p106卡tensorflow
 社区干货
社区干货
火山引擎大规模机器学习平台架构设计与应用实践
还有多种不同类型的网卡。同时云原生的虚拟化也会产生损耗。火山引擎机器学习平台公有云上的系统,云原生本身会带来一些虚拟化损耗,比如网络和容器会进行一定的虚拟化,存储的分层池化也会带来负载均衡的问题。繁多的分布式训练框架:火山引擎机器学习平台的用户很多,不同的任务有不同的分布式训练框架,包括数据并行的框架(TensorflowPS、Horovod、PyTorchDDP、BytePS 等),模型并行的框架(Megatron-LM、DeepSpeed、veGiantModel...
火山引擎大规模机器学习平台架构设计与应用实践
还有多种不同类型的网卡。同时云原生的 **虚拟化也会产生损耗** 。火山引擎机器学习平台公有云上的系统,云原生本身会带来一些虚拟化损耗,比如网络和容器会进行一定的虚拟化,存储的分层池化也会带来负载均衡的问题。繁多的分布式训练框架:火山引擎机器学习平台的用户很多,不同的任务有不同的分布式训练框架,包括数据并行的框架(TensorflowPS、Horovod、PyTorchDDP、BytePS 等),模型并行的框架(Megatron-LM、DeepSpeed、veG...
【MindStudio训练营第一季】MindStudio Profiling随笔
> TensorFlow环境变量配置:```export PROFILING MODE=trueexport PROFILING OPTIONS='"output":"/tmp","training trace":"on""task trace":"on","aicpu":"on,"aic metrics:"PipeUtilization")```训练脚本... HCCL timeline数据:通过多卡进行训练时,卡间通信算子也可能导致性能瓶颈。(4)打开组件接口耗时统计表:可以查看迭代...
字节跳动云原生成本优化实践开源项目 Katalyst |社区编程挑战启动!
在 TensorFlow 训练中,高内存带宽消耗 worker,会影响同一 NUMA 节点上的参数服务器。将这些 pod 分配给不同的 NUMA 节点可以减轻这种干扰。 **预期收获**1. 体验真实开源项目,熟悉开源社区运作流程,积累开发实践经验2. 参与 community meeting,与开源爱好者交流,了解社区动态3. 项目 mentor 一对一辅导,面对面答疑4. 完成项目的优秀 contributor 还可获得社区激励奖金 5000 元(等额京东卡)...
 特惠活动
特惠活动
 p106卡tensorflow-优选内容
p106卡tensorflow-优选内容
 p106卡tensorflow-相关内容
p106卡tensorflow-相关内容
从字节跳动机器学习平台,到火山引擎智能中台
最多仅能用到4卡或者8卡的规模,需要通过分布式训练加速。 为解决上述难题,机器学习平台展开了长期的技术优化。在架构上,我们确定了“高性能+云原生”的机器学习平台建设目标: 底层物理资源池中,一个集群就是一个高... 实现了同时支持Tensorflow、PyTorch、MXNet等行业主流训练框架,并且可以在TCP和RDMA网络上运行。BytePS提供了TensorFlow、PyTorch、MXNet以及Keras的插件,用户只要在代码中引用BytePS的插件,就可以获得高性能的分布...
从字节跳动机器学习平台,到火山引擎智能中台
最多仅能用到4卡或者8卡的规模,需要通过分布式训练加速。 为解决上述难题,机器学习平台展开了长期的技术优化。 在架构上,我们确定了“高性能+云原生”的机器学习平台建设目标: 底层物理资源池中,一个集群就是一个... 实现了同时支持Tensorflow、PyTorch、MXNet等行业主流训练框架,并且可以在TCP和RDMA网络上运行。 BytePS提供了TensorFlow、PyTorch、MXNet以及Keras的插件,用户只要在代码中引用BytePS的插件,就可以获得高性能的分...
【MindStudio训练营第一季】MindStudio Profiling随笔
> TensorFlow环境变量配置:```export PROFILING MODE=trueexport PROFILING OPTIONS='"output":"/tmp","training trace":"on""task trace":"on","aicpu":"on,"aic metrics:"PipeUtilization")```训练脚本... HCCL timeline数据:通过多卡进行训练时,卡间通信算子也可能导致性能瓶颈。(4)打开组件接口耗时统计表:可以查看迭代...
字节跳动云原生成本优化实践开源项目 Katalyst |社区编程挑战启动!
在 TensorFlow 训练中,高内存带宽消耗 worker,会影响同一 NUMA 节点上的参数服务器。将这些 pod 分配给不同的 NUMA 节点可以减轻这种干扰。 **预期收获**1. 体验真实开源项目,熟悉开源社区运作流程,积累开发实践经验2. 参与 community meeting,与开源爱好者交流,了解社区动态3. 项目 mentor 一对一辅导,面对面答疑4. 完成项目的优秀 contributor 还可获得社区激励奖金 5000 元(等额京东卡)...
得物AI平台-KubeAI推理训练引擎设计和实践
是把pytorch / tensorflow等模型先转成*onnx*格式,然后再将*onnx*格式转成TensorRT(*trt*)格式进行优化,如下图所示:。* num\_workers:参数最小设置为 **训练环境的CPU配置-1** ,比如:任务配置为12C时,建议该参数设置为11 。另外,num\_workers数值可以适当调大,因为`data...
