一种内存高效的无重复采样向量计数的方法
 社区干货
社区干货
VikingDB:大规模云原生向量数据库的前沿实践与应用
无服务化、数据生态的融合等;* 性能层面:为了极致的延迟和成本,支持了 Int4/Int8/fix16 等多种量化方式、基于指令集的计算优化、GPU 加速等;* 产品特性层面:除了基础的 ANN 检索功能外,支持了Hybrid (Dense&Spar... 由于向量数据库能够高效存储和检索模型生成的向量,从而提供语义上更具有相关性的检索结果,因此向量数据库成了 ES 之外的 RAG 必不可少的检索工具,RAG 也成为了向量数据库最为重要的应用场景。简而言之, **向量库数...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数据提升模型的性能。最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇...
工业大数据分析与应用——知识总结 | 社区征文
没有预定义的数据模型,不方便用数据库二位逻辑表来表现的数据。### 1.3 大数据的影响* 思维方式上,完全颠覆了传统的思维方式:全样而非抽样、效率而非精确、相关而非因果* 社会发展上,大数据决策逐渐成为一种新... 设计方法和实现技术。2. **企业生产与运行管理中的建模与优化决策** 1)大数据与模型相融合的多目标智能优化; 2)企业运行管理中的建模与优化决策; 3)流程工业一体化计划调度; 4)制造执行系统的体系结...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
人们开始尝试模型小型化的方法。Chinchilla 就是一种模型小型化的尝试,相较于其前代模型,将模型参数缩小了 4 倍,但样本量却增大了 4 倍,这种方法试图在保持相对较小的模型规模的同时利用更多的数据提升模型的性能。最近最新推出的 GPT-4 模型以及 Google 最近发布的第二代 PaLM 没有公布具体的模型细节。但可以猜测的是,这些模型的规模可能已经达到了万亿级的参数,这些进展为自然语言处理和其他相关领域的研究者们带来了新的机遇...
 特惠活动
特惠活动
 一种内存高效的无重复采样向量计数的方法-优选内容
一种内存高效的无重复采样向量计数的方法-优选内容
 一种内存高效的无重复采样向量计数的方法-相关内容
一种内存高效的无重复采样向量计数的方法-相关内容
支持的插件列表
bloom 1.0 1.0 1.0 提供一种基于布鲁姆过滤器的索引访问方法。 btree_gin 1.3 1.3 1.3 提供一个为多种数据类型和所有 enum 类型实现 B 树等价行为的 GIN 操作符类示例。 btree_gist 1.5 1.5 1.5 提供一个为多种数... pg_prewarm 1.2 1.2 1.2 提供一种方便的方法把数据载入到操作系统缓冲区或者 PostgreSQL 缓冲区。 pg_roaringbitmap 0.5.4 0.5.4 0.5.4 提供高效的位图存储和运算能力。 pg_repack 1.4.8 1.4.8 1.4.8 提供在线 Va...
聊聊得物数据研发优化策略
内存、磁盘每一个模块的性能,从早期的纵向扩展(提升计算机性能,如IBM、ORACLE 早期推崇的服务器到小型机到大型机的演进)到目前的大规模横向扩展(分布式集群模式),都是旨在提升大数据的性能。本文重点从在分布式计... 策略及方法。# 二、任务优化策略## 2.1 优化方向.add(new StandardScaler().setSelectedCols(numericalColNames)).add(new FeatureHasher().setSelectedCols(selectedColNames).setCategori...
ICASSP 2023 | 解密实时通话中基于 AI 的一些语音增强技术
如何提高说话人嵌入向量和语音增强模型的信息交互是实时处理的难点。受到人类听觉注意力的启发,火山引擎提出了一种引入说话人信息的说话人注意力模块(Speaker Attentive Module,SAM),并将其和单通道语音增强模型-频... ### 时延补偿TDC 基于子带互相关,其首先分别在每个子带中估计出一个时延,然后使用投票方法来确定最终时间延迟。### 线性回声消除LAEC 是一种基于 NLMS 的子带自适应滤波方法,由两个滤波器组成:前置滤波器(Pr...
