Map和Record之间的区别以及何时使用Map和Record时的区别
 社区干货
社区干货
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
echo "fs.file-max = 6553560" >> /etc/sysctl.confecho "vm.max_map_count=655300" >> /etc/sysctl.confecho "vm.swappiness = 0" >> /etc/sysctl.conf生效:sudo sysctl -p 修改limits.conf文件:可自行根据实... 堆内存可用来存放由new创建的对象和数组,在堆中分配的内存,由java虚拟机的自动垃圾回收器来管理。 **栈(stack):** 主要用于存储局部变量和对象的引用变量,每个线程都会有一个独立的栈空间,所以线程之间是不...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。- 由于对维度数据做了 Cache,维度数据数据更新不及时,导致下游数据不准确。针对这些问题,并结合业务场景对数据延迟有一定容忍,但对数据准确... **Merge** **LogFile:** Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。在多流拼接中...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
时间会变 得更长,可能会导致任务背压。LAS分析与对策总结上述场景遇到的挑战,主要可归结为以下两点: * 由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。* 由于对维度数... Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。在多流拼接中,因为 LogFile 中存在不同...
我的大数据学习总结 |社区征文
开始学习Linux命令和系统基本概念。然后分别学习Java、Python以及Scala这几种在大数据开发中常用的编程语言。然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务... 当有多个转换操作时,它们如何串联执行?行动操作什么时候和怎样触发转换操作的执行?为了解答这些问题,我打印日志观察执行过程,并写了以下代码测试:```bash// 创建一个RDD val rdd = spark.sparkContext.parallel...
 特惠活动
特惠活动
 Map和Record之间的区别以及何时使用Map和Record时的区别-优选内容
Map和Record之间的区别以及何时使用Map和Record时的区别-优选内容
 Map和Record之间的区别以及何时使用Map和Record时的区别-相关内容
Map和Record之间的区别以及何时使用Map和Record时的区别-相关内容
Rerank
概述BatchRerank 接口用于重新批量计算输入文本与检索到的文本之间的 score 值,以对召回结果进行重排序。 请求参数参数 类型 是否必选 参数说明 datas list[map] 是 map中包含query、content和title三个参数。list最大量为50。 query:必选,输入的文本。 content:必选,检索到的文本。 title:可选,文本的标题。 示例 请求参数Go datas := []map[string]interface{}{ { "query": "退改", "content": "如果...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。- 由于对维度数据做了 Cache,维度数据数据更新不及时,导致下游数据不准确。针对这些问题,并结合业务场景对数据延迟有一定容忍,但对数据准确... **Merge** **LogFile:** Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。在多流拼接中...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
时间会变 得更长,可能会导致任务背压。LAS分析与对策总结上述场景遇到的挑战,主要可归结为以下两点: * 由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。* 由于对维度数... Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。在多流拼接中,因为 LogFile 中存在不同...
我的大数据学习总结 |社区征文
开始学习Linux命令和系统基本概念。然后分别学习Java、Python以及Scala这几种在大数据开发中常用的编程语言。然后着重学习Hadoop核心技术如HDFS和MapReduce;接触数据库Hive后,学习数据流技术Kafka和分布式协调服务... 当有多个转换操作时,它们如何串联执行?行动操作什么时候和怎样触发转换操作的执行?为了解答这些问题,我打印日志观察执行过程,并写了以下代码测试:```bash// 创建一个RDD val rdd = spark.sparkContext.parallel...
字节跳动基于 Apache Hudi 的多流拼接实践
由于多流之间时间差比较大,需要维持大状态,同时 TTL 不好设置。- 由于对维度数据做了 Cache,维度数据数据更新不及时,导致下游数据不准确。针对这些问题,并结合业务场景对数据延迟有一定容忍,但对数据准确... **Merge** **LogFile:** Hudi 现有逻辑是将 LogFile 中的数据读出来存放在 Map 中,对于 LogFile 中每条 Record,如果 Key 不存在 Map 中,则直接放入 Map,如果 Key 已经存在于 Map 中,则需要更新操作。在多流拼接中...
基于 Apache Calcite 的多引擎指标管理最佳实践|CommunityOverCode Asia 2023
重点阐述了指标管理在业内常见的解决方案与字节内部使用的一套 SQL 两种语法多引擎指标管理方案的异同;字节内部如何使用一套 SQL 两种语法实现降本增效以及指标管理技术的具体实现方案。在正文之前,请先思考三个问题:第一个问题,你有注意过 Spark 和 Presto 中同义但不同名的函数吗,比如 instr 和 strpos?接下来要介绍的统一 SQL 可以帮助你自动适应多引擎。第二个问题,你有纠结过 map 字段中有哪些 key 以及它的...
基于 LoserTree 的 Paimon 多路归并优化
并将相同的 Key 使用 MergeFunction 进行合并,其中每个 RecordReader 的数据是有序的。整个读取过程实际上是对多个 RecordReader 的数据进行多路归并。在归并过程中,数据之间的比较次数越多,整体排序耗时越高。... 胜者树和败者树等。在这三种算法中,堆排序每次进行堆调整都需要和左右子节点进行比较,比较次数为 2logN,而胜者树和败者树调整时的比较次数都是 logN,区别是胜者树需要和兄弟节点进行比较并更新父节点,而败者树只需...
[数据库系统] 业界列式存储浅析
record不定长时的快速查找问题,数据排列结构如下图所示: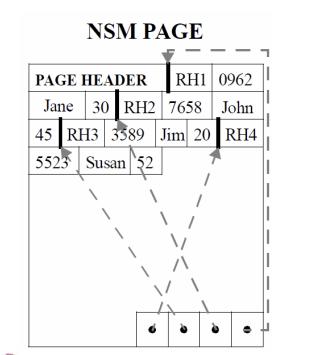列存和行存的区别主要是... 必须有可能按照某个排列顺序O* 通过一组 join indices 来找到mapping了T表中的每个attribute的路径。例如要通过EMP1/2/3来重建EMP表的话,至少需要两组join indexes。如果我们选择age作为公共的排列顺序,我们需要...
基于 LoserTree 的 Paimon 多路归并优化
并将相同的 Key 使用 MergeFunction 进行合并,其中每个 RecordReader 的数据是有序的。整个读取过程实际上是对多个 RecordReader 的数据进行多路归并。在归并过程中,数据之间的比较次数越多,整体排序耗时越高。... 胜者树和败者树等。在这三种算法中,堆排序每次进行堆调整都需要和左右子节点进行比较,比较次数为 2logN,而胜者树和败者树调整时的比较次数都是 logN,区别是胜者树需要和兄弟节点进行比较并更新父节点,而败者树只需...
