相较于社区版本如何实现性能更高、功能更多,为大家揭秘该技术做到极致优化的内幕,同时,还会为大家带来团队关于LAS Spark技... 如果依然使用 MergeFile增加整体Shuffle的方式,则无法为每个分区都产出合适的文件大小,虽然也可以解决小文件问题,但部分分区文件则会过大,同时还会引入比较大的性能损耗。======================================...
数据中台的学习与总结 主赛道 | 社区征文
数据分析:通过 Spark、Hadoop 等分布式计算框架,对海量数据进行实时或离线的分析处理,提取用户画像、商品特征、评价情感等有价值的信息,并进行可视化展示。- 数据建模:通过 TensorFlow、PyTorch 等深度学习框架,构建基于卷积神经网络(CNN)、循环神经网络(RNN)、长长短期记忆网络(LSTM)等模型,实现对用户行为和商品属性之间关系的建模,并进行训练和测试。- 数据服务:通过 Kafka、Flume 等消息队列系统,将推荐结果以及其...
Kernel 类型之 Python Spark on EMR 实践
支持使用 Python、Markdown 语言、引入第三方库完成数据查询操作。本文将为您演示 Notebook 任务类型中使用 Python Spark on EMR 的 Kernel 类型。 2 注意事项若仅开通 DataLeap 产品大数据集成服务时,不支持创建 Notebook 查询类型。详见版本服务说明。 Notebook 查询作业中,Python Spark on EMR 的 Kernel 类型,仅支持火山引擎 E-MapReduce(EMR)Hadoop、TensorFlow 集群类型创建。 3 准备工作已开通相应版本的 DataLeap 服务并...
基于Spark的词频统计
实验介绍 本次实验练习介绍了如何在虚拟机内进行批示计算Spark的词频统计类型的数据处理。在开始实验前需要先进行如下的准备工作: 下载并配置完成虚拟机。 在虚拟机内已完成Hadoop环境的搭建。 关于实验 预计部署时... 使用sbt对程序进行打包操作,执行vim simple.sbt,输入如下所示内容: bash name := "Simple Project"version := "1.0"scala Version := "2.11.8"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1...
字节跳动正式开源分布式训练调度框架 Primus
TensorFlowOnSpark,Kubeflow 中的 Training Operators 等,但这些框架或多或少存在某些问题,如与固定的机器学习框架( Tensorflow,Pytorch )耦合需要写明例如 PS、Worker 等角色,容错和弹性调度支持不友好,不支持异构调度,调度语义较为简单,不支持文件读取等。****将算法工程师从此类繁重的底层细节中解脱出来、更多地关注到算法层面,即为 Primus 解决的问题。******日均作业百万核的字节跳动实践**经过...
字节跳动正式开源分布式训练调度框架 Primus
TensorFlowOnSpark,Kubeflow 中的 Training Operators 等,但这些框架或多或少存在某些问题,如与固定的机器学习框架( Tensorflow,Pytorch )耦合需要写明例如 PS、Worker 等角色,容错和弹性调度支持不友好,不支持异构调度,调度语义较为简单,不支持文件读取等。**将算法工程师从此类繁重的底层细节中解脱出来、更多地关注到算法层面,即为** **Primus** **解决的问题。** 日均作业百万核的字节跳动实践==============经过字...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中缺乏的能力,例如实时的日志获取。但是使用该能力时,需要将对应的实现类转换为Hive...
火山引擎基于 Zeppelin 的 Flink/Spark 云原生实践
Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路、火山引擎云原生计算研发工程师-王正# Apache Zeppelin 介绍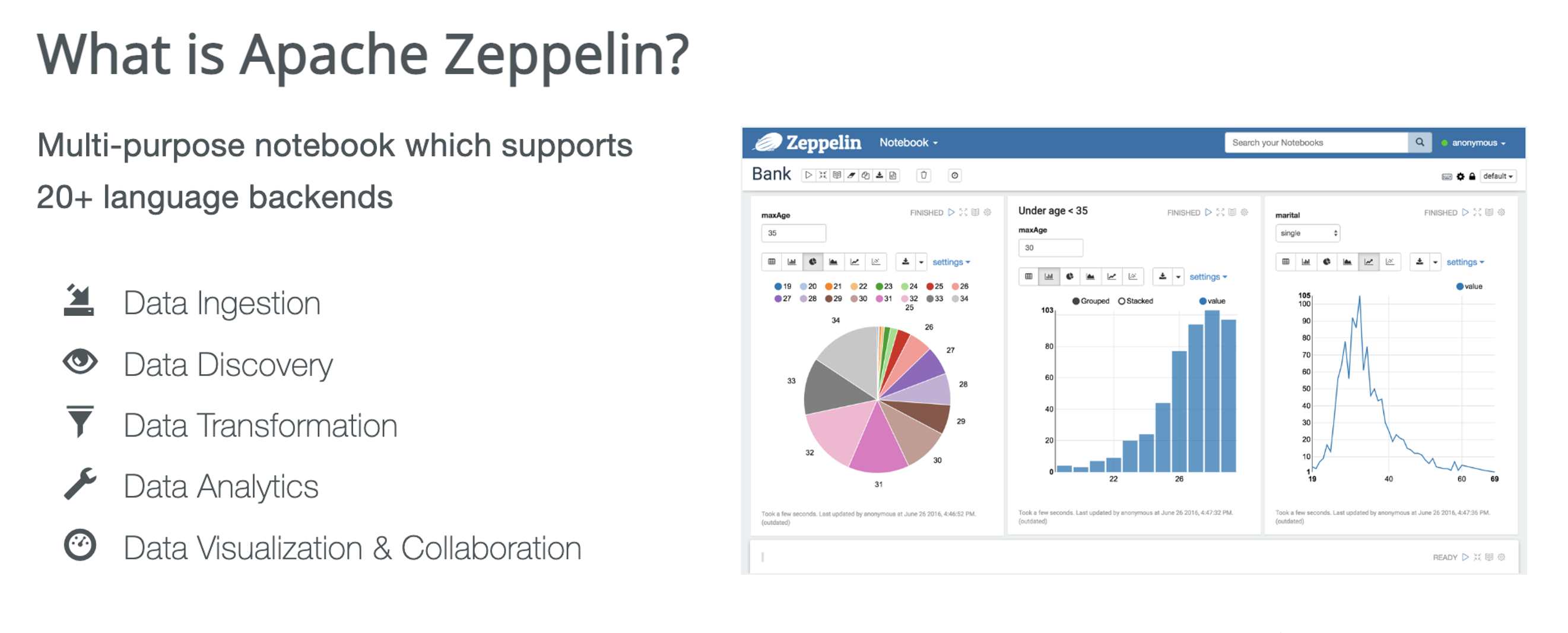Apache Zeppelin 是一个支持 20 多种语言 Notebook 的后端,可以用于数据摄入、发现、转换及分析,也能够实现数据的可视化,如饼图、柱状图、折线图等。典型使用场景是通过...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... ```在HiveConnection类中实现了将Java中定义的SQL访问接口转化为调用Hive Server2的RPC接口的实现,并且扩充了一部分Java定义中没有的能力,例如实时的日志获取,但是使用这个能力的时候需要将对应的实现类转换为Hi...