[数据库论文研读] HTAP行列混存 & 智能转换
并没有一个“标准”的实现,更多强调“Flexible”** 。接下来我们就看看作者在论文中提出的一种灵活的存储结构——Tile-Based Architecture。### 物理层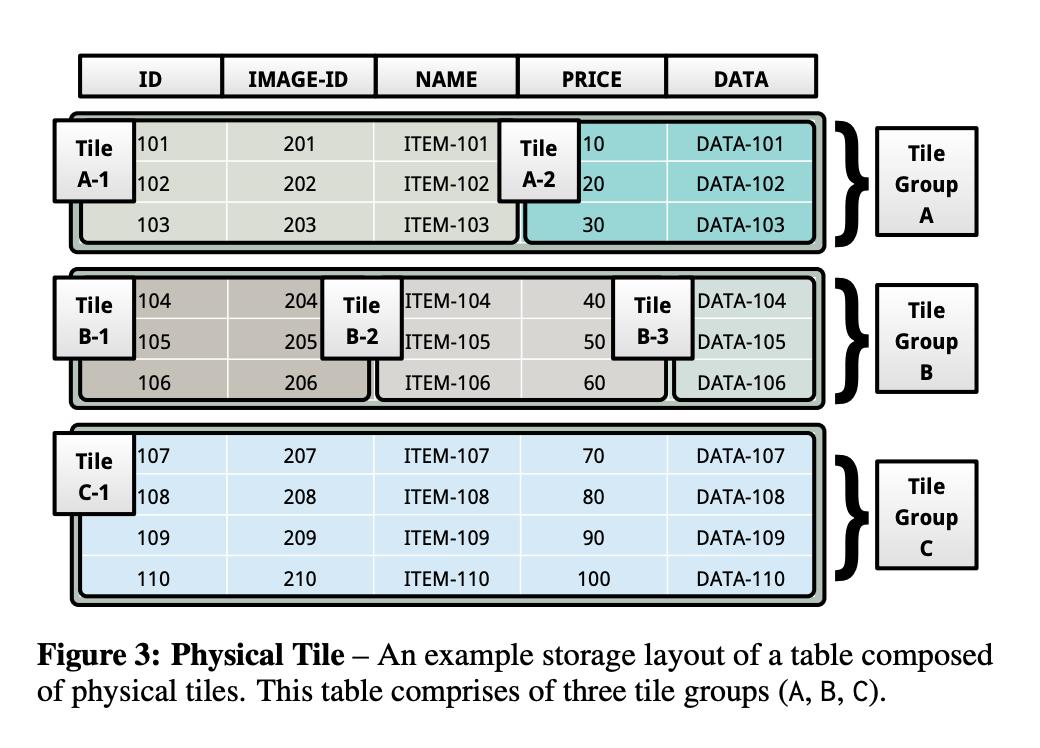- 表:一个N行 * M列的二维矩阵- Tile Tuple:可以理解为一个1行 * B列的向量,其中B <= M-...
技术人的 2023 总结:人工智能-基于机器学习的环境污染影响评估学习|社区征文
本文将探讨基于机器学习的环境污染影响评估方法,并提供相应的代码实例。环境污染包括空气、水、土壤等多个方面,因此准确评估其影响需要全面考虑多种因素。传统的监测方法通常依赖于定点采样,显然无法全面覆盖大范围... 支持向量机等。这里选择随机森林模型进行演示。```from sklearn.ensemble import RandomForestRegressorfrom sklearn.metrics import mean_squared_error# 构建随机森林模型rf_model = RandomForestRegress...
万字长文,Spark 架构原理和 RDD 算子详解一网打进! | 社区征文
获取数据的方法,分区的方法等等。### 2.3 RDD的五大特性(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭...
火山引擎在机器写作和机器翻译方面的最新进展
当然最基本的一种方法是叫 Auto-Regressive Language model,是把这个联合概率分解成下面这个形式,每一个部分它实际上是第 i 个字符的概率,是建立在前面 1 到 i-1 个字符的基础之上,这具体的每一个概率可以有很多建... 高效计算的密度(Intractable Density),也是今天需要重点介绍的一类模型,叫隐变量模型(Latent Variable Model),典型的代表有 DSSVAE、VTM 等,本场讲座也将会介绍。 假如说这个密度没有显式公式的,是隐式的,也就是...
1024 分辨率下最快模型,字节跳动文生图开放模型 SDXL-Lightning 发布
SDXL-Lightning 通过一种创新技术—— **渐进式对抗蒸馏(Progressive Adversarial Distillation)** ——突破了这一障碍,实现了前所未有的生成速度。 **该模型能够在短短 2 步或 4 步内生成极高质量和分辨率的图像,将计算成本和时间降低十倍** 。我们的方法甚至可以在 1 步内为超时敏感的应用生成图像,虽然可能会稍微牺牲一些质量。除了速度优势,SDXL-Lightning 在图像质量上也有显著表现,并在评估中超越了以往的加速技术。在...
