spark是用tensorflow
 社区干货
社区干货
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
### 1. 开篇2023年即将过去,又到了一年一度的技术总结时刻,在这一年,参与了多个大数据项目的开发建设工作,也参与了几个数仓项目的治理优化工作,在这么多的项目中,让我印象比较深刻的就是在使用Spark引擎执行任务出现的报错现象,接下来就回顾复盘下这次任务报错现象及具体的解决方案。### 2. 问题描述因为现在大多数的批量任务都是使用Spark去执行,所以Spark的地位在公司是举足轻重,那么对于Spark的深入理解和优化显得尤为重...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
## 一、Spark 架构原理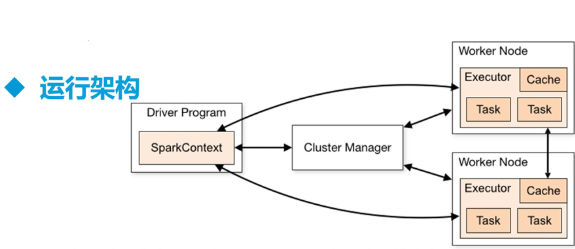> SparkContext 主导应用执行> > Cluster Manager 节点管理器> > 把算子RDD发送给 Worker Node> > Cache : Worker Node 之间共享信息、通信> > Executor 虚拟...
字节跳动 Spark 支持万卡模型推理实践|CommunityOverCode Asia 2023
文章来源|字节跳动云原生计算团队 本文整理自字节跳动基础架构工程师刘畅和字节跳动机器学习系统工程师张永强在本次 CommunityOverCode Asia 2023 中的《字节跳动 Spark 支持万卡模型推理实践》... Tensorflow 等常见的模型推理,同时也支持 Partition 级别的 Checkpoint。这样在资源回撤的时候就不需要重复计算了,能够避免算力的浪费,并通过支持 Batching 可以提高整体的资源利用率。 **平台建设** 特惠活动
特惠活动
 spark是用tensorflow-优选内容
spark是用tensorflow-优选内容
 spark是用tensorflow-相关内容
spark是用tensorflow-相关内容
字节跳动 Spark 支持万卡模型推理实践
> 本文整理自字节跳动基础架构工程师刘畅和机器学习系统工程师张永强在本次 CommunityOverCode Asia 2023 中的《字节跳动 Spark 支持万卡模型推理实践》主题演讲。在云原生化的发展过程中 Kubernetes 由于其强大... Tensorflow 等常见的模型推理,同时也支持 Partition 级别的 Checkpoint。这样在资源回撤的时候就不需要重复计算了,能够避免算力的浪费,并通过支持 Batching 可以提高整体的资源利用率。 ...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... 构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
构建SparkSQL服务器最好的方式是用如上Java接口,且大数据生态下行业已有标杆例子,即Hive Server2。Hive Server2在遵循Java JDBC接口规范上,通过对数据操作的方式,实现了访问Hive服务。除此之外,Hive Server2在实现上,与MySQL等关系型数据稍有不同。首先,Hive Server2本身是提供了一系列RPC接口,具体的接口定义在org.apache.hive.service.rpc.thrift包下的TCLIService.Iface中,部分接口如下:```public TOpenSessionResp OpenSe...
基于Spark的词频统计
实验介绍 本次实验练习介绍了如何在虚拟机内进行批示计算Spark的词频统计类型的数据处理。在开始实验前需要先进行如下的准备工作: 下载并配置完成虚拟机。 在虚拟机内已完成Hadoop环境的搭建。 关于实验 预计部署时间:90分钟级别:初级相关产品:批式计算Spark受众:通用 操作步骤 步骤一:安装并配置批示计算Spark1.执行以下命令完成Spark的下载及安装bash wget https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop...
火山引擎基于 Zeppelin 的 Flink/Spark 云原生实践
> 本文整理自火山引擎基础架构研发工程师陶克路、王正在 ApacheCon Asia 2022 上的演讲。文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路、火山引擎... Flink on Zeppelin 的工作基本都是用解释器实现的,Flink 的解释器大体上可分为两种,FlinkCmd 解释器和其他 Flink 解释器。- **FlinkCmd 解释器**顾名思义就是用命令行的方式提交 Flink 程序; 在字节跳动 Spark 场景下的设计与实现。作者|字节跳动基础架构的大数据开发工程师-魏中佳# 背景介绍在大数据场景下,数据 Shuffle 表示了不同分区数据交换的过程,Shuffle 的性能往往会成为作业甚至整个集群的性能瓶颈。特别是在字节跳动每日上百 PB Shuffle 数据的场景下,Shuffle...
Kernel 类型之 Python Spark on EMR 实践
本文将为您演示 Notebook 任务类型中使用 Python Spark on EMR 的 Kernel 类型。 2 注意事项若仅开通 DataLeap 产品大数据集成服务时,不支持创建 Notebook 查询类型。详见版本服务说明。 Notebook 查询作业中,Python Spark on EMR 的 Kernel 类型,仅支持火山引擎 E-MapReduce(EMR)Hadoop、TensorFlow 集群类型创建。 3 准备工作已开通相应版本的 DataLeap 服务并创建 DataLeap 项目。详见开通服务操作。 Notebook 任务使用 Pyth...
喜讯!火山引擎 Flink、Spark 产品通过信通院可信大数据能力评测
1月4日,在第五届“数据资产管理大会”上,中国信息通信研究院(中国信通院)公布了第十五批“可信大数据”产品能力评测结果。**火山引擎流式计算 Flink 版和火山引擎批式计算 Spark 版**凭借出色的基础能力、优秀的性能和稳定性及安全能力,分别通过**分布式流处理平台基础能力评测、分布式批处理平台基础能力评测。** “可信大数据”产品能力评测旨在从基础能力、性能、稳定性、安全能力等维度对企业级大数据产品展开全方位的...
字节跳动 Spark Shuffle 大规模云原生化演进实践
## 背景Spark 是字节跳动内部使用广泛的计算引擎,已广泛应用于各种大规模数据处理、机器学习和大数据场景。目前中国区域内每天的任务数已经超过 150 万,每天的 Shuffle 读写数据量超过 500 PB。同时某些单个任务的 Shuffle 数据能够达到数百 TB 级别。与此同时作业量与 Shuffle 的数据量还在增长,相比去年,今年的天任务数增加了 50 万,总体数据量的增长超过了 200 PB,达到了 50% 的增长。Shuffle 是用户作业中会经常触发的功...
