自2017年诞生以来,字节跳动机器学习平台从一开始的几十台物理GPU开发机,到现在支持着万级GPU调度,持续降低机器学习的算力和开发门槛,帮助我们内部平台和外部客户深入发展自己的AI的能力。
——易百忍 | 字节跳动AI Lab机器学习平台软件工程师
火山引擎智能中台整个基础设施支撑着所有上层业务的发展,一方面是弹性轻量化,支撑1-10000节点的轻量化平台,另一方面是云原生层面,支持云原生PaaS设计的IaaS系统和云原生存储。
——邓德源 | 火山引擎云原生产品技术负责人
从建设字节跳动机器学习平台
2017年字节跳动人工智能实验室(AI Lab)正式成立,为实现更完善的资源管理目标,字节跳动开始着手构建机器学习平台。这几年,随着资源池不断扩展,团队逐渐发展,机器学习平台从一开始仅有的几十台物理GPU开发机,到现在支持着万级GPU调度,仅单一集群就有着几百台GPU机器。
在这几年的建设历史中,字节跳动机器学习平台经历的不仅是发展,还有着种种难题:
机器环境配置不一,管理运维成本高。 机器配置不一,不同项目对于环境的依赖也有自己的需求,作为平台方,管理运维的成本非常高。
代码、依赖库版本管理复杂,训练结果难以复现。 研发过程中的模型训练,存在着代码以及依赖库的版本管理问题,例如依赖环境变动,或自己遗忘代码的改动,最终导致结果难以复现。
部分训练任务时间长,需要分布式训练加速。 部分训练任务的时间比较长,只在单机上跑,最多仅能用到4卡或者8卡的规模,需要通过分布式训练加速。
为解决上述难题,机器学习平台展开了长期的技术优化。在架构上,我们确定了“高性能+云原生”的机器学习平台建设目标: 底层物理资源池中,一个集群就是一个高性能集群;要兼顾多个团队的需求,通过云原生基座进行资源调配与调度。
为完成这一架构目标,字节跳动机器学习平台进行了多个实践。
- 模型训练平台:模型训练底层资源池选择了NVLink V100+100G RDMA网络,以加速分布式训练任务,确保不同团队智能模型开发、运维工作流的高效敏捷。
- 模型推断平台:提供服务上线、水平伸缩、灰度发布等能力,以打通模型训练管道。
最核心的资源调度,我们同样进行了特别的优化:通过容器云进行调度任务,镜像打包模型代码,分布式存储数据集;多卡、分布式的训练任务将优先满足机内总线和集群网络拓扑;推断服务支持多个小服务共享同一块GPU,GPU成本进一步降低;推断资源池能在闲时拆借资源,用于训练任务,有效实现潮汐资源调度,GPU利用率得到极大提高。
