流式计算 Flink版
流式计算 Flink版






- 文档首页
 流式计算 Flink版最佳实践性能调优SQL 性能优化Flink SQL 数据倾斜处理最佳实践
流式计算 Flink版最佳实践性能调优SQL 性能优化Flink SQL 数据倾斜处理最佳实践

1. 文档背景
本文档旨在为使用流式计算 Flink 版的用户提供指导,帮助其解决在 Flink SQL 作业开发过程中,尤其是在进行 GROUP BY 聚合时,遇到的数据倾斜问题。数据倾斜是分布式计算中的典型问题,会导致作业性能瓶颈、资源利用不均、甚至作业失败。本文档将解释其现象、根因,并提供在平台上可落地的最佳实践与解决方案。
2. 场景解释
2.1 什么是数据倾斜
数据倾斜是指在分布式计算中,由于数据分布不均匀,导致绝大部分数据集中分布到某一个或某几个任务(TaskManager)上,而其他任务只处理了少量数据。这些处理了大量数据的任务会成为整个作业的瓶颈,引发以下问题:
- 处理延迟: 单个任务处理时间远长于其他任务,拖慢整个作业的吞吐量与产出速度。
- 资源浪费: 其他任务早已执行完毕,资源空闲,而热点任务仍在高负荷运行。
- 背压(Backpressure): 热点任务处理不及,导致数据堆积,向上游传递背压,可能引起数据摄入延迟或故障。
- 内存溢出(OOM): 热点任务在聚合时可能需要维护非常大的状态(如
Keyed State),极易导致 TaskManager 内存溢出,造成作业重启或失败。
在 Flink SQL 中,数据倾斜最常发生在 GROUP BY、JOIN 等需要根据 Key 进行分区的操作中。
2.2 如何识别是否出现数据倾斜问题
在流式计算 Flink 版的控制台,可以通过以下方式快速识别数据倾斜:
- 作业 Flink UI(核心手段):
- 反压监控: 在作业的 「运维」 或 「监控」 页面,查看反压情况。如果拓扑图中某个节点持续显示为 「High」 反压,而其下游节点正常,则该节点很可能发生了数据倾斜。
- 算子吞吐量(Records Sent/Received)与繁忙度: 对比同一个算子(如
groupBy算子)的不同并行子任务(Subtask)。如果某个 Subtask 的记录处理数(Records Processed) 或状态大小远高于其他并行度相同的 Subtask,即可判定发生了数据倾斜。
具体数据倾斜状态可以参考如下 Flink UI 状态,算子持续属于 Busy 状态,同时发现仅有一个 SubTask 数据量远超其他 SubTask
- SQL 分析:
- 如果从 Flink UI 只能简单看出任务确实存在倾斜,但需要确认是哪些具体的 Key 出现了热点,则需要对数据源进行抽样查询,直接分析分组 Key 的分布:
SELECT `key`, COUNT(1) AS cnt FROM source_table GROUP BY `key` ORDER BY cnt DESC LIMIT 10;
如果排名前几的 Key 的数据量(`cnt`)比其他 Key 高出数个数量级,则该 Key 即为热点 Key。
3. 常见处理方案
3.1 调整 Flink 配置(缓解方案)
