用SPARQL查询找到三元组的行号
 社区干货
社区干货
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对各种 Workload 的系统,对于不同的 Workload,系统的各个组件都可以自由的进行伸缩。...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
限制算力资源的有效利用率。所以我们需要寻找方法来提高样本的读取吞吐量,确保可以充分利用现有的算力资源。最后,在深度学习的加持下特征工程已经变得更加自动化和简化,我们可以顺应趋势进一步 **提高特征调... 用户只需要提供行号、主键和回填列数据信息即可,极大避免了读写放大问题,实现轻量级更新。读的时候数据文件和更新文件可以一并读出,并进行读时合并、共同应用到更新和加列中。Iceberg 的树状元数据表达力强,能...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对各种 Workload 的系统,对于不同的 Workload,系统的各个组件都可以自由的进行伸缩。...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
限制算力资源的有效利用率。所以我们需要寻找方法来提高样本的读取吞吐量,确保可以充分利用现有的算力资源。最后,在深度学习的加持下特征工程已经变得更加自动化和简化,我们可以顺应趋势进一步**提高特征调研和工... 用户只需要提供行号、主键和回填列数据信息即可,极大避免了读写放大问题,实现轻量级更新。读的时候数据文件和更新文件可以一并读出,并进行读时合并、共同应用到更新和加列中。Iceberg 的树状元数据表达力强,能够...
 特惠活动
特惠活动
 用SPARQL查询找到三元组的行号-优选内容
用SPARQL查询找到三元组的行号-优选内容
 用SPARQL查询找到三元组的行号-相关内容
用SPARQL查询找到三元组的行号-相关内容
Kafka 消息传递详细研究及代码实现|社区征文
## 背景新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事... 整个查询过程基于二分法,顺序为: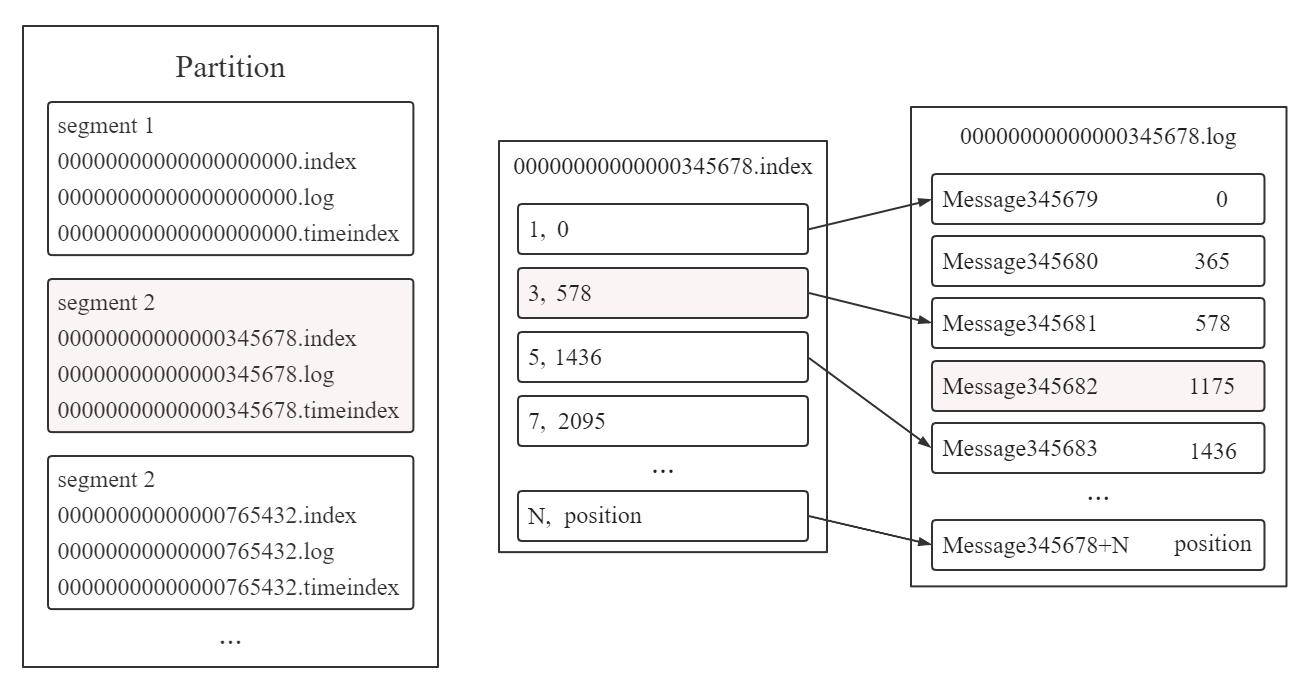(1) 利用二分法找到小于 345682 且离其最近的...
一文理解 HyperLogLog(HLL) 算法 | 社区征文
并找出其中的最高分 *μ*。那么这组数据的基数的期望为: N = 2^μ 这就是利用概率论来估算基数所依据的基本原理。在上述过程中涉及了一个重要步骤,就是将每个待观察的数据进行 hash 操作。为什么需要 hash 操作,... 根据算法的特点,通常将分桶数 m 设为 2 的整数次幂。例如 m=64=2^6,此时可以通过 hash 值的前 6 个 bit 来表示桶编号。从第 7 个 bit 开始统计前导零个数。# HyperLogLog 算法LogLog 算法通过「分桶求平均值」...
EMR 存算分离JobCommitter最佳实践
组合完成,意味着当需要对一个大文件进行rename时,在对象存储中是先将此文件进行拷贝,再删除原文件,相比于HDFS来说,多了一次完整的文件写入时间。因此如果不做任何优化,使用对象存储作为存储介质,相比于HDFS在性能上将会慢一倍以上,Job Committer便是在这个背景,提升写入对象存储速度的一种手段。Job Committer借助了对象存储的MPU(MultipartUpload)能力,将一个大文件切分成多个分片,给每一个分片编号,并行上传,当所有分片上传完成...