此外,对于整个机器学习的核心——软硬件性能的优化,字节跳动技术团队还在几年机器学习平台建设过程中沉淀出了两个开源项目:加速分布式训练框架BytePS、加速BERT线上推理服务Effective Transformer。
丨BytePS
BytePS是一种高性能的通用分布式训练框架,通过一个可以被各种通用框架引用的抽象层,实现了同时支持Tensorflow、PyTorch、MXNet等行业主流训练框架,并且可以在TCP和RDMA网络上运行。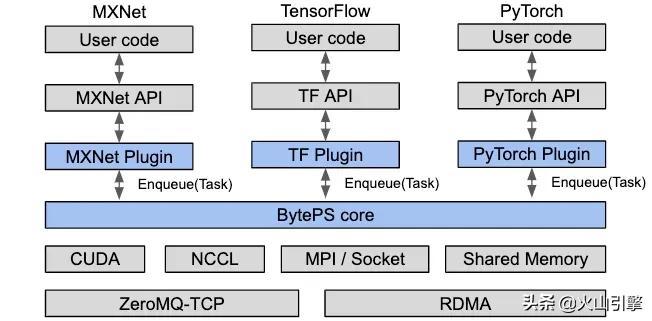 BytePS提供了TensorFlow、PyTorch、MXNet以及Keras的插件,用户只要在代码中引用BytePS的插件,就可以获得高性能的分布式训练。
BytePS提供了TensorFlow、PyTorch、MXNet以及Keras的插件,用户只要在代码中引用BytePS的插件,就可以获得高性能的分布式训练。
另外,BytePS在很大程度上优于现有的开源分布式训练框架。例如,在进行BERT大型训练时,BytePS可以使用256个GPU实现约90%的缩放效率,这比Horovod + NCCL高得多。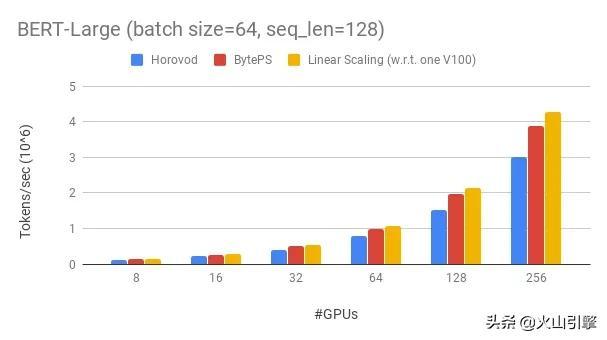 丨Effective Transformer
丨Effective Transformer
Effective Transformer基于NVIDIA FasterTransformer,具有许多高级优化功能。
在做推BERT理服务时,进入模型的文本可能出现长短不一的情况,虽然限定的最大值为8个词,但实际情况可能是进入4个、5个。按照传统思路,例如NVIDIA Faster Transformer,都是先做补齐至8个词,再换成GPU做运算。
这种情况下,虽然形状规整了,但补齐部分是无效的。按照经常看到的行程,仅达到最长长度的60%-70%,这意味着浪费了30%以上的算力。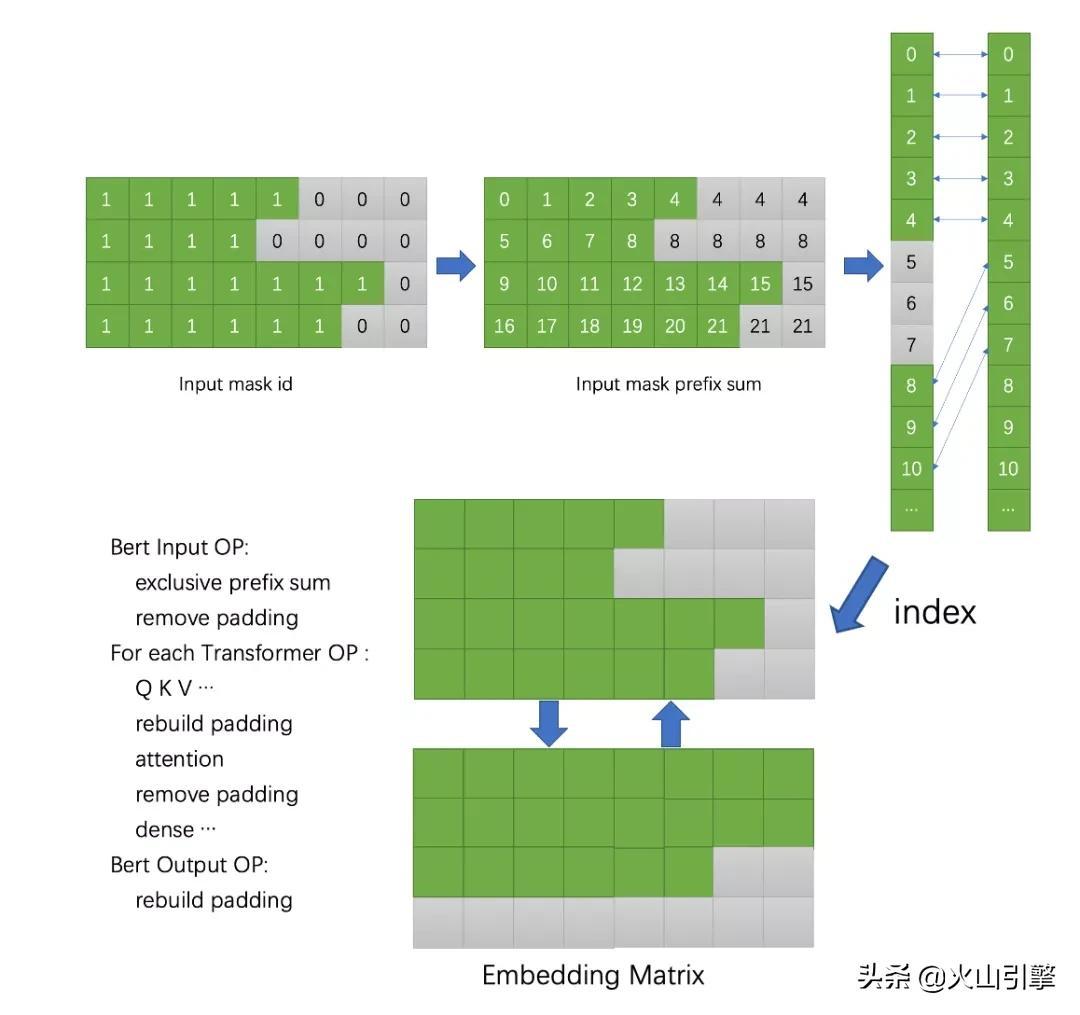 Effective Transformer则是通过前缀做转换,不仅把补齐了形状,还可以把词往上进行填充。在大批量训练的情况下,Effective Transformer可以显着减少执行时间和内存消耗,平均降低30%无效训练量。