对于轻度倾斜或作为其他方案的辅助手段,可以在控制台通过调整作业参数进行缓解。
- 增加并行度: 在作业 「配置」 中,适当调大作业的并行度。这为处理热点 Key 提供了更多的任务槽(Slot),可能将热点 Key 的压力分散到更多线程中(但无法解决单个 Key 的倾斜问题,通常需要结合其他方法)。
- 开启 Mini-Batch 优化(强烈推荐): Mini-Batch 通过微批处理减少对状态的访问频率,能显著提升吞吐量并缓解倾斜带来的背压。可在 「高级参数」 中配置:
table.exec.mini-batch.enabled: true table.exec.mini-batch.allow-latency: 5s # 攒批的间隔时间 table.exec.mini-batch.size: 5000 # 攒批的最大记录数
优点: 配置简单,能有效提升吞吐。
缺点: 无法从根本上解决单个 Key 数据量过大的问题。
3.2 两阶段聚合(根治方案 - 推荐)
这是解决聚合倾斜最有效和通用的方法。核心思想是将热点 Key 打散,先进行局部聚合,再进行全局聚合。
3.2.1 普通聚合场景
适用场景: SUM, COUNT, MAX, MIN 等可进行两阶段计算的聚合操作。这些操作通常是对数据进行汇总统计,产生一个单独的结果或一组聚合结果。在普通聚合中,对重复的数据不作特殊处理,相同的数据会被视为同一条记录参与聚合操作。
实施步骤:
- 第一阶段 - 打散并局部聚合: 为原始数据添加一个随机前缀/后缀,将原热点 Key 变为多个新 Key,进行第一次聚合。
- 第二阶段 - 合并并全局聚合: 去除随机后缀,对第一阶段的局部结果按原 Key 进行第二次聚合,得到最终结果。
Local-Merge 示例:
在聚合中,shuffle 和访问 state 是比较大的消耗。我们可以通过打开两阶段优化来加入 local aggregation,如下图所示:
可以看到,Local Aggregation 会在上游算子的末尾直接做一次预聚合,且不访问状态数据,最后传递到 Global Aggregation 的数据量会大量减少,能够有效缓解数据倾斜。需要在任务开发 - 自定义参数设置如下:
# 聚合策略配置,默认是AUTO,选择TWO_PHASE和ONE_PHASE取决于优化过程,可以强制使用TWO_PHASE "table.optimizer.agg-phase-strategy": "TWO_PHASE" # 以下三个配置是minibatch的必选配置,使用local-global aggregate优化必须打开minibatch "table.exec.mini-batch.enabled": "true" "table.exec.mini-batch.allow-latency": "5 s" "table.exec.mini-batch.size": "5000"
注意:当所有的聚合函数允许 merge 结果时(UDAF 需要实现merge函数),两阶段优化才能生效。
Flink SQL 示例:
若打开两阶段优化后,仍然未能缓解,常见于上游已经出现严重的数据倾斜,则可以考虑手动将 groupby key 打散。可以参考如下 SQL 示例:
