Map函数中出错:无法读取未定义的'map”属性。
 社区干货
社区干货
边缘网络 eBPF 超能力:eBPF map 原理与性能解析
展示了一个 map 的使用例子:1、map 的定义:定义全局的变量 ENDPOINTS_MAP,定义了 map 相关属性,比如类型 hash、key value 的大小、map 的大小等等。```struct bpf_elf_map __section_maps ENDPOINTS_MAP = {... return map_lookup_elem(&ENDPOINTS_MAP, &key);}复制代码```可以看到:map_lookup_elem 帮助函数只需要传入 &ENDPOINTS_MAP 和 key 即可。那么问题来了:- 在内核态中 ENDPOINTS_MAP 的内存是怎...
借助 MAD 助力你的 Android 应用开发|社区征文
我们在代码中大量使用 `data class` 并且要求属性使用 `val` 而非 `var` 定义,这有利于单向数据流范式在项目中的推广,在架构层面实现数据的读写分离。```kotlindata class HomeUiState( val bannerList: Re... 上例的 `doShare` 用挂起函数处理照片的分享逻辑:弹出分享面板供用户选择分享渠道,并将分享结果返回给调用方。调用方启动分享并同步获取分享成功或失败的结果,代码风格更符合直觉。### Flow项目中使用 Flow 替...
golang pprof
搬运一篇我之前的文章> 大家好啊,今天外边真的是热爆了,根本不想出去走动,这个天气在空调房里拿个小勺子🥄挖着冰镇西瓜吃,真的是绝了😄,正当我一边看着奥运一边恰西瓜时,我突然想到,这大夏天的不能光我自己凉快,... 执行`top`命令可以可以看到占用量逆序排列的函数,如下。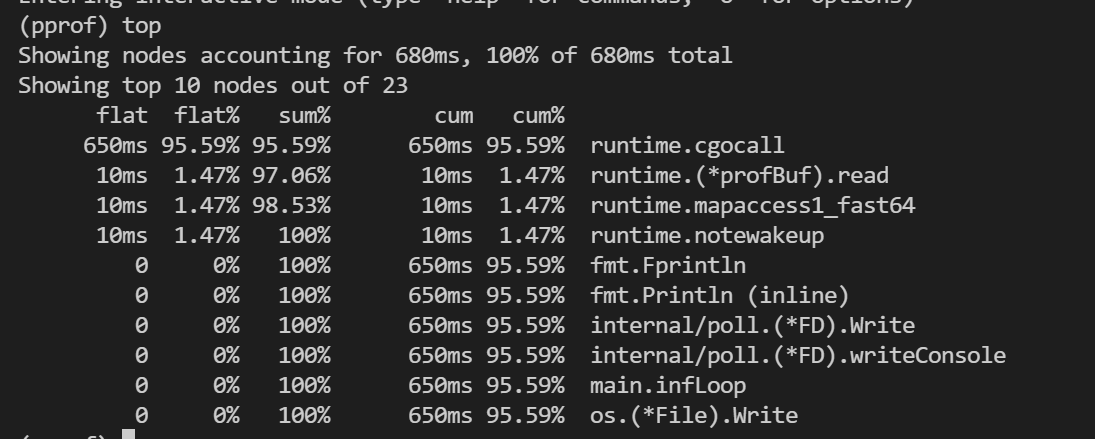可以看到总共有6列信息,这六...
MAD,现代安卓开发技术:Android 领域开发方式的重大变革|社区征文
有的时候在没有其他 App 代码的情况下通过 Memory Profilers 还可以查看其内部的实例和变量细节。* CPU:性能剖析器检查 CPU 活动,切换到 Frames 视图还可以**界面卡顿追踪*** Memory:识别可能会导致应用卡顿... return mapper.map(input); }}```Kotlin 则无需定义接口,直接将匿名回调函数作为参数传入即可。(匿名函数是最后一个参数的话,方法体可单独拎出,增加可读性)这种接受函数作为参数或返回值的函数称...
 特惠活动
特惠活动
 Map函数中出错:无法读取未定义的'map”属性。
-优选内容
Map函数中出错:无法读取未定义的'map”属性。
-优选内容
 Map函数中出错:无法读取未定义的'map”属性。
-相关内容
Map函数中出错:无法读取未定义的'map”属性。
-相关内容
Java SDK
import java.util.HashMap; public class Example { public static void main(String[] args) { // 初始化ABTest分流类,appKey获取方式详见接口描述AbClient AbClient abClient = new AbClien... 请替换为客户的真实用户标识 // add: 添加用户属性,仅用于分流,不随埋点上报 // build: 生成User对象 User user = new User.UserBuilder().create("decisionID", "trackID") ...
借助 MAD 助力你的 Android 应用开发|社区征文
我们在代码中大量使用 `data class` 并且要求属性使用 `val` 而非 `var` 定义,这有利于单向数据流范式在项目中的推广,在架构层面实现数据的读写分离。```kotlindata class HomeUiState( val bannerList: Re... 上例的 `doShare` 用挂起函数处理照片的分享逻辑:弹出分享面板供用户选择分享渠道,并将分享结果返回给调用方。调用方启动分享并同步获取分享成功或失败的结果,代码风格更符合直觉。### Flow项目中使用 Flow 替...
MAD,现代安卓开发技术:Android 领域开发方式的重大变革|社区征文
有的时候在没有其他 App 代码的情况下通过 Memory Profilers 还可以查看其内部的实例和变量细节。* CPU:性能剖析器检查 CPU 活动,切换到 Frames 视图还可以**界面卡顿追踪*** Memory:识别可能会导致应用卡顿... return mapper.map(input); }}```Kotlin 则无需定义接口,直接将匿名回调函数作为参数传入即可。(匿名函数是最后一个参数的话,方法体可单独拎出,增加可读性)这种接受函数作为参数或返回值的函数称...
干货|火山引擎A/B测试平台的实验管理重构与DDD实践
这里说明的一点是,代码的第一目标肯定是满足产品需求,能够满足产品需求的代码都是好代码。而本文中对代码的好坏的评价完全是从架构的视角,结合代码的可读性、可维护性与可扩展性去分析的。 