Effective Transformer则是通过前缀做转换,不仅把补齐了形状,还可以把词往上进行填充。在大批量训练的情况下,Effective Transformer可以显着减少执行时间和内存消耗,平均降低30%无效训练量。
到搭建火山引擎智能中台解决方案
经过几年的发展,字节跳动机器学习平台现在管理着数万块GPU,持续为内外部提供AI能力,而在其底部的基础设施平台,也已经在技术优化、资源融合、弹性伸缩、统一编排、平台安全和数据安全等层面经历了大规模验证,支撑着数EB数据、千万级QPS、数十亿月活App。
为持续降低机器学习的算力和开发门槛,帮助企业级客户更深入地发展属于自己的AI能力,火山引擎融合了基础设施平台、研发中台以及机器学习平台,建设了以“高可靠、高性能调度”为特点的智能中台解决方案。
丨基础设施平台
基础设施平台支撑着所有上层业务发展。为支持更多企业轻松上云,火山引擎基础设施平台的建设历经了持续的思考和探索:
- 第一,弹性轻量化。 很多企业用户不是一开始就有大规模节点需求,因此我们将其建设成能支撑1-10000个节点的轻量化平台,以弹性支持更多的企业用户;
- 第二,云原生。 字节跳动内部机器学习平台、PaaS平台的成功都离不开其云原生底座。为了让用户能通过同样的路径轻松上云,基础设施平台设计成能够支持云原生PaaS设计的IaaS系统和云原生存储;
- 第三,易维护性。 企业级产品需要具备极高的可维护性以降低用户管理成本,支持用户快速地对平台进行操作和维护。火山引擎基础设施平台提供了监控告警、硬件状态、远程控制、余量管理等各种能力,以高效地管理平台。
丨研发中台
研发中台介于机器学习平台和基础设施平台之间,起承上启下的作用,主要提供服务治理能力,例如集群管理、存储管理、微服务、多租户管理等。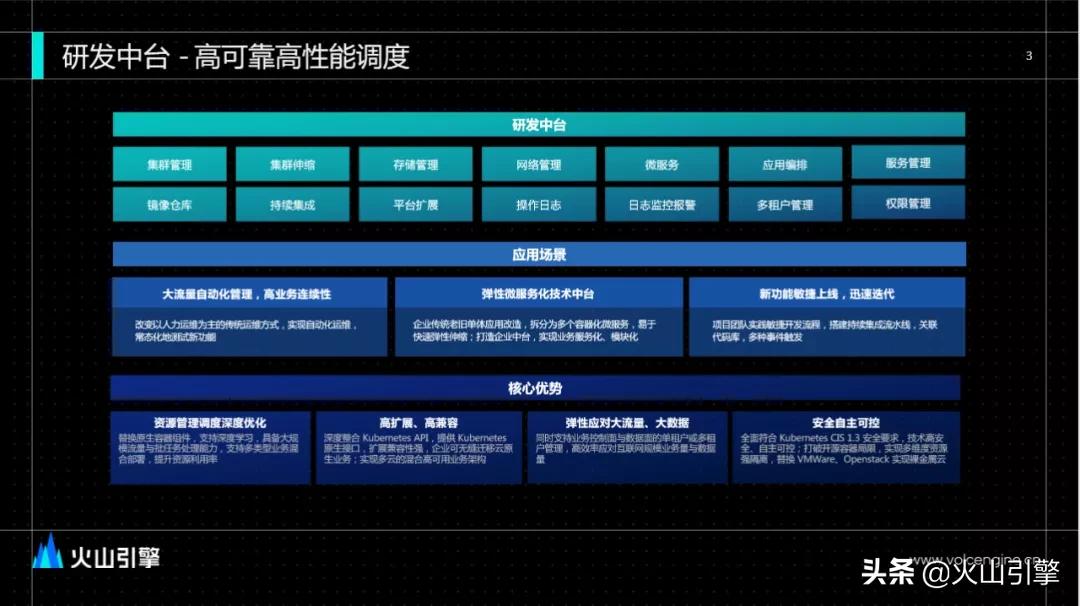 在内部,研发中台主要提供弹性微服务治理的能力,如在大规模场景下资源的管控,异构资源的管理等。
在内部,研发中台主要提供弹性微服务治理的能力,如在大规模场景下资源的管控,异构资源的管理等。
在资源管控、弹性应对大流量、安全自主可控等上层应用场景中,研发中台都具有着核心优势,例如改变人力运维为主的传统运维方式,通过大流量的自动化管理、高业务连续性,提供自动化运维水平;为技术中台单体应用改造提供弹性支撑,实现新功能的敏捷上线、迅速迭代。