假设需要计算每个 user_id 的订单总额 SUM(amount),且 user_id 为 abc 的是热点 Key。
-- 第一步:创建临时视图,进行打散局部聚合 (假设打散成10份) CREATE TEMPORARY VIEW partial_agg AS SELECT user_id, suffix, SUM(amount) AS partial_sum FROM ( SELECT user_id, amount, -- 使用RANDOM_INT或HASH_CODE生成随机后缀(0-9) CAST(FLOOR(RAND() * 10) AS INT) AS suffix -- 在Flink SQL中可用RANDOM_INT(10)替代 FROM orders ) GROUP BY user_id, suffix; -- 第二步:进行全局聚合 SELECT user_id, SUM(partial_sum) AS total_amount FROM partial_agg GROUP BY user_id;
操作提示: 可将上述逻辑在一个 SQL 作业中通过临时视图拆分编写。
3.2.2 去重聚合场景
在 Flink SQL 中,处理去重聚合(比如求 UV 等场景),会有 Map 类的结构来存储所有去重 Key 值。如果去重 Key 值分布比较稀疏,则两阶段优化并不能帮助减少单个并发的处理数据量。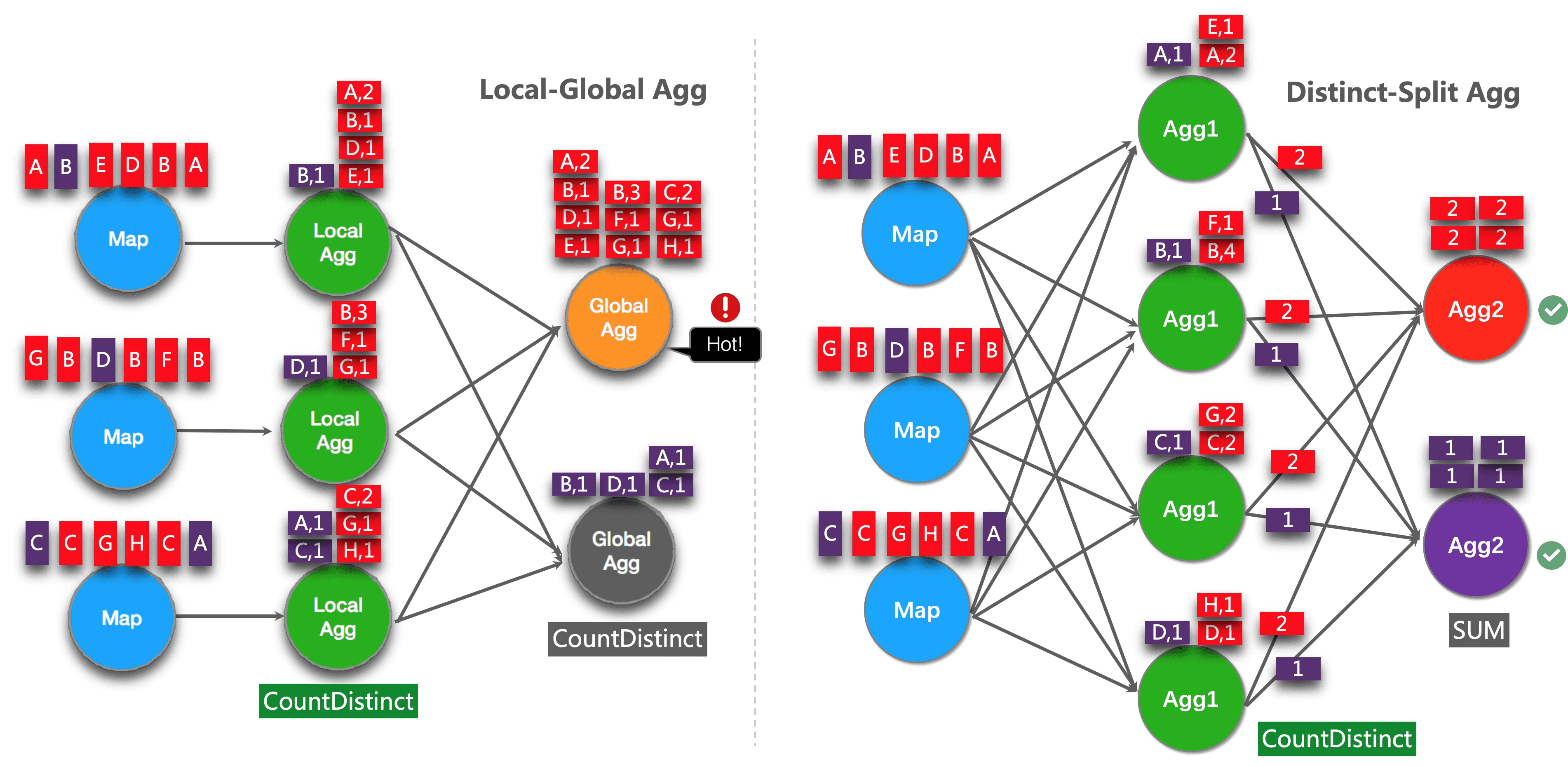
如上图左侧所示,local aggregation 后,distinct 聚合相关的数据依然很多,下游 global aggregation 仍可能产生热点。因此我们需要开启如下优化:
# 打开split优化的开关,默认关闭,需要手动开启 "table.optimizer.distinct-agg.split.enabled": "true" # 当打开split优化时,可以配置分桶个数,默认1024个 "table.optimizer.distinct-agg.split.bucket-num": "1024" # 以下三个配置是minibatch的必选配置,使用split优化必须打开minibatch "table.exec.mini-batch.enabled": "true" "table.exec.mini-batch.allow-latency": "5 s" "table.exec.mini-batch.size": "5000"
开启此优化后,原来的聚合会被优化成两层聚合,其中 distinct key 在内层先被打散,效果如上图的右侧所示。例如以下SQL:
SELECT a, COUNT(DISTINCT user_id) FROM source GROUP BY a
当 split 优化被打开后,效果类似于改写 SQL 为:
SELECT a, SUM(cnt) FROM ( SELECT a, COUNT(DISTINCT user_id) as cnt, FROM source GROUP BY a, MOD(HASH_CODE(user_id), 1024) ) T GROUP BY a
