用Sparql查询获取一个人的数据
 社区干货
社区干货
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
## 一、Spark 架构原理 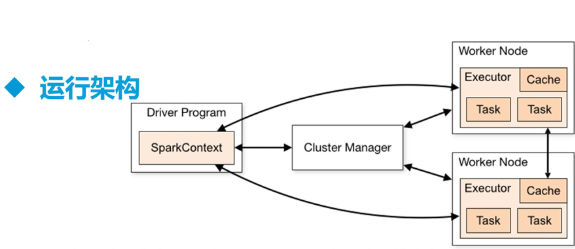 > SparkContext 主导应用执行 > > Cluster Manager 节点管理器 > > 把算子RDD发送给 Worker Node > > Cache : Worker Node 之间�
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。** # 前言 Spark 组件由于其较好的容错与故障恢复机制,在企业的长时作业中使用的非常广��
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致 > 难满足日常的业务开发需求。 > **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。** > > > >  特惠活动
特惠活动
 用Sparql查询获取一个人的数据-优选内容
用Sparql查询获取一个人的数据-优选内容
 用Sparql查询获取一个人的数据-相关内容
用Sparql查询获取一个人的数据-相关内容
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
基于连接进行对数据的操作,例如增删改查。可以看到在Java定义的标准接口访问中,先创建一个connection完成存储介质,然后完成connection后续操作。性能问题导致单次请求实时创建connection的性能较差。因此我们往往通过维护一个存有多个connection的连接池,将connection的创建与使用分开以提升性能,因而也衍生出很多数据库连接池,例如C3P0,DBCP等。# **3. Hive 的 JDBC 实现**构建SparkSQL服务器最好的方式是用如上Java接口,...
StarRocks Spark Connector
StarRocks 支持通过 Spark 读取或写入数据。您可以使用 Spark Connector 连接 Spark 与 StarRocks 实现数据导入,其原理是在内存中对数据进行攒批,按批次使用 Stream Load 将数据导入 StarRocks。Spark Connector 支持 DataFrame 和 SQL 接入形式,并支持 Batch 和 Structured Streaming 作业类型。 1 获取 Spark Connector您可以从 Maven 中央仓库 中下载与您 Spark 版本匹配的最新的 spark-connector-starrocks.jar 文件,也可以使...
基于Spark的词频统计
实验介绍 本次实验练习介绍了如何在虚拟机内进行批示计算Spark的词频统计类型的数据处理。在开始实验前需要先进行如下的准备工作: 下载并配置完成虚拟机。 在虚拟机内已完成Hadoop环境的搭建。 关于实验 预计部署时... $HADOOP_HOME/lib/native依次执行sudo cp workers.template worker和vim worker查看workers配置文件内容。有如下所示图显: 默认是“localhost”,如果不是,请更改为此。 3.验证及启动在命令行输入jps,出现如下所示...
干货|字节跳动数据技术实战:Spark性能调优与功能升级
读取的数据量越少,整体的计算也会越快。大多数情况下,可以直接跳过一些没必要的数据, **即Data Skipping。** **Data Skipping核心思路主要分为三个层面:** **●****Partition Skipping:**仅... 以此提升查询性能。当然为了避免引入额外损耗,仅适用于部分Join场景。 如下图所示,两表Join,左表数据量较大,右表数据量较少,则可以提前将右表join key读取出来,在左表动态生成一个Filter算子,其效果相当...
基础使用
本文将为您介绍Spark支持弹性分布式数据集(RDD)、Spark SQL、PySpark和数据库表的基础操作示例。 1 使用前提已创建E-MapReduce(简称“EMR”)集群,详见:创建集群。 2 RDD基础操作Spark围绕着 RDD 的概念展开,RDD是可以并行操作的元素的容错集合。Spark支持通过集合来创建RDD和通过外部数据集构建RDD两种方式来创建RDD。例如,共享文件系统、HDFS、HBase或任何提供Hadoop InputFormat的数据集。 2.1 创建RDD示例:通过集合来创建RDD ...
配置 Spark 访问 CloudFS
Spark 是专为大规模数据分析处理而设计的开源分布式计算框架。本文介绍如何配置 EMR 中的 Spark 服务使用 CloudFS。 前提条件开通大数据文件存储服务并创建文件存储实例,获取挂载点信息。具体操作,请参见开通大数据... 使用Spark-shell处理 CloudFS 的数据。具体操作步骤如下: 进入 Spark 的bin目录下,执行以下命令进去界面。 xml ./spark-shell如果返回以下信息,则表示执行成功。2. 查询 CloudFS 中的数据。 读取 CloudFS 路径下...
使用 VCI 运行 Spark 数据处理任务
使用弹性容器实例(VCI)运行 Spark 数据处理任务,可以不受限于容器服务(VKE)集群的节点计算容量,能够按需灵活动态地创建 Pod,有效地降低计算成本。本文主要介绍在 VKE 集群中安装 Spark Operator,并使用 VCI 运行 S... 查看创建进度,并确认集群创建成功。 步骤二:连接集群在 容器服务控制台 的 集群 页面,找到本文上方 步骤一 中已创建的集群,单击集群名称。 在集群 基本信息 页面,单击 连接信息 页签。 查看 公网访问 Config,获取集...
Iceberg 基础使用
为保证操作的数据库和表都是在指定的 Catalog 下,您需要在命令中的数据库和表名前带上 hive 。例如: 访问 hive 下的数据库 iceberg_db,应为 hive.iceberg_db。 访问 hive 下,数据库名为 iceberg_db 下的表 table1,应为 hive.iceberg_db.table1。 以上命令示例中配置项的描述如下,也可参考 Iceberg高阶使用的参数配置章节获得更多配置项解释: spark.sql.extensions:SparkSQL扩展模块。固定值为org.apache.iceberg.spark.extensio...
字节跳动 Spark Shuffle 大规模云原生化演进实践
这个时候每个 Reducer 会访问所有包含它的 Reducer Partition 的 ESS并读取对应 Reduce Partition 的数据。这里可能会请求到所有 Partition 所在的 ESS,直到这个 Reducer 获取到所有对应的 Reduce Partition 的数据... 也可以使用本地的高性能 SSD 磁盘;部署在 Daemonset 模式,Gödel 架构下。- **混部****资源集群环境**。这些集群主要服务于中低游的作业,以一些临时查询、调试或者测试任务为主。这些集群的资源主要都部署在 HD...