字节跳动云原生成本优化实践开源项目 Katalyst |社区编程挑战启动!
in a tensorflow training job, high-memory bandwidth consuming pods, like workers, can impact the performance of other pods on the same NUMA node, such as parameter servers. Allocating these pods to... 完成项目的优秀 contributor 还可获得社区激励奖金 5000元(等额京东卡) ### 参与要求1. 18岁以上高校在校学生1. 热爱开源文化,接受开源协作模式 *非高校学生如果对议题感兴趣,欢迎参与社区一起...
实例选型最佳实践
GPU卡。 i:Inference,适用于推理场景的GPU卡。 t:Training,适用于训练场景的GPU卡。 p:Performance,通用性能GPU卡。 v/t:GPU卡的类型为V100/T4。 n:NVIDIA,NVIDIA GPU显卡。 e:平衡增强属性,即均衡的vCPU、内存、网... TensorFlow、PyTorch GPU计算型pni2/g1ve/g1vc、高性能计算GPU型hpcg1ve AI训练 NXNET GPU计算型pni2、高性能计算GPU型hpcpni2 AI推理 OpenVINO、TensorRT GPU计算型gni2/ini2/g1ve/g1vc、高性能计算GPU型hpcg1ve ...
浅谈AI机器学习及实践总结 | 社区征文
蒙特卡洛学习...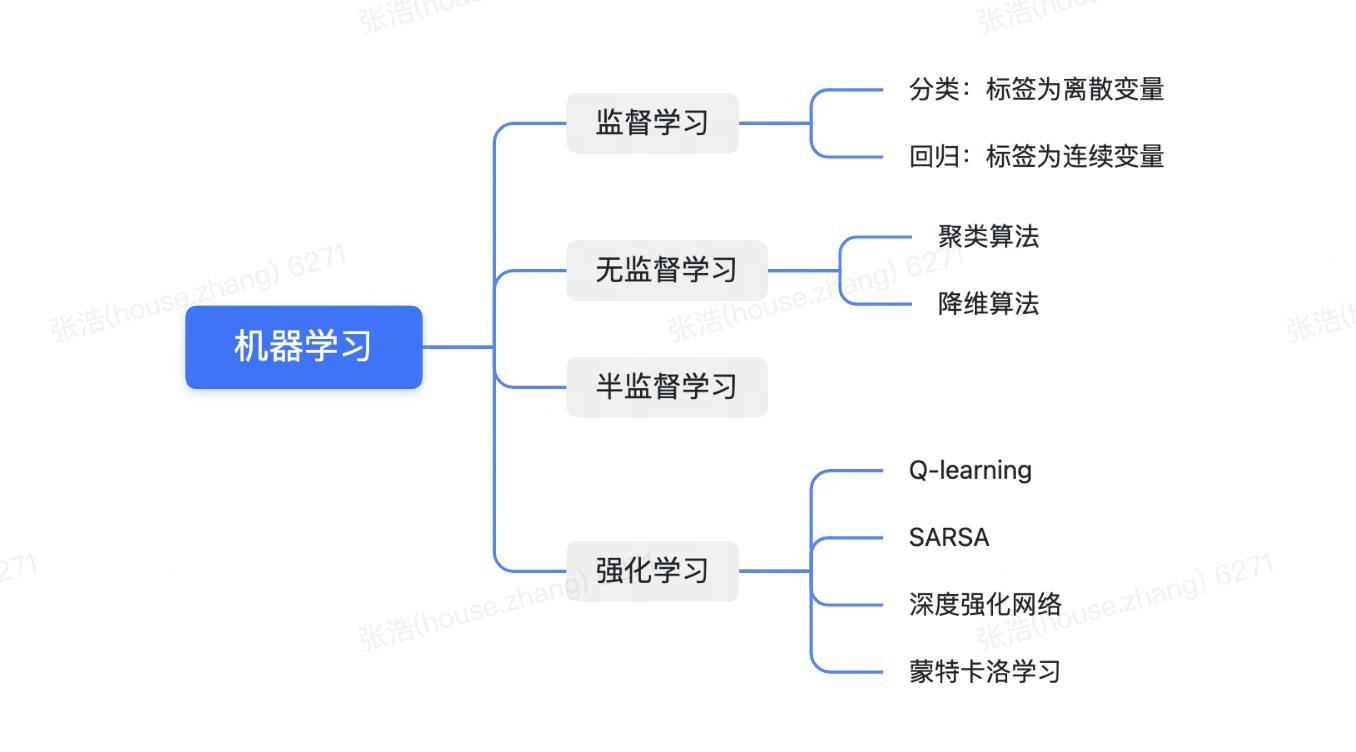## 如何理解深度学习常说的深度学习是一种使用深层神经网络... ## 启动可以指定端口号,不指定默认8888 当# 还可以指定其他参数具体可以 jupyter notebook -h```### 使用Docker安装docker安装启动jupyter就比较简单了比如:docker run -it -d --name=test. tensorflow/te...
字节跳动 Spark 支持万卡模型推理实践
> 本文整理自字节跳动基础架构工程师刘畅和机器学习系统工程师张永强在本次 CommunityOverCode Asia 2023 中的《字节跳动 Spark 支持万卡模型推理实践》主题演讲。在云原生化的发展过程中 Kubernetes 由于其强大... Tensorflow 等常见的模型推理,同时也支持 Partition 级别的 Checkpoint。这样在资源回撤的时候就不需要重复计算了,能够避免算力的浪费,并通过支持 Batching 可以提高整体的资源利用率。 ...