3.3 过滤热点 Key(特定场景方案)
如果倾斜由极少数已知的超热点 Key(如爬虫、测试账号)引起,且业务可接受其单独处理或暂时忽略。
实施步骤:
- 使用
WHERE子句过滤掉热点 Key,先快速计算非热点数据的正确结果。 - 对过滤掉的热点 Key 进行单独处理。
- 使用
UNION ALL合并两部分结果。
Flink SQL 示例:
-- 1. 处理非热点数据 SELECT user_id, SUM(amount) AS total_amount FROM orders WHERE user_id != 'super_hot_user_abc' GROUP BY user_id UNION ALL -- 2. 单独处理热点数据 SELECT 'super_hot_user_abc' AS user_id, SUM(amount) AS total_amount FROM orders WHERE user_id = 'super_hot_user_abc'
优点: 简单直接,效果立竿见影。
缺点: 需要事先知晓热点 Key,且业务逻辑可能变复杂。
3.4 优化 GROUP BY 分组
检查 SQL 逻辑,从业务角度避免不必要的倾斜。
- 移除不必要的分组字段: 审视
GROUP BY后的每个字段,移除那些非必须的、高基数的维度字段。 - 采用更粗粒度的分组: 如果业务允许,使用更高层次的分组维度(如将
user_id替换为city,或在时间维度上加大窗口)。
3.5 处理维表 Join 的倾斜
当 JOIN 维表(如 MySQL, HBase)时,如果流表数据存在热点 Key,会导致大量查询集中打向维表的某个分区。
解决方案:
- 开启异步IO: 确保维表 Join 使用
ASYNC模式,避免同步查询阻塞算子。 - 配置维表缓存: 利用
LRU等缓存策略减少对外部数据库的重复查询请求。 - 预处理维表数据: 如果维表本身很大且分布不均,可在数据源端进行分桶或分区设计。
- 在流表侧打散: 类似于两阶段聚合,先对流表的热点 Key 进行打散,再与维表进行 JOIN,最后再合并结果。此法较为复杂,可根据实际情况评估。
4. 总结数据倾斜的处理流程
在上遇到 Flink SQL 数据倾斜时,建议遵循以下决策流程进行排查和解决:
- 确认问题: 通过控制台监控面板确认是否存在反压、算子负载不均等情况,定位发生倾斜的算子。
- 分析热点: 编写抽样 SQL,分析数据分布,识别热点 Key。
- 选择方案:
- 通用场景(聚合): 优先采用 「两阶段聚合」 (3.2) ,并同步开启 「Mini-Batch 优化」 (3.1)。
- 已知热点Key: 如果热点Key极少且可处理,考虑 「过滤热点Key」 (3.3) 方案。
- SQL优化: 始终检查并 「优化 GROUP BY 分组」 (3.4),从源头避免问题。
- 关联查询: 如果是维表
JOIN倾斜,参考 「处理维表 Join 的倾斜」 (3.5) 方案。
- 验证效果: 实施优化后,再次回到控制台监控面板,观察反压是否消失、各 Subtask 负载是否均衡、吞吐量是否提升,以验证解决方案的有效性。