丨机器学习平台
基础设施平台与研发中台共同支撑着机器学习平台。和构建内部机器学习平台的想法一致,火山引擎机器学习平台构建之始,同样以打造算法开发流程闭环为目标,设计了“数据-建模-部署-管理-监控”的算法全生命流程,实现了开发流程的标准化、自动化、规模化,具有四个主要应用场景:
数据管理:通过结构化、非结构化数据湖,数据协调标注与版本化管理等,提供数据治理、数据质量和数据地图等能力,切实保护数据资产。
资源管理:火山引擎对资源池做了极大优化,通过GPU、CPU调度、模型分布式训练、资源动态分配等,提供AI所需算力,在内外部均已有万级GPU的管理调度落地验证。
流程管理:机器学习应用的发布包含了所有规则和处理逻辑,在应用上线后,由于需要周期性地进行更新、优化迭代,模型本身对外部数据有强依赖,这使得整个DevOps更复杂。对此,火山引擎机器学习平台构建的DevOps流水线,持续集成了从数据处理、模型训练、评估到发布的全流程,极大提升端对端AI产品和业务的上线效率。
模型管理:通过超参数自动搜索、多模型自动对比与评估、线上模型运维等,切实降低模型开发、维护门槛。
 火山引擎机器学习平台的核心目标是降低算法开发门槛,实现规模化应用,具有四大优势:
火山引擎机器学习平台的核心目标是降低算法开发门槛,实现规模化应用,具有四大优势:一站式、端到端:集数据导入与处理、模型开发、训练与评估、服务上线于一体,提供一站式深度学习建模流程,加快业务迭代。
高效率:高效管理和分配硬件资源,支持模型训练和模型服务的统一调度。
无需繁琐配置:配置简单,快速上手,无需用户运营和管理软硬件配置。
支持多框架:全面支持TensorFlow、PyTorch、Caffe、MXNet等多种深度学习和机器学习框架。
小结
从字节跳动机器学习平台的建设历史,到火山引擎智能中台方案的搭建,在开源技术层面,字节跳动与火山引擎沉淀了分布式训练框架BytePS、Effective Transformer、机器学习模型分发组件ORMB等开源项目,帮助更多企业降低机器学习的算力和开发门槛,深入发展自己的AI能力。
于企业服务领域,火山引擎智能中台解决方案在内部,已经过数EB数据、千万级QPS,数十亿月活App长期验证;在外部,已在金融、零售、能源、教育等多个行业落地,帮助企业实现业务增长。