spark输出到服务器
 社区干货
社区干货
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... 因而大大降低Spark的易用性。除此之外,还可使用周边工具,如Livy,但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,...
干货|字节跳动数据技术实战:Spark性能调优与功能升级
文章会为大家讲解字节跳动 **在Spark技术上的实践** ——LAS Spark的基本原理,分析该技术相较于社区版本如何实现性能更高、功能更多,为大家揭秘该技术做到极致优化的内幕,同时,还会为大家带来团队关于LAS Spark技... Spark AQE会将A0的数据拆成N份,使用N个task去处理该partition,每个task只读取若干个MapTask的shuffle输出文件,如下图所示,A0-0只会读取 Stage0#MapTask0中属于A0的数据。这N个Task然后都读取B表partition 0的数据做...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... 因而大大降低Spark的易用性。除此之外,还可使用周边工具,如Livy,但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... 但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开...
 特惠活动
特惠活动
 spark输出到服务器-优选内容
spark输出到服务器-优选内容
 spark输出到服务器-相关内容
spark输出到服务器-相关内容
干货 | 看 SparkSQL 如何支撑企业级数仓
支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心,这一系列... Spark 这类计算引擎依托于 Yarn 做资源管理,对于分布式任务的重试,调度,切换有着非常可靠的保证。Hive,Spark 等组件自身基于可重算的数据落盘机制,确保某个节点出现故障或者部分任务失败后可以快速进行恢复。数据保...
火山引擎基于 Zeppelin 的 Flink/Spark 云原生实践
Server 的进程,在 K8s 环境上面拥有独立的 POD 和环境信息。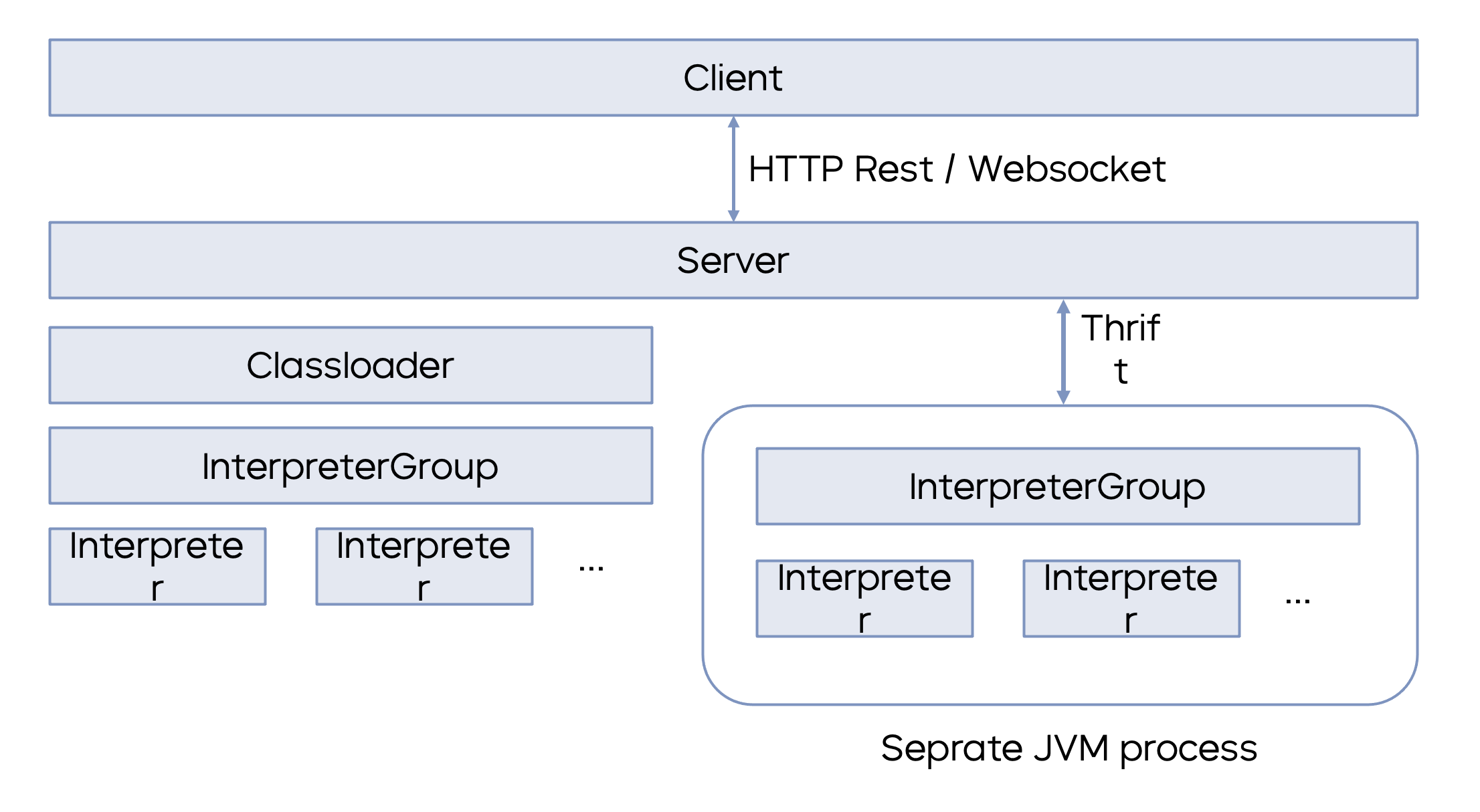 # Apache Zeppelin 的云原生实践Apache Zeppelin 的云原生实践包含五个部分:- **Docker** **镜像优化**:开源 Zeppelin 包含了较多的解释器,在火山引擎的实践过程中,我们通过裁剪只包含 Flink 和 Spark 的部分,同时利用 Docker 镜...
基于 Zeppelin 的 Flink/Spark 云原生实践
文章主要介绍了 Apache Zeppelin 支持 Flink 和 Spark 云原生实践。作者|火山引擎云原生计算研发工程师-陶克路 火山引擎云原生计算研发工程师-王正**01** **Apache Zeppelin ... Server 和 Interpreter。Client 和 Server 通过 Restful 接口或 WebSocket 接口进行交互,Interpreter 解释器则是一个独立于 Zeppelin Server 的进程,在 K8s 环境上面拥有独立的 POD 和环境信息。公布了第十五批“可信大数据”产品能力评测结果。**火山引擎流式计算 Flink 版和火山引擎批式计算 Spark 版**凭借出色的基础能力、优秀的性... # 流式计算 Flink 版火山引擎流式计算 Flink 版依托于字节跳动在**业内最大规模实时计算集群实践**。火山引擎流式计算 Flink 版基于火山引擎容器服务(VKE/VCI),提供 Serverless 极致弹性,是开箱即用的全托管流式